

一根网线引发的血案-赵班长谈运维
–运维的故障哲学
学院IT课程1折起秒杀,12月12日0点万人秒杀准时开启,我是学院高级讲师赵班长,跟大家分享一些个人经验。
“没有经历过故障的运维生涯是不完美的”–路人甲
在我们日常运维工作中,会遭遇各种各样,甚至乱七八糟的故障。而且有些故障刚开始会让你莫名其妙,但结果却让人苦笑不得。这次分享,我想通过阐述个人运维生涯中的其中两个故障作为引子,进而聊聊发生故障之前和之后,我们应该怎么办。
一、我只是插了一个网线,全网中断
环境描述
某年某月某日,机房上架新的服务器。我们的架构是服务器上联两台接入层交换,做端口bonding。每两个机柜都会有接入层交换机,所有接入层交换,双链路上联到汇聚层交换中。然后,汇聚层交换运行MSTP+HSRP协议。架构图如下:我们的操作是要新增一个接入层交换,用来扩展网络规模。

故障现象
当时网络工程师(路人甲)正在准备登录汇聚层交换配置端口Trunk,其他人员配合机房工作人员走线,当接入层交换的上联网线拉到汇聚层交换机的机柜的时候,作为负责人的我(领导不能闲着啊)就问网络工程师插哪里,回复:两台汇聚层交换的23端口。
插线谁不会啊,于是我就先把其中一根接入层交换机的线,插入了23端口。刚过去不到一分钟,QQ群就有人反映打不开网站了,紧接着监控的系统各种报警就来了。
故障处理
1. 我当时的第一反映,赶紧询问网络工程师(路人甲)刚才执行了什么操作,回复刚登录到交换机上还没有操作。可以排除他的误操作。
2. 然后询问其他配合人员是否在线路上有插拔操作,同样回复没有。
3. 登录监控系统,发现报警的是主机无法连接,也就是网络不通,肯定是网络方面的原因。
4. 开始思考在故障之前我们都干了什么?我马上反映过来,我插了一根网线!虽然觉得不可思议,但是根据故障回滚的原则,我立即把网线拔掉,过了一会,故障恢复了。当时的想法就是这个黑锅,我背定了,真心冤啊!
故障排查:
网络工程师(路人甲),登录汇聚层交换后,发现该交换机的23端口之前开启了portfast特性。
故障原因剖析:
Portfast快速端口是一个Cisco Catalyst交换机的一个特性,在STP(Spanning Tree Protocol)中,端口有5个状态:disable、blocking、listening、learning、forwarding,只有forwarding状态,端口才能发送用户数据。
一个端口接入设备后,就会经历blocking->listening->learing->forwarding,每个状态的变化要经历一段时间。这样从pc接上网线,到能发送用户数据,需要进行等待的时间。但如果设置了portfast,那就不需要等待了。
好的,重点来了!portfast只能用在接入层,也就是说交换机的端口是接主机的才能启用portfast,如果是接交换机的就一定不能启用,否则会造成新的环路。(不过,Cisco也提供了BPDU guard特性解决这个问题,但是我们没有启用。)
那么为什么,这个汇聚层交换的23端口会开启这个特性呢?原因是之前这个交换机确实有服务器接入,后来架构拓展了,才只用来接入二层的接入层交换机。
故障经常就是来的很突然,而且肯定会有各种奇葩的原因。甚至有的时候就是让你还债,还是那句话“出来混,终究要还的。”我们继续看下一个故障,直接没有任何关联性。
二、NFS故障,服务全部宕机
环境描述:
某APP后端API,Nginx+Python的架构,本地静态文件由Nginx处理,其他请求转发到后端Python编写的API上,端口9090,接入层负载均衡Nginx+Keepalived。简单的架构图如下:
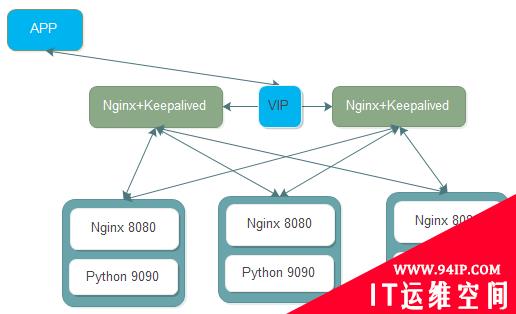
故障现象:
某年某月某日某时突然某后端API节点报警,API http code not 200。(Zabbix监控Nginx代理的某个接口),然后登陆查看所有API服务,发现进程都在。手动测试每个节点的监控URL,发现确实无法访问。
故障处理:
1.查看API的错误日志,并未发现特别异常的报警,并没有新版本发布。
2.手动测试API监听的端口,访问正常。直接访问Nginx代理的8080端口,发现不正常,怀疑Nginx和API直接的通信存在问题。
3.这时有一个特殊情况就是api-nod1节点的访问时是正常的。
4.查看其他节点的Nignx错误日志,发现有大量的请求用户的一个URL失败。例如/user/ID/xxx
5.通过对比发现api-node1和其他节点的唯一不同是api-node1节点运行了NFS,其他节点之前是挂载该节点的NFS。原因是:后端API会生成二维码在各个服务器上,由于数据量不大,所以在api-node1节点启动了NFS,其他所有节点生成的二维码全部写入到这个NFS共享上。查看发现该节点的NFS异常终止。手动启动NFS和重启所有API节点后,服务恢复正常。
故障原因剖析:
通过仔细查看报警才发现,之前api-node1这台虚拟机因为内存跑满自动重启了,但是NFS并没有开机启动(这个是另外一个问题,暂不讨论),因为当时报警太多就没有仔细看每个报警。那么,为什么NFS故障会导致api不能访问呢?应该是某个接口功能不能使用才对。
经过分析,这个功能是用户用来生成二维码的接口,如果用户发现生成失败会不停的重试,那么这些重试的api就会到nginx上,当然肯定都会失败,因为NFS无法读写。但是,我们知道Nginx做后端健康检查默认是无法指定URL的,突然这么多重试的API请求到达Nginx都失败了,那么Nginx根据健康检查策略就会认为后端服务器宕机。然后,就没有然后了。不过,这个故障确实是多种因素叠加的一个效果。
好的,由于篇幅问题,就拿这两个故障,来进行分析,看看我们能学到什么东西。
三、故障发生前,我们能做好什么
1.操作的规范性
第一个故障的背景,其实我们已经制定好了机房上架的操作流程,每个人都知道自己应该干什么,但是并没有按之前的操作计划执行。这是发生这个故障的根本原因,因为如果按流程,网络工程师肯定会发现这个端口的设置并修改。
还有就是非实际操作人员不能盲目介入,这也是操作规范性的一个例子,虽然我只是想帮个忙而已,但是帮了倒忙。
2.建立完善的监控体系
监控体系的重要性不言而喻,不准备多说。但正如第二个故障案例,我们有监控,但是遇到的问题是当报警很多的时候,并没有仔细的查看所有监控,而是把api无法连接当作重点,而忽略了其他报警。所以说,仔细的看报警,以及给故障进行准确的分级非常重要。
3.故障处理流程
在发生故障前要尽可能的建立完善的故障处理流程,先干什么,后干什么,故障的分级、故障的职能性升级都要有确切的流程和文档。保证故障的处理人能够合理的将故障解决,不能解决的及时进行故障升级。
四、发生故障后,我们能做好什么
1.恢复是故障管理的第一要务
ITIL的服务运营有一个故障管理的流程,故障管理的目标是尽可能快地恢复到正常的服务运营,将故障对业务运营的负面影响减小到最低。那么,故障管理的大忌,就是试图快速定位故障原因而忽略了故障处理流程。下面有个小段子,可以帮助你理解:
某电商系统,一次用户系统升级,导致串号,也就是用户A登录后,看到的是用户B的帐号信息。领导问怎么办:
开发人员:老板,给我10分钟,马上修复这个bug。然后开发人员实际使用了8分钟修代码并上线。结果:故障依旧。
开发主管:你这水平不行啊,我来,我只需要5分钟。然后开发主管用了4分钟修代码并上线。结果:故障依旧。
开发经理:你们都闪开,我只需要1分钟。然后开发经理真的1分钟修改代码并上线。结果:故障依旧。
老板:谁能快速的回复这个故障,我们已经故障整整13分钟了!这个时候运维甲奋力的挤进人群:我们有秒级回滚脚本,所有节点回滚上一个版本并启动不到1分钟。结果:1分钟后,故障恢复了。
篇幅问题,这个故障就到这里。我想无论你是老板、经理、开发、测试、运维都应该已经明白了,不做过多的解释了。
2.故障复盘
每一次发生故障后,运维负责人都需要牵头进行故障的复盘。开发、测试、运维要一起审查这次故障,搞明白是哪里出了问题,我们应该怎么避免这类故障的再次发生。俗话说:故障是我们最好的老师。不过,这个老师大家都不会喜欢。当然还需要我们详细做好故障的记录。
3.问题管理
故障复盘的目的和问题管理是相同的。ITIL的服务运营中,问题管理流程的目标是预防问题的产生及由此引发的故障,消除重复出现的故障,并对不能预防的故障尽量降低他对业务的影响。
所以我们可以在故障复盘的时候,要把这个故障转化为问题管理,全面分析故障的原因,务必彻底解决,而且每项工作一定要落实到具体的负责人。
推荐课程:
云计算与自动化运维实践视频课程套餐
http://edu.51cto.com/pack/view/id-298.html
赵舜东
江湖人称赵班长,学院高级讲师,在学院开设10门精品课程。曾负责武警某部指挥自动化架构和运维工作,2008年退役后一直从事互联网运维工作。UnixHot运维社区创始人、《SaltStack入门与实践》作者。
转载请注明:IT运维空间 » 运维技术 » 一根网线引发的血案-赵班长谈运维
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值











发表评论