

大数据,一个似乎已经被媒体传播的过于泛滥的词汇,的的确确又在逐渐影响和改变着我们的生活。也许有人认为大数据在中国仍然只是噱头,但在当前中国互联网领域,大数据以及大数据所催生出来的生产力正在潜移默化地推动业务发展,并为广大中国网民提供更加优秀的服务。优酷土豆作为国内***的视频网站,和国内其他互联网巨头一样,率先看到大数据对公司业务的价值,早在2009年就开始使用Hadoop集群,随着这些年业务迅猛发展,优酷土豆又率先尝试了仍处于大数据前沿领域的Spark/Shark 内存计算框架,很好地解决了机器学习和图计算多次迭代的瓶颈问题,使得公司大数据分析更加完善。
MapReduce之痛
提到大数据,自然不能不提Hadoop。HDFS已然成为大数据公认的存储,而MapReduce作为其搭配的数据处理框架在大数据发展的早期表现出了重大的价值。可由于其设计上的约束MapReduce只适合处理离线计算,其在实时性上仍有较大的不足,随着业务的发展,业界对实时性和准确性有更多的需求,很明显单纯依靠MapReduce框架已经不能满足业务的需求了。
优酷土豆集团大数据团队技术总监卢学裕就表示:“现在我们使用Hadoop处理一些问题诸如迭代式计算,每次对磁盘和网络的开销相当大。尤其每一次迭代计算都将结果要写到磁盘再读回来,另外计算的中间结果还需要三个备份,这其实是浪费。”
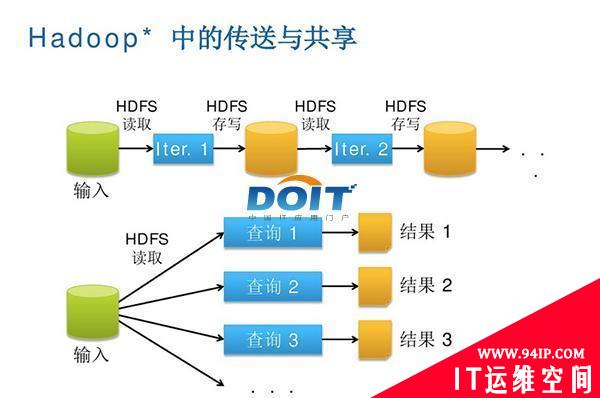
图一:Hadoop中的数据传送与共享,串行方式、复制以及磁盘IO等因素使得Hadoop集群在低延迟、实时计算方面表现有待改进。
据悉,优酷土豆的Hadoop大数据平台是从2009年开始采用,最初只有10多个节点,2012年集群节点达到150个,2013年更是达到300个,每天处理数据量达到200TB。优酷土豆鉴于Hadoop集群已经逐渐胜任不了一些应用,于是决定引入Spark/Shark内存计算框架,以此来满足图计算迭代等的需求。
Spark是一个通用的并行计算框架,由伯克利大学的AMP实验室开发,Spark已经成为继Hadoop之后又一大热门开源项目,目前已经有英特尔等企业加入到该开源项目。
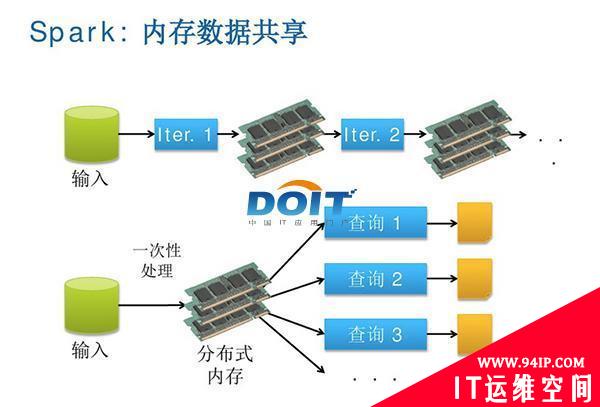
图二:Spark内存计算框架使得数据共享比网络和磁盘快10倍到100倍。
“我们大数据平台对快速需求的响应延时,尤其是在商业智能BI以及产品研究分析等需要多次对大数据做Drill Down与Drill Up时,等待成了效率杀手。” 优酷土豆集团大数据团队技术总监卢学裕表示。
用Spark/Shark完善大数据分析
目前大数据在互联网公司主要应用在广告、报表、推荐系统等业务上。在广告业务方面需要大数据做应用分析、效果分析、定向优化等,在推荐系统方面则需要大数据优化相关排名、个性化推荐以及热点点击分析等。优酷土豆属于典型的互联网公司,目前运用大数据分析平台的主要工作是运营分析、机器学习、广告定向优化、搜索优化等方面。
优酷土豆集团大数据团队技术总监卢学裕表示:“优酷土豆的大数据平台已经用了很多年,突出问题主要包括:***是商业智能BI方面,公司的分析师提交任务之后需要等待很久才得到结果;第二就是大数据量计算,比如进行一些模拟广告投放之时,计算量非常大的同时对效率要求也比较高,用Hadoop消耗资源非常大而且响应比较慢;***就是机器学习和图计算的迭代运算也是需要耗费大量资源且速度很慢。”
因此,面对复杂任务、交互式查询以及流在线处理时,Hadoop与MapReduce并不适用。Spark/Shark这种内存型计算框架则比较适合各种迭代算法和交互式数据分析,可每次将弹性分布式数据集(RDD)操作之后的结果存入内存中,下次操作可直接从内存中读取,省去了大量的磁盘IO,效率也随之大幅提升。优酷土豆集团大数据团队大数据平台架构师傅杰表示:“一些应用场景并不适合在MapReduce里面去处理。通过对比,我们发现Spark性能比MapReduce提升很多。”
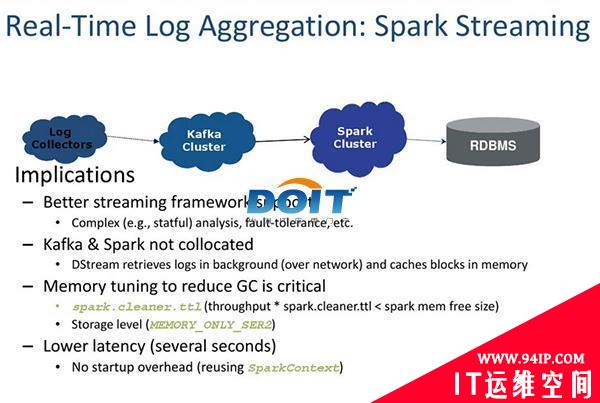
图三:Spark/Shark内存计算框架实时日志聚合处理。
“比如在图计算方面,视频与视频之间存在的相似关系,这就构成了一个图谱,通过图谱来做聚类,再给用户做视频推荐。” 优酷土豆集团大数据团队技术总监卢学裕表示。
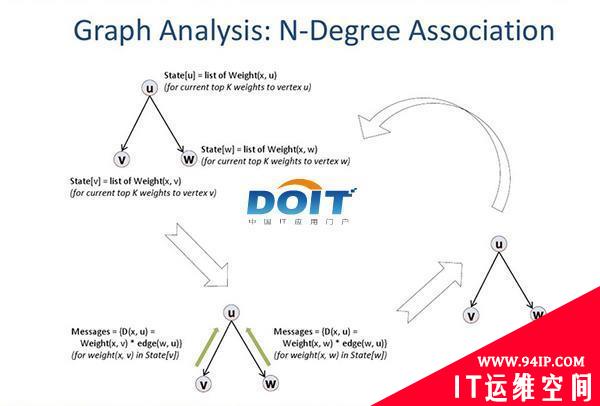
图四:图计算分析N度关联算法示意图。
优酷土豆集团大数据团队技术总监卢学裕表示:“我们进行过图计算方面的测试,在4台节点的Spark集群上用时只有5.6分钟,而同规模的数据量,单机实现需要80多分钟,并且内存吃满,单机无法实现Scale-Out,不能计算更大规模数据。”
“在今天,数据处理要求非常快。比如优酷土豆的一些客户、广告商往往临时就需要看一下投放效果。所以在前端应用不变的情况下,如果能更快的响应市场的需要就变得很有竞争力。市场是瞬息万变的,有一些分析结果也需要快速响应成一个产品,Spark集成到数据平台正能发挥这样的效果。” 优酷土豆集团大数据团队大数据平台架构师傅杰补充道。
据了解,优酷土豆采用Spark/Shark大数据计算框架得到了英特尔公司的帮助,起初优酷土豆并不熟悉Spark以及Scala语言,英特尔帮助优酷土豆设计出具体符合业务需求的解决方案,并协助优酷土豆实现了该方案。此外,英特尔还给优酷土豆的大数据团队进行了Scala语言、Spark的培训等。
“优酷土豆作为国内视频行业***家商用部署Spark/Shark方案的公司,从视频行业的多样化分析角度来看是个非常好的方案。未来,英特尔将会继续与优酷土豆在Spark/Shark进行合作,包括硬件配置的优化以及整体方案的优化等”英特尔(中国)有限公司销售市场部互联网及媒体行业企业客户经理李志辉介绍道。
未来:将Spark/Shark融入到Hadoop 2.0
对于大数据而言,Hadoop已经构建完成了较为完善的生态系统,特别是Hadoop 2.0版本在今年推出之后,改善了诸多缺点。而Spark/Shark计算框架其实与Hadoop并不冲突,Spark现在已经可以直接运行在Yarn的框架之上,成为Hadoop生态系统之中不可或缺的成员。
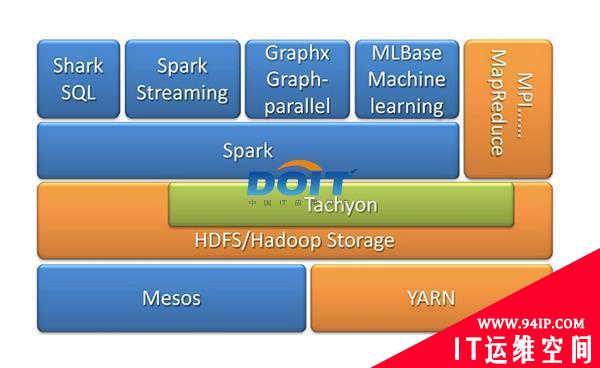
图五:Spark On Yarn 。
优酷土豆集团大数据团队大数据平台架构师傅杰表示:“目前Hadoop 2.0已经发布了release版本,我们已经启动了对Hadoop 2.0的升级预演。这中间还涉及到我们在1.0版本上修改的一些特性需要迁移和验证,我们希望做到在不影响业务的情况下实现平滑升级,预计在明年Q1完成升级。Hadoop 2.0将会是非常强大的,不再仅仅是MapReduce,还能融入Spark,能够让用户可以根据数据处理应用需求的不同来选择合适的计算框架。
转载请注明:IT运维空间 » 运维技术 » 优酷土豆应用Spark完善大数据分析案例
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-
oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-
如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值










发表评论