

SSAS中的聚合方式设定:
SSAS一个Cube中的一个度量的聚合方式设置方法:

也就是说,Cube中的聚合方式是针对度量来指定的。
问题:
针对一种特殊的需求,要求先按照时间做平均聚合运算,再根据空间做求和运算。
其实这种说法字面上看起来本身就很矛盾,所以得套到一个具体的场景中。
比如:我有一个数据仓库统计某几个小区的某一时间粒度(这里定义成季度)的住户数量,里面的数据格式大致如下:
2011年1季度,1100,A小区
2011年2季度,1000,A小区
2011年3季度,1100,A小区
2011年4季度,1000,A小区
2011年1季度,1200,B小区
2011年2季度,1200,B小区
2011年3季度,1100,B小区
2011年4季度,1100,B小区
先从时间这个角度来分析数据,A小区在2011年的住户数,很明显应该是取平均值(当然也有取第四季度的值的统计方法,这里只考虑平均值的统计方法),应该是1050,B小区的就应该是1150。
然后再从空间的角度来分析数据,所有小区(这里假定只有A和B)的在2011年的住户数,应该是1050+1150=2200。很明显这是一个汇总算法。
这就是典型的先根据时间做平均运算,再根据空间做汇总运算,而且这里很明显,SSAS默认的聚合方式的指定是无法实现这种统计需求的。
解决方法:
通过计算公式,或者新建命名成员。
首先,建立测试表。
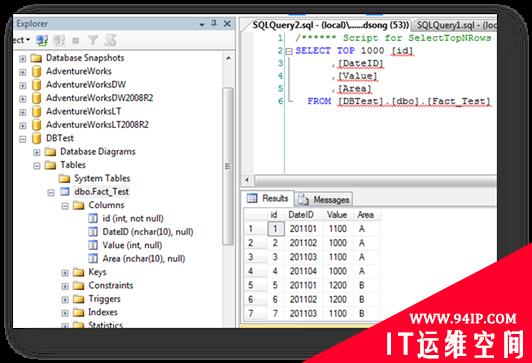
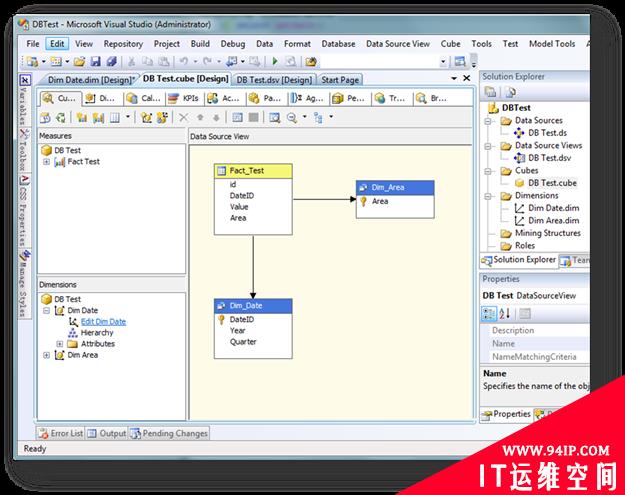
然后,根据这个DW结构建立测试Cube。
其中指标的聚合方式按照默认的Sum.
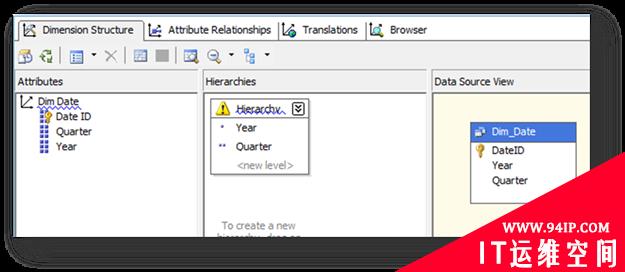
其中时间维度有如下的层次结构:
建立命名成员,表达式关键的部分是那个求叶级节点总和,从而求平均数的公式。
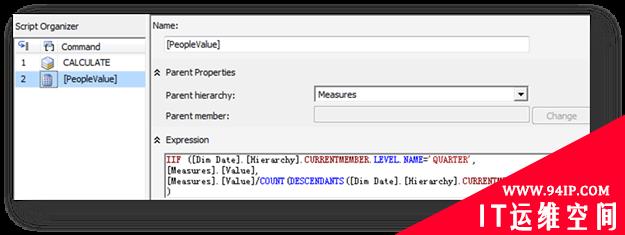
处理浏览
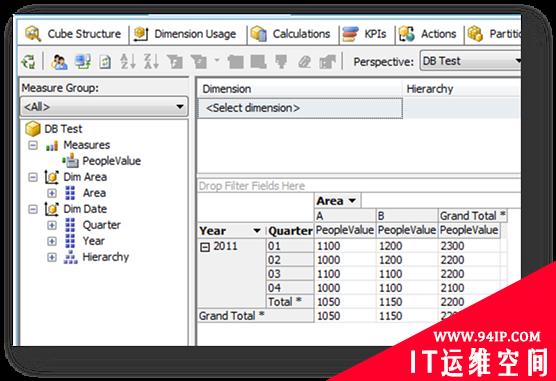
如图:纵向的时间聚合运算是用的平均值运算,而横向的区域聚合运算用的是求和运算。
需要注意的地方:
要留意维度中的null成员。默认是带null成员的,所以需要手动把null处理掉,否则会导致函数算出的数值不准确,因为Count出的数把null也算上了所以分母会加1。
总结:
统计的需求总是很莫名其妙甚至看上去不合逻辑,但实际联系需求却又很合理。就算任何一家BI产品提供商恐怕也很难顾及到所有的需求,不过都会给我们留下变通解决的接口或者方法。
转载请注明:IT运维空间 » 运维技术 » SSAS中不同维度不同聚合的解决
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-
oracle跟踪sql语句
-

oracle 常用select sql语句
-
JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-
如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/5.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值













发表评论