

Hive和Spark凭借其在处理大规模数据方面的优势大获成功,换句话说,它们是做大数据分析的。本文重点阐述这两种产品的发展史和各种特性,通过对其能力的比较,来说明这两个产品能够解决的各类复杂数据处理问题。

什么是Hive?
Hive是在Hadoop分布式文件系统上运行的开源分布式数据仓库数据库,用于查询和分析大数据。数据以表格的形式存储(就像关系数据库管理系统一样)。数据操作可以使用名为HiveQL的SQL接口来执行。Hive在Hadoop之上引入了SQL功能,使其成为一个水平可扩展的数据库,是DWH环境的绝佳选择。
Hive发展史掠影
Hive(即后来的Apache)最初是由Facebook开发的,开发人员发现他们的数据在几天内出现了从GBs到TBs的指数级增长。当时,Facebook使用Python将数据加载到RDBMS数据库中。因为RDBMS数据库只能垂直伸缩,很快就面临着性能和伸缩性问题。他们需要一个可以水平伸缩并处理大量数据的数据库。Hadoop在当时已经很流行了;不久之后,构建在Hadoop之上的Hive出现了。Hive与RDBMS数据库类似,但不是完整的RDBMS。
为什么选择Hive?
选择Hive的核心原因是它是运行在Hadoop上的SQL接口。此外,它还降低了MapReduce框架的复杂性。Hive帮助企业在HDFS上执行大规模数据分析,使其成为一个水平可伸缩的数据库。它的SQL接口HiveQL使具有RDBMS背景的开发人员能够构建和开发性能、使拓展的数据仓库类型框架。
Hive特性和功能
Hive具有企业级的特性和功能,可以帮助企业构建高效的高端数据仓库解决方案。
其中一些特性包括:
- Hive使用Hadoop作为存储引擎,仅在HDF上运行。
- 专门为数据仓库操作而构建的,不适用于OLTP或OLAP。
- HiveQL作为SQL引擎,能够帮助为数据仓库类型操作构建复杂的SQL查询。Hive可以与其他分布式数据库(如HBase)和NoSQL数据库(如Cassandra)集成。
Hive结构
Hive架构非常简单。它有一个Hive接口,并使用HDFS跨多个服务器存储数据,用于分布式数据处理。
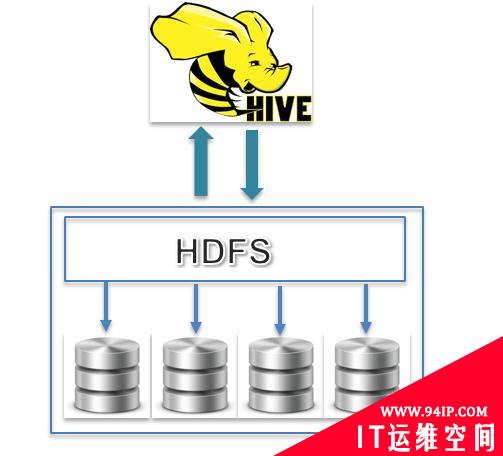
用于数据仓库系统的Hive
Hive是专为数据仓库操作构建的数据库,尤其是那些处理万亿字节或千兆字节数据的数据库。与RDBMS的数据库类似,但不完全相同。如前所述,它是一个水平扩展的数据库,并利用了Hadoop的功能,使其成为一个快速执行的高规模数据库。它可以在数千个节点上运行,并且可以利用商用硬件。这使得Hive成为一款具有高性能和可扩展性的高性价比产品。
Hive集成功能
由于支持ANSI SQL标准,Hive可以与HBase和Cassandra.等数据库集成。这些工具对SQL的支持有限,可以帮助应用程序对更大的数据集执行分析和报告。Hive还可以与Spark、Kafka和Flume等数据流工具集成。
Hive的局限性
Hive是一个纯数据仓库数据库,以表的形式存储数据。因此,它只能处理使用SQL查询读写的结构化数据,不能用于非结构化数据。此外,Hive也不适合OLTP或OLAP操作。
Apache Hive VS Spark:不同目的,同样成功
什么是Spark?
Spark是一个分布式大数据框架,帮助提取和处理大量RDD格式的数据,以便进行分析。简而言之,它不是一个数据库,而是一个框架,可以使用RDD(弹性分布式数据)方法从数据存储区(如Hive、Hadoop和HBase)访问外部分布式数据集。由于Spark在内存中执行复杂的分析,所以运行十分迅速。
什么是Spark Streaming?
Spark Streaming是Spark的一个扩展,它可以从Web源实时流式传输实时数据,以创建各种分析。尽管有其他工具,如Kafka和Flume可以做到这一点,但Spark成为一个很好的选择,执行真正复杂的数据分析是必要的。Spark有自己的SQL引擎,与Kafka和Flume集成时运行良好。
Spark发展史掠影
Spark是作为MapReduce的替代方案而提出的,MapReduce是一种缓慢且资源密集型的编程模型。因为Spark对内存中的数据进行分析,所以不必依赖磁盘空间或使用网络带宽。
为什么选择Spark?
Spark的核心优势在于它能够执行复杂的内存分析和高达千兆字节的数据流大小,使其比MapReduce更高效、更快。Spark可以从Hadoop上运行的任何数据存储中提取数据,并在内存中并行执行复杂的分析。此功能减少了磁盘输入/输出和网络争用,将其速度提高了十倍甚至一百倍。另外,Spark中的数据分析框架还可以使用Java、Scala、Python、R甚至是SQL来构建。
Spark架构
Spark体系结构可以根据需求而变化。通常,Spark体系结构包括Spark流、Spark SQL、机器学习库、图形处理、Spark核心引擎和数据存储(如HDFS、MongoDB和Cassandra)。
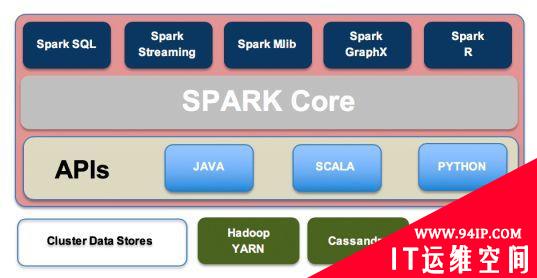
Spark特性和功能
- 闪电般快速的分析
Spark从Hadoop中提取数据并在内存中执行分析。数据被并行地以块的形式拉入内存。然后,将最终数据集传送到目的地。数据集也可以驻留在内存中,知道被使用。
- Spark Streaming
Spark Streaming是Spark的一个扩展,它可以从大量使用的web源实时传输大量数据。由于Spark具有执行高级分析的能力,因此与Kafka和Flume等其他数据流工具相比,显得尤为突出。
- 支持各种应用编程接口
Spark支持不同的编程语言,如在大数据和数据分析领域非常流行的Java、Python和Scala。这使得数据分析框架可以用任何一种语言编写。
- 海量数据处理能力
如前所述,高级数据分析通常需要在海量数据集上执行。在Spark出现之前,这些分析是使用MapReduce方法进行的。Spark不仅支持MapReduce,还支持基于SQL的数据提取。Spark可以为需要对大型数据集执行数据提取的应用程序进行更快的分析。
- 数据存储和工具集成
Spark可以与运行在Hadoop上的各种数据存储(如Hive和HBase)集成。还可以从像MongoDB这样的NoSQL数据库中提取数据。与在数据库中执行分析的其他应用程序不同,Spark从数据存储中提取数据一次,然后在内存中对提取的数据集执行分析。
Spark的扩展——Spark Streaming可以与Kafka和Flume集成,构建高效高性能的数据管道。
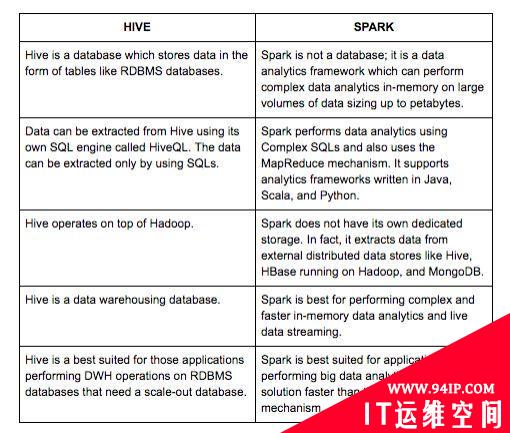
Hive和Spark的区别
Hive和Spark是大数据空间为不同目的而构建的不同产品。Hive是一个分布式数据库,Spark是一个用于数据分析的框架。
特性和功能的差异
结论
Hive和Spark都是大数据世界中非常流行的工具。Hive是使用SQL对大量数据执行数据分析的最佳选择。另一方面,Spark是运行大数据分析的最佳选择,它提供了比MapReduce更快、更现代的替代方案。
转载请注明:IT运维空间 » 运维技术 » Apache Hive VS Spark:不同目的,同样成功
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/1.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值








发表评论