

如果RabbitMQ集群只有一个broker节点,那么该节点的失效将导致整个服务临时性的不可用,并且可能会导致message的丢失(尤其是在非持久化message存储于非持久化queue中的时候)。当然可以将所有的publish的message都设置为持久化的,并且使用持久化的queue,但是这样仍然无法避免由于缓存导致的问题:因为message在发送之后和被写入磁盘并执行fsync之间存在一个虽然短暂但是会产生问题的时间窗。通过publisher的confirm机制能够确保客户端知道哪些message已经存入磁盘,尽管如此,一般不希望遇到因单点故障导致的服务不可用。
如果RabbitMQ集群是由多个broker节点构成的,那么从服务的整体可用性上来讲,该集群对于单点失效是有弹性的,但是同时也需要注意:尽管exchange和binding能够在单点失效问题上幸免于难,但是queue和其上持有的message却不行,这是因为queue及其内容仅仅存储于单个节点之上,所以一个节点的失效表现为其对应的queue不可用。
引入RabbitMQ的镜像队列机制,将queue镜像到cluster中其他的节点之上。在该实现下,如果集群中的一个节点失效了,queue能自动地切换到镜像中的另一个节点以保证服务的可用性。在通常的用法中,针对每一个镜像队列都包含一个master和多个slave,分别对应于不同的节点。slave会准确地按照master执行命令的顺序进行命令执行,故slave与master上维护的状态应该是相同的。除了publish外所有动作都只会向master发送,然后由master将命令执行的结果广播给slave们,故看似从镜像队列中的消费操作实际上是在master上执行的。
一旦完成了选中的slave被提升为master的动作,发送到镜像队列的message将不会再丢失:publish到镜像队列的所有消息总是被直接publish到master和所有的slave之上。这样一旦master失效了,message仍然可以继续发送到其他slave上。
RabbitMQ的镜像队列同时支持publisher confirm和事务两种机制。在事务机制中,只有当前事务在全部镜像queue中执行之后,客户端才会收到Tx.CommitOk的消息。同样的,在publisher confirm机制中,向publisher进行当前message确认的前提是该message被全部镜像所接受了。镜像队列的设置
镜像队列的配置通过添加policy完成,policy添加的命令为:
rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
-p Vhost: 可选参数,针对指定vhost下的queue进行设置
Name: policy的名称
Pattern: queue的匹配模式(正则表达式)
Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode
ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes
all:表示在集群中所有的节点上进行镜像
exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定
ha-params:ha-mode模式需要用到的参数
ha-sync-mode:进行队列中消息的同步方式,有效值为automatic和manual
priority:可选参数,policy的优先级例如,对队列名称以“queue_”开头的所有队列进行镜像,并在集群的两个节点上完成进行,policy的设置命令为:
rabbitmqctl set_policy --priority 0 --apply-to queues mirror_queue "^queue_" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'也可以通过RabbitMQ的web管理界面设置:
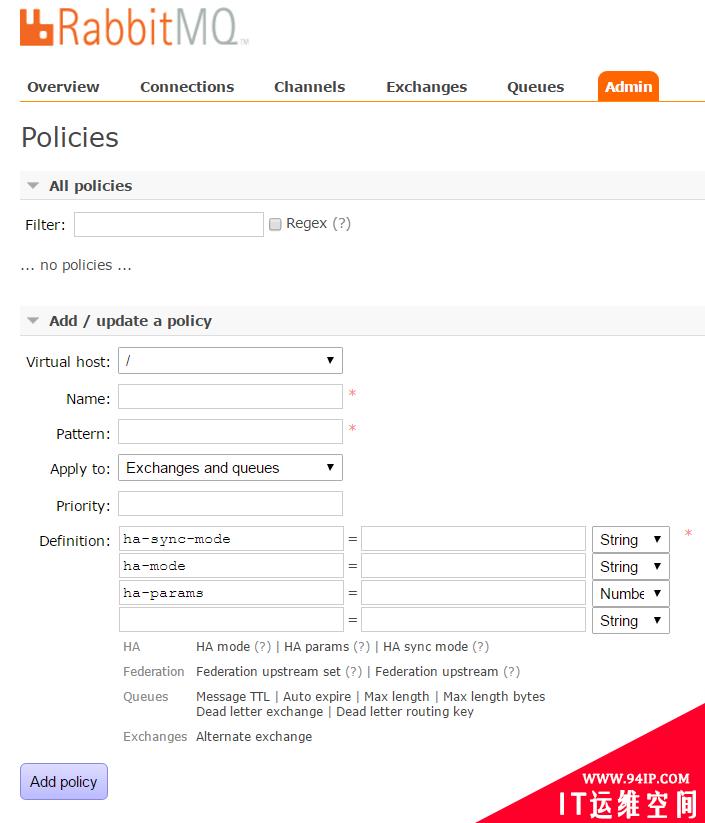
转载请注明:IT运维空间 » linux » RabbitMQ之镜像队列
你可能喜欢:
-

MySQL与JDBC之间的SQL预编译技术讲解
-

详解MySQL Shell 运行 SQL 的两种内置方法
-

mysql错误:java.sql.SQLException: The server time zone value ‘�й���ʱ��’ is unrecognized or represents more than one time zone.
-

ORACLE SQL TUNING ADVISOR 使用方法
-

通用的关于sql注入的绕过技巧(利用mysql的特性)
-

mysql 生成UUID() 即 ORACLE 中的guid()函数
-
执行多条SQL语句,实现数据库事务。(Oracle数据库)
-
Oracle DBA常用SQL
-

MySQL架构优化实战系列4:SQL优化步骤与常用管理命令
-

探究MySQL中SQL查询的成本










发表评论