


为什么这么设计(Why’s THE Design)是一系列关于计算机领域中程序设计决策的文章,我们在这个系列的每一篇文章中都会提出一个具体的问题并从不同的角度讨论这种设计的优缺点、对具体实现造成的影响。如果你有想要了解的问题,可以在文章下面留言。
虽然我们经常将 Redis 看做一个纯内存的键值存储系统,但是我们也会用到它的持久化功能,RDB 和 AOF 就是 Redis 为我们提供的两种持久化工具,其中 RDB 就是 Redis 的数据快照,我们在这篇文章想要分析 Redis 为什么在对数据进行快照持久化时会需要使用子进程,而不是将内存中的数据结构直接导出到磁盘上进行存储。
概述
在具体分析今天的问题之前,我们首先需要了解 Redis 的持久化存储机制 RDB 究竟是什么,RDB 会每隔一段时间中对 Redis 服务中当下的数据集进行快照,除了 Redis 的配置文件可以对快照的间隔进行设置之外,Redis 客户端还同时提供两个命令来生成 RDB 存储文件,也就是 SAVE 和 BGSAVE,通过命令的名字我们就能猜出这两个命令的区别。

其中 SAVE 命令在执行时会直接阻塞当前的线程,由于 Redis 是 单线程 的,所以 SAVE 命令会直接阻塞来自客户端的所有其他请求,这在很多时候对于需要提供较强可用性保证的 Redis 服务都是无法接受的。
我们往往需要 BGSAVE 命令在后台生成 Redis 全部数据对应的 RDB 文件,当我们使用 BGSAVE 命令时,Redis 会立刻 fork 出一个子进程,子进程会执行『将内存中的数据以 RDB 格式保存到磁盘中』这一过程,而 Redis 服务在 BGSAVE 工作期间仍然可以处理来自客户端的请求。
rdbSaveBackground 就是用来处理在后台将数据保存到磁盘上的函数:
intrdbSaveBackground(char*filename,rdbSaveInfo*rsi){
pid_tchildpid;
if(hasActiveChildProcess())returnC_ERR;
...
if((childpid=redisFork())==0){
intretval;
/*Child*/
redisSetProcTitle("redis-rdb-bgsave");
retval=rdbSave(filename,rsi);
if(retval==C_OK){
sendChildCOWInfo(CHILD_INFO_TYPE_RDB,"RDB");
}
exitFromChild((retval==C_OK)?0:1);
}else{
/*Parent*/
...
}
...
}
Redis 服务器会在触发 BGSAVE 时调用 redisFork 函数来创建子进程并调用 rdbSave 在子进程中对数据进行持久化,我们在这里虽然省略了函数中的一些内容,但是整体的结构还是非常清晰的,感兴趣的读者可以在点击上面的链接了解整个函数的实现。
使用 fork 的目的最终一定是为了不阻塞主进程来提升 Redis 服务的可用性,但是到了这里我们其实能够发现两个问题:
- 为什么 fork 之后的子进程能够获取父进程内存中的数据?
- fork 函数是否会带来额外的性能开销,这些开销我们怎么样才可以避免?
既然 Redis 选择使用了 fork 的方式来解决快照持久化的问题,那就说明这两个问题已经有了答案,首先 fork 之后的子进程是可以获取父进程内存中的数据的,而 fork 带来的额外性能开销相比阻塞主线程也一定是可以接受的,只有同时具备这两点,Redis 最终才会选择这样的方案。
设计
为了分析上一节提出的两个问题,我们在这里需要了解以下的这些内容,这些内容是 Redis 服务器使用 fork 函数的前提条件,也是最终促使它选择这种实现方式的关键:
- 通过 fork 生成的父子进程会共享包括内存空间在内的资源;
- fork 函数并不会带来明显的性能开销,尤其是对内存进行大量的拷贝,它能通过写时拷贝将拷贝内存这一工作推迟到真正需要的时候;
子进程
在计算机编程领域,尤其是 Unix 和类 Unix 系统中,fork 都是一个进程用于创建自己拷贝的操作,它往往都是被操作系统内核实现的系统调用,也是操作系统在 *nix 系统中创建新进程的主要方法。
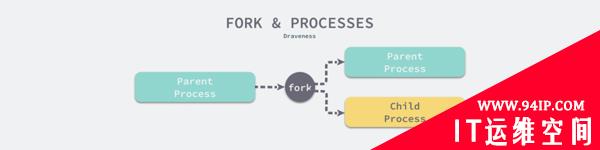
当程序调用了 fork 方法之后,我们就可以通过 fork 的返回值确定父子进程,以此来执行不同的操作:
- fork 函数返回 0 时,意味着当前进程是子进程;
- fork 函数返回非 0 时,意味着当前进程是父进程,返回值是子进程的 pid;
intmain(){ if(fork()==0){ //childprocess }else{ //parentprocess } }在 fork 的 手册 中,我们会发现调用 fork 后的父子进程会运行在不同的内存空间中,当 fork 发生时两者的内存空间有着完全相同的内容,对内存的写入和修改、文件的映射都是独立的,两个进程不会相互影响。
The child process and the parent process run in separate memory spaces. At the time of fork() both memory spaces have the same content. Memory writes, file mappings (mmap(2)), and unmappings (munmap(2)) performed by one of the processes do not affect other.
除此之外,子进程几乎是父进程的完整副本(Exact duplicate),然而这两个进程在以下的一些方面会有较小的区别:
- 子进程用于独立且唯一的进程 ID;
- 子进程的父进程 ID 与父进程 ID 完全相同;
- 子进程不会继承父进程的内存锁;
- 子进程会重新设置进程资源利用率和 CPU 计时器;
- …
最关键的点在于父子进程的内存在 fork 时是完全相同的,在 fork 之后进行写入和修改也不会相互影响,这其实就完美的解决了快照这个场景的问题 —— 只需要某个时间点下内存中的数据,而父进程可以继续对自己的内存进行修改,这既不会被阻塞,也不会影响生成的快照。
写时拷贝
既然父进程和子进程拥有完全相同的内存空间并且两者对内存的写入都不会相互影响,那么是否意味着子进程在 fork 时需要对父进程的内存进行全量的拷贝呢?假设子进程需要对父进程的内存进行拷贝,这对于 Redis 服务来说基本都是灾难性的,尤其是在以下的两个场景中:
- 内存中存储大量的数据,fork 时拷贝内存空间会消耗大量的时间和资源,会导致程序一段时间的不可用;
- Redis 占用了 10G 的内存,而物理机或者虚拟机的资源上限只有 16G,在这时我们就无法对 Redis 中的数据进行持久化,也就是说 Redis 对机器上内存资源的最大利用率不能超过 50%;
如果无法解决上面的两个问题,使用 fork 来生成内存镜像的方式也无法真正落地,不是一个工程中真正可以使用的方法。
就算脱离了 Redis 的场景,fork 时全量拷贝内存也是难以接受的,假设我们需要在命令行中执行一个命令,我们需要先通过 fork 创建一个新的进程再通过 exec 来执行程序,fork 拷贝的大量内存空间对于子进程来说可能完全没有任何作用的,但是却引入了巨大的额外开销。
写时拷贝(Copy-on-Write)的出现就是为了解决这一问题,就像我们在这一节开头介绍的,写时拷贝的主要作用就是将拷贝推迟到写操作真正发生时,这也就避免了大量无意义的拷贝操作。在一些早期的 *nix 系统上,系统调用 fork 确实会立刻对父进程的内存空间进行复制,但是在今天的多数系统中,fork 并不会立刻触发这一过程:
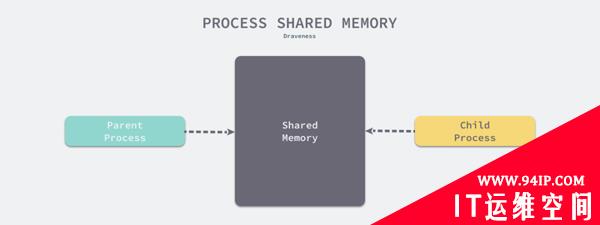
在 fork 函数调用时,父进程和子进程会被 Kernel 分配到不同的虚拟内存空间中,所以在两个进程看来它们访问的是不同的内存:
- 在真正访问虚拟内存空间时,Kernel 会将虚拟内存映射到物理内存上,所以父子进程共享了物理上的内存空间;
- 当父进程或者子进程对共享的内存进行修改时,共享的内存才会以页为单位进行拷贝,父进程会保留原有的物理空间,而子进程会使用拷贝后的新物理空间;
在 Redis 服务中,子进程只会读取共享内存中的数据,它并不会执行任何写操作,只有父进程会在写入时才会触发这一机制,而对于大多数的 Redis 服务或者数据库,写请求往往都是远小于读请求的,所以使用 fork 加上写时拷贝这一机制能够带来非常好的性能,也让 BGSAVE 这一操作的实现变得非常简单。
总结
Redis 实现后台快照的方式非常巧妙,通过操作系统提供的 fork 和写时拷贝的特性轻而易举的就实现了这个功能,从这里我们就能看出作者对于操作系统知识的掌握还是非常扎实的,大多人在面对类似的场景时,想到的方法可能就是手动实现类似『写时拷贝』的特性,然而这不仅增加了工作量,还增加了程序出现问题的可能性。
到这里,我们简单总结一下 Redis 为什么在使用 RDB 进行快照时会通过子进程的方式进行实现:
- 通过 fork 创建的子进程能够获得和父进程完全相同的内存空间,父进程对内存的修改对于子进程是不可见的,两者不会相互影响;
- 通过 fork 创建子进程时不会立刻触发大量内存的拷贝,内存在被修改时会以页为单位进行拷贝,这也就避免了大量拷贝内存而带来的性能问题;
上述两个原因中,一个为子进程访问父进程提供了支撑,另一个为减少额外开销做了支持,这两者缺一不可,共同成为了 Redis 使用子进程实现快照持久化的原因。到最后,我们还是来看一些比较开放的相关问题,有兴趣的读者可以仔细思考一下下面的问题:
- Nginx 的主进程会在运行时 fork 一组子进程,这些子进程可以分别处理请求,还有哪些服务会使用这一特性?
- 写时拷贝其实是一个比较常见的机制,在 Redis 之外还有哪里会用到它?
如果对文章中的内容有疑问或者想要了解更多软件工程上一些设计决策背后的原因,可以在博客下面留言,作者会及时回复本文相关的疑问并选择其中合适的主题作为后续的内容。
Reference
- Redis Persistence
- Understanding Redis Background Memory Usage
- FAQ · Redis
- Copy-on-write
- rdbSaveBackground · Redis
- Fork (system call)
- Which file in kernel specifies fork(), vfork()… to use sys_clone() system call
- Trying to understand fork() and Copy-on-Write (COW)
转载请注明:IT运维空间 » 运维技术 » Redis的快照为什么不会阻塞其他请求?
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/1.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值













发表评论