

背景
小米的Redis使用规模很大,现在有数万个实例,并且每天有百万亿次的访问频率,支撑了几乎所有的产品线和生态链公司。之前所有的Redis都部署在物理机上,也没有做资源隔离,给管理治理带来了很大的困难。我们的运维人员工作压力很大,机器宕机网络抖动导致的Redis节点下线都经常需要人工介入处理。由于没有做CPU的资源隔离,slave节点打RDB或者由于流量突增导致节点QPS升高造成的节点CPU使用率升高,都可能对本集群或其他集群的节点造成影响,导致无法预测的时延增加。
Redis分片方式采用社区的Redis Cluster协议,集群自主分片。Redis Cluster带来了一定的易用性的同时,也提高了应用开发的门槛,应用开发人员需要一定程度上了解Redis Cluster,同时需要使用智能客户端访问Redis Cluster。这些智能客户端配置参数繁多,应用开发人员并无法完全掌握并设置这些参数,踩了很多坑。同时,由于智能客户端需要做分片计算,给应用端的机器也带来了一定的负载。
一、Why K8s
1、资源隔离
当前的Redis Cluster部署在物理机集群上,为了提高资源利用率节约成本,多业务线的Redis集群都是混布的。由于没有做CPU的资源隔离,经常出现某Redis节点CPU使用率过高导致其他Redis集群的节点争抢不到CPU资源引起时延抖动。因为不同的集群混布,这类问题很难快速定位,影响运维效率。K8s容器化部署可以指定 CPU request 和 CPU limit ,在提高资源利用率的同时避免了资源争抢。
2、自动化部署
当前Redis Cluster在物理机上的部署过程十分繁琐,需要通过查看元信息数据库查找有空余资源的机器,手动修改很多配置文件再逐个部署节点,最后使用redis_trib工具创建集群,新集群的初始化工作经常需要一两个小时。
K8s通过StatefulSet部署Redis集群,使用configmap管理配置文件,新集群部署时间只需要几分钟,大大提高了运维效率。
二、How K8s
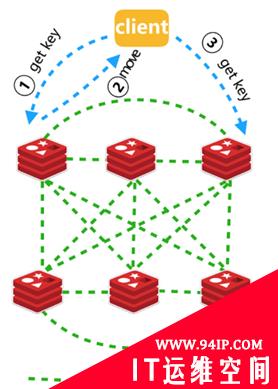
客户端通过LVS的VIP统一接入,通过Redis Proxy转发服务请求到Redis Cluster集群。这里我们引入了Redis Proxy来转发请求。
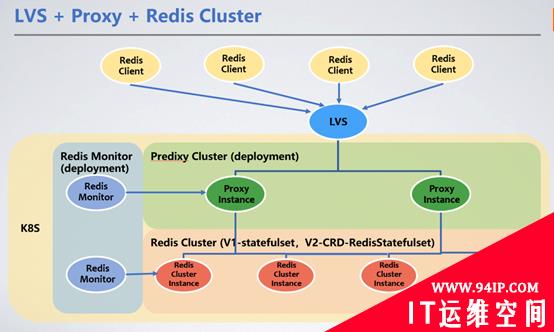
1、Redis Cluster部署方式
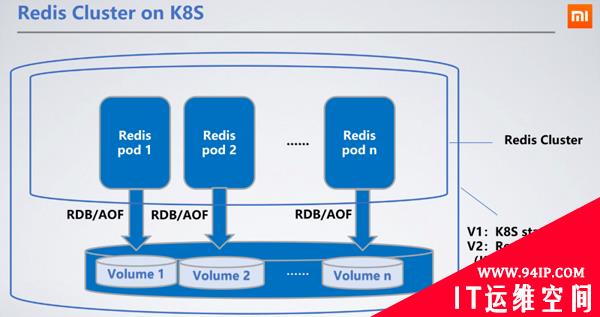
Redis部署为StatefulSet,作为有状态的服务,选择StatefulSet最为合理,可以将节点的RDB/AOF持久化到分布式存储中。当节点重启漂移到其他机器上时,可通过挂载的PVC(PersistentVolumeClaim)拿到原来的RDB/AOF来同步数据。
我们选择的持久化存储PV(PersistentVolume)是Ceph Block Service。Ceph的读写性能低于本地磁盘,会带来100~200ms的读写时延。但由于Redis的RDB/AOF的写出都是异步的,分布式存储带来的读写延迟对服务并没有影响。
2、Proxy选型
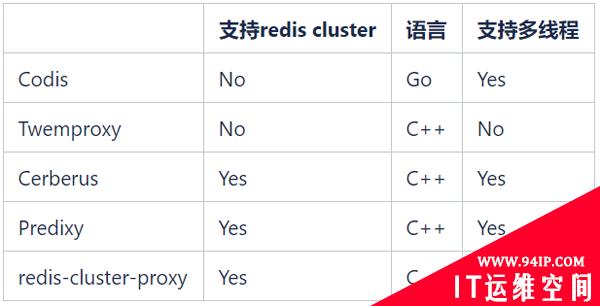
开源的Redis Proxy有很多,常见的开源Redis Proxy如下:
我们希望能够继续使用Redis Cluster来管理Redis集群,所以Codis和Twemproxy不再考虑。redis-cluster-proxy是Redis官方在6.0版本推出的支持Redis Cluster协议的Proxy,但是目前还没有稳定版,暂时也无法大规模应用。
备选就只有Cerberus和Predixy两种。我们在K8s环境上对Cerberus和Predixy进行了性能测试,结果如下:
测试环境
测试工具: redis-benchmark
Proxy CPU: 2 core
Client CPU: 2 core
Redis Cluster: 3 master nodes, 1 CPU per node
测试结果
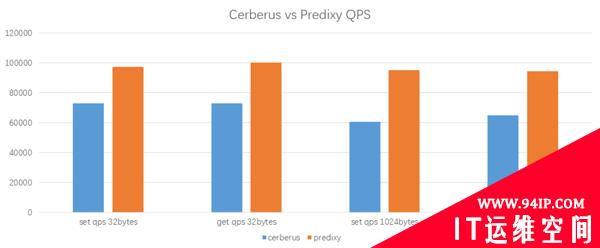
在相同workload和配置下,Predixy的最高QPS要优于Cerberus,时延也比较接近。综合来看,Predixy比Cerberus的性能要高33%~60%,并且数据的key/value越大,Predixy优势越明显,所以最后我们选择了Predixy。
为了适应业务和K8s环境,在上线前我们对Predixy做了大量的改动,增加了很多新的功能,比如动态切换后端Redis Cluster、黑白名单、异常操作审计等。
3、Proxy部署方式
Proxy作为deployment部署,无状态轻量化,通过LB对外提供服务,很容易做到动态扩缩容。同时,我们为Proxy开发了动态切换后端Redis Cluster的功能,可实现在线添加和切换Redis Cluster。
4、Proxy自动扩缩容方式
我们使用K8s原生的HPA(Horizontal Pod Autoscaler)来实现Proxy的动态扩缩容。当Proxy所有pod的平均CPU使用率超过一定阈值时,会自动触发扩容,HPA会将Proxy的replica数加1,之后LVS就会探测到新的Proxy pod并将一部分流量切过去。如果扩容后CPU使用率仍然超过规定的阈值,会继续触发扩容逻辑。但是在扩容成功5分钟内,不论CPU使用率降到多低,都不会触发缩容逻辑,这样就避免了频繁的扩缩容给集群稳定性带来的影响。
HPA可配置集群的最少(MINPODS)和最多(MAXPODS)pod数量,集群负载再低也不会缩容到MINPODS以下数量的pods。建议客户可以根据自己的实际业务情况来决定MINPODS和MAXPODS的值。
三、Why Proxy
1、Redis pod重启可导致IP变化
使用Redis Cluster的Redis客户端,都需要配置集群的部分IP和Port,用于客户端重启时查找Redis Cluster的入口。对于物理机集群部署的Redis节点,即便遇到实例重启或者机器重启,IP和Port都可以保持不变,客户端依然能够找到Redis Cluster的拓扑。但是部署在K8s上的Redis Cluster,pod重启是不保证IP不变的(即便是重启在原来的K8s node上),这样客户端重启时,就可能会找不到Redis Cluster的入口。
通过在客户端和Redis Cluster之间加上Proxy,就对客户端屏蔽了Redis Cluster的信息,Proxy可以动态感知Redis Cluster的拓扑变化,客户端只需要将LVS的IP:Port作为入口,请求转发到Proxy上,即可以像使用单机版Redis一样使用Redis Cluster集群,而不需要Redis智能客户端。
2、Redis处理连接负载高
在6.0版本之前,Redis都是单线程处理大部分任务的。当Redis节点的连接较高时,Redis需要消耗大量的CPU资源处理这些连接,导致时延升高。有了Proxy之后,大量连接都在Proxy上,而Proxy跟Redis实例之间只保持很少的连接,这样降低了Redis的负担,避免了因为连接增加而导致的Redis时延升高。
3、集群迁移切换需要应用重启
在使用过程中,随着业务的增长,Redis集群的数据量会持续增加,当每个节点的数据量过高时,BGSAVE的时间会大大延长,降低集群的可用度。同时QPS的增加也会导致每个节点的CPU使用率增高。这都需要增加扩容集群来解决。目前Redis Cluster的横向扩展能力不是很好,原生的slots搬移方案效率很低。新增节点后,有些客户端比如Lettuce,会因为安全机制无法识别新节点。另外迁移时间也完全无法预估,迁移过程中遇到问题也无法回退。
当前物理机集群的扩容方案是:
- 按需创建新集群;
- 使用同步工具将数据从老集群同步到新集群;
- 确认数据无误后,跟业务沟通,重启服务切换到新集群。
整个过程繁琐而且风险较大,还需要业务重启服务。
有了Proxy层,可以将后端的创建、同步和切换集群对客户端屏蔽掉。新老集群同步完成之后,向Proxy发送命令就可以将连接换到新集群,可以实现对客户端完全无感知的集群扩缩容。
4、数据安全风险
Redis是通过AUTH来实现鉴权操作,客户端直连Redis,密码还是需要在客户端保存。而使用Proxy,客户端只需要通过Proxy的密码来访问Proxy,不需要知道Redis的密码。Proxy还限制了FLUSHDB、CONFIG SET等操作,避免了客户误操作清空数据或修改Redis配置,大大提高了系统的安全性。
同时,Redis并没有提供审计功能。我们在Proxy上增加了高危操作的日志保存功能,可以在不影响整体性能的前提下提供审计能力。
四、Proxy带来的问题
1、多一跳带来的时延
Proxy在客户端和Redis实例之间,客户端访问Redis数据需要先访问Proxy再访问Redis节点,多了一跳,会导致时延增加。经测试,多一跳会增加0.2~0.3ms的时延,不过通常这对业务来说是可以接受的。
2、Pod漂移造成IP变化
Proxy在K8s上是通过deployment部署的,一样会有节点重启导致IP变化的问题。我们K8s的LB方案可以感知到Proxy的IP变化,动态的将LVS的流量切到重启后的Proxy上。
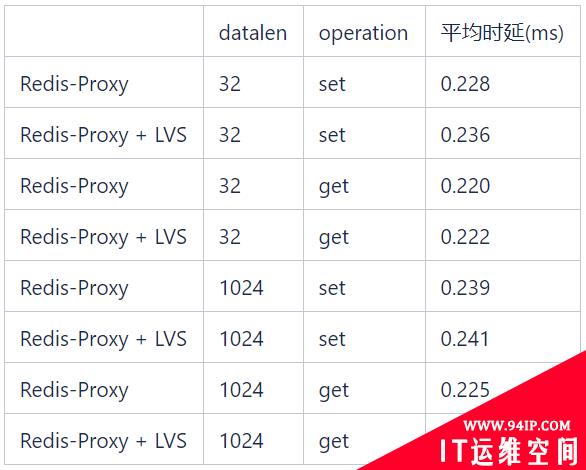
3、LVS带来的时延
LVS也会带来时延,如下表中的测试,不同的数据长度get/set操作,LVS引入的时延小于0.1ms。
五、K8s带来的好处
1、部署方便
通过运维平台调用K8s API部署集群,大大提高了运维效率。
2、解决端口管理问题
目前小米在物理机上部署Redis实例是通过端口来区分的,并且下线的端口不能复用,也就是说整个公司每个Redis实例都有唯一的端口号。目前65535个端口已经用到了40000多,按现在的业务发展速度,将在两年内耗尽端口资源。而通过K8s部署,每一个Redis实例对应的K8s pod都有独立的IP,不存在端口耗尽问题和复杂的管理问题。
3、降低客户使用门槛
对应用来说,只需要使用单机版的非智能客户端连接VIP,降低了使用门槛,避免了繁琐复杂的参数设置。同时由于VIP和端口是固定不变的,应用程序不再需要自己管理Redis Cluster的拓扑。
4、提高客户端性能
使用非智能客户端还可以降低客户端的负载,因为智能客户端需要在客户端对key进行hash以确定将请求发送到哪个Redis节点,在QPS比较高的情况下会消耗客户端机器的CPU资源。当然,为了降低客户端应用迁移的难度,我们让Proxy也支持了智能客户端协议。
5、动态升级和扩缩容
Proxy支持动态添加切换Redis Cluster的功能,这样Redis Cluster的集群升级和扩容切换过程可以做到对业务端完全无感知。例如,业务方使用30个节点的Redis Cluster集群,由于业务量的增加,数据量和QPS都增长的很快,需要将集群规模扩容两倍。如果在原有的物理机上扩容,需要以下过程:
- 协调资源,部署60个节点的新集群;
- 手动配置迁移工具,将当前集群的数据迁移到新集群;
- 验证数据无误后,通知业务方修改Redis Cluster连接池拓扑,重启服务。
虽然Redis Cluster支持在线扩容,但是扩容过程中slots搬移会对线上业务造成影响,同时迁移时间不可控,所以现阶段很少采用这种方式,只有在资源严重不足时才会偶尔使用。
在新的K8s架构下,迁移过程如下:
- 通过API接口一键创建60个节点的新集群;
- 同样通过API接口一键创建集群同步工具,将数据迁移到新集群;
- 验证数据无误后,向Proxy发送命令添加新集群信息并完成切换。
整个过程对业务端完全无感知。
集群升级也很方便:如果业务方能接受一定的延迟毛刺,可以在低峰时通过StatefulSet滚动升级的方式来实现;如果业务对延迟有要求,可以通过创建新集群迁移数据的方式来实现。
6、提高服务稳定性和资源利用率
通过K8s自带的资源隔离能力,实现和其他不同类型应用混部,在提高资源利用率的同时,也能保证服务稳定性。
六、遇到的问题
1、Pod重启导致数据丢失
K8s的pod碰到问题重启时,由于重启速度过快,会在Redis Cluster集群发现并切主前将pod重启。如果pod上的Redis是slave,不会造成什么影响。但如果Redis是master,并且没有AOF,重启后原先内存的数据都被清空,Redis会reload之前存储的RDB文件,但是RDB文件并不是实时的数据。之后slave也会跟着把自己的数据同步成之前的RDB文件中的数据镜像,会造成部分数据丢失。
StatefulSet是有状态服务,部署的pod名是固定格式(StatefulSet名+编号)。我们在初始化Redis Cluster时,将相邻编号的pod设置为主从关系。在重启pod时,通过pod名确定它的slave,在重启pod前向从节点发送cluster failover命令,强制将活着的从节点切主。这样在重启后,该节点会自动以从节点方式加入集群。
LVS映射时延
Proxy的pod是通过LVS实现负载均衡的,LVS对后端IP:Port的映射生效有一定的时延,Proxy节点突然下线会导致部分连接丢失。为减少Proxy运维对业务造成影响,我们在Proxy的deployment模板中增加了如下选项:
lifecycle: preStop: exec: command: -sleep -"171"
对于正常的Proxy pod下线,例如集群缩容、滚动更新Proxy版本以及其它K8s可控的pod下线,在pod下线前会发消息给LVS并等待171秒,这段时间足够LVS将这个pod的流量逐渐切到其他pod上,对业务无感知。
2、K8s StatefulSet无法满足Redis Cluster部署要求
K8s原生的StatefulSet不能完全满足Redis Cluster部署的要求:
1)Redis Cluster不允许同为主备关系的节点部署在同一台机器上。这个很好理解,如果该机器宕机,会导致这个数据分片不可用。
2)Redis Cluster不允许集群超过一半的主节点失效,因为如果超过一半主节点失效,就无法有足够的节点投票来满足gossip协议的要求。因为Redis Cluster的主备是可能随时切换的,我们无法避免同一个机器上的所有节点都是主节点这种情况,所以在部署时不能允许集群中超过1/4的节点部署在同一台机器上。
为了满足上面的要求,原生StatefulSet可以通过 anti-affinity 功能来保证相同集群在同一台机器上只部署一个节点,但是这样机器利用率很低。
因此我们开发了基于StatefulSet的CRD:RedisStatefulSet,会采用多种策略部署Redis节点。同时,还在RedisStatefulSet中加入了一些Redis管理功能。这些我们将会在其他文章中来继续详细探讨。
七、总结
目前集团内部已经有多个业务的数十个Redis集群部署到了K8s上并运行了半年多。得益于K8s的快速部署和故障迁移能力,这些集群的运维工作量比物理机上的Redis集群低很多,稳定性也得到了充分的验证。
在运维过程中我们也遇到了不少问题,文章中提到的很多功能都是根据实际需求提炼出来的。目前还是有很多问题需要在后续逐步解决,以进一步提高资源利用率和服务质量。
1、混布 Vs. 独立部署
物理机的Redis实例是独立部署的,单台物理机上部署的都是Redis实例,这样有利于管理,但是资源利用率并不高。Redis实例使用了CPU、内存和网络IO,但存储空间基本都是浪费的。在K8s上部署Redis实例,其所在的机器上可能也会部署其他任意类型的服务,这样虽然可以提高机器的利用率,但是对于Redis这样的可用性和时延要求都很高的服务来说,如果因为机器内存不足而被驱逐,是不能接受的。这就需要运维人员监控所有部署了Redis实例的机器内存,一旦内存不足,就切主和迁移节点,但这样又增加运维的工作量。
同时,如果混部的其他服务是网络吞吐很高的应用,也可能对Redis服务造成影响。虽然K8s的anti-affinity功能可以将Redis实例有选择地部署到没有这类应用的机器上,但是在机器资源紧张时,还是无法避免这种情况。
2、Redis Cluster管理
Redis Cluster是一个P2P无中心节点的集群架构,依靠gossip协议传播协同自动化修复集群的状态,节点上下线和网络问题都可能导致Redis Cluster的部分节点状态出现问题,例如会在集群拓扑中出现failed或者handshake状态的节点,甚至脑裂。对这种异常状态,我们可以在Redis CRD上增加更多的功能来逐步解决,进一步提高运维效率。
3、审计与安全
Redis本身只提供了Auth密码认证保护功能,没有权限管理,安全性较差。通过Proxy,我们可以通过密码区分客户端类型,管理员和普通用户使用不同的密码登录,可执行的操作权限也不同,这样就可以实现权限管理和操作审计等功能。
4、支持多Redis Cluster
单个Redis Cluster由于gossip协议的限制,横向扩展能力有限,集群规模在300个节点时,节点选主这类拓扑变更的效率就明显降低。同时,由于单个Redis实例的容量不宜过高,单个Redis Cluster也很难支持TB以上的数据规模。通过Proxy,我们可以对key做逻辑分片,这样单个Proxy就可以接入多个Redis Cluster,从客户端的视角来看,就相当于接入了一个能够支持更大数据规模的Redis集群。
最后,像Redis这种有状态服务的容器化部署在国内大厂都还没有非常成熟的经验,小米云平台也是在摸索中逐步完善。目前我们新增集群已经大部分部署在K8s上,更计划在一到两年内将集团内大部分的物理机Redis集群都迁移到K8s上。这样就可以有效地降低运维人员的负担,在不显著增加运维人员的同时维护更多的Redis集群。
转载请注明:IT运维空间 » 运维技术 » 运维:终于不用再背着数万实例的Redis集群了!
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-
oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/1.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值










发表评论