

一、背景与挑战
随着银行数据业务的飞速发展,传统数据仓库也经受着越来越多的挑战,数据量爆发式增涨,底层资源不断扩张,业务对数据的时效性要求提升。同时,新技术不断涌现,技术架构由单一数仓集群转向功能化拆分,即:将单一数据仓库经过拆分,分解成不同的功能定位的仓库集群,以达到提前感知业务变化、快速应对,精准利用资源等目的。
 对数据仓库的运维来说,“一个数据仓库容纳全行业务数据”、“只需维护一个数据仓库”的日子一去不返,传统的“人肉运维”满足不了当前以及未来的运维需求。传统运维工具在某些场景下可以实现对已知问题和故障的快速处置、恢复生产,但终究还是属于被动运维的范畴。当前在数据仓库不断扩展、业务诉求不断提升的大背景下,业务中断越来越不被接受,最终的结果将是被动运维疲于奔命。在数据仓库发展的大背景下保证业务的正常开展、保障业务的连续性将是数据仓库运维的首要职责。
对数据仓库的运维来说,“一个数据仓库容纳全行业务数据”、“只需维护一个数据仓库”的日子一去不返,传统的“人肉运维”满足不了当前以及未来的运维需求。传统运维工具在某些场景下可以实现对已知问题和故障的快速处置、恢复生产,但终究还是属于被动运维的范畴。当前在数据仓库不断扩展、业务诉求不断提升的大背景下,业务中断越来越不被接受,最终的结果将是被动运维疲于奔命。在数据仓库发展的大背景下保证业务的正常开展、保障业务的连续性将是数据仓库运维的首要职责。
二、应对与方案
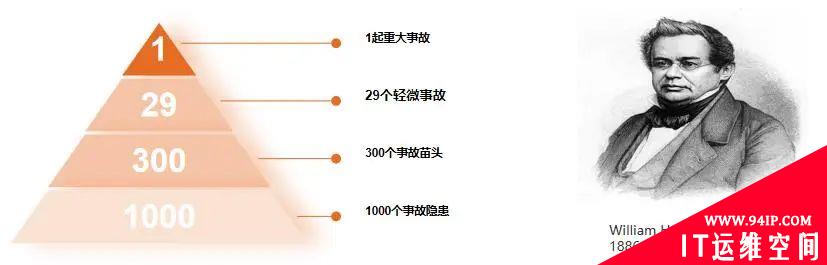
运维是保障业务的正常运行和开展,不是发生问题之后的“堵窟窿”,尽管运维的经历告诉我们:由于各种天灾人祸,“堵窟窿”的事情肯定少不了,但是很大一部分的事故故障都是有先兆的。正如海恩法则所示,一起重大事故的产生,经由29次轻微事故,300个事故苗头以及1000个事故隐患,如果能做到变被动为主动,主动捕捉到事故苗头以及事故隐患,提前发现运维堤坝的薄弱、隐患环节,制定完备的应对方案,就提前进行加固处置,消除隐患。
 伴随银行数据仓库的不断发展,运维的思路也在不断的演进,逐渐由被动运维向主动运维转变,结合既有运维的经验,推动数据仓库领域的主动运维。经过近几年的经验积累,G行建设形成了一套相对成熟的数仓运维方案,即主动运维与应急处置相结合,“主动运维”提前发现问题、消灭隐患,应急处置在问题发生时快速响应、恢复业务,实现对数据业务的保驾护航。
伴随银行数据仓库的不断发展,运维的思路也在不断的演进,逐渐由被动运维向主动运维转变,结合既有运维的经验,推动数据仓库领域的主动运维。经过近几年的经验积累,G行建设形成了一套相对成熟的数仓运维方案,即主动运维与应急处置相结合,“主动运维”提前发现问题、消灭隐患,应急处置在问题发生时快速响应、恢复业务,实现对数据业务的保驾护航。
三、数仓运维落地实践
与传统的业务库不同,数据仓库拥有得天独厚的条件,数据仓库是所有业务数据存储、分析、处理的核心。数据仓库可以通过就地取材,将自身所有的运行数据进行采集、归纳、汇总、入仓,通过数据仓库的数据存储、分析、加工的能力,将数据仓库的各项运行数据进行归集处理,最终形成有效的数据仓库运行数据,将数据仓库运维转向数字化。
G行数据仓库运维探索实践,始终以保障业务连续性,释放人力资源,精准故障定位、快速业务恢复等为目标,立足日常的生产运维需求场景,如容量管理、故障处置等。将应用业务运行、底层资源消耗、数据仓库运行监测等多方面的运行数据进行采集,建立多维数据仓库运行模型,能够精准的记录各个时点,多个维度的运行状态。
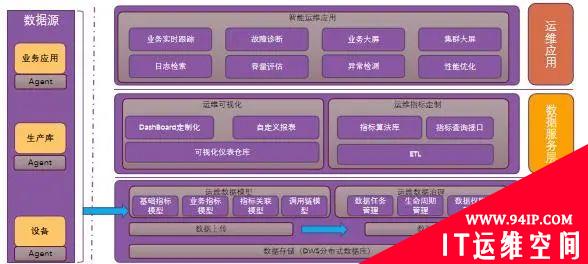 全面的运行数据采集包括底层资源数据、数据仓库系统运行数据、业务运行数据等众多方面。
底层资源数据:既包括CPU、内存、IO、网络,还包括系统层各项进程的资源消耗,尤其是底层资源的横向对比。数据仓库的最大特点就是集中,而集中的最大的故障隐患就是牵一发而动全身,资源节点瓶颈很大的概率就会将整个数据仓库的处理性能拉低。就运维经验而言,除了全局性的性能问题,大概率的性能突降等问题或由“木桶效应”局部故障引起的整体性能下降,而局部故障能从全局底层资源的横向对比或历史资源消耗纵向比对,快速的定位局部,进而快速的处理,恢复业务生产。
数据仓库运行数据:数据仓库运行与常规的数据库运行不同,常规数据库运行可根据QPS、TPS等指标综合判断,而数据参仓库受限于运行的业务场景特点万难梳理一两个指标来判断整理运行状态,而由于处理数据规模及场景的复杂,通常一个常规SQL也将会导致整体的数据仓库运行压力飙升。这也就是数据仓库运行与业务数据库运行的不同之处。
业务运行数据:业务运行数据同样是不可或缺的一部分。不同于单一的业务系统数据库,数据仓库往往立足于复杂的多业务场景,必须适应所有接入的业务。通过对业务运行数据的监测,发现业务场景的变化,能够有效的快速的定位问题。由果寻因,业务发展变化往往是数据仓库运行变化的根因,将业务运行数据采集监控并纳入数据仓库的整体运行监测是必须的。
G行在探索实践过程中,各项数据采集监测告警指标项100多项,其中底层资源采集指标20余项,除常规的CPU、内存、IO等资源更关注可能对数仓运行产生影响明细项,如磁盘坏块数量,负载波动,进程资源消耗,文件系统文件数,内存分页效率,句柄使用量,僵尸、残留进程等明细指标项;数据库运行等采集指标50余项,包括库执行效率,实时访问量、访问时长,阻塞排队,库实例级资源消耗,倾斜SQL,低效节点,Xlog同步、数据页读取效率等;业务相关指标采集10余项,时点业务并发,单项任务时长、累计时长,完成任务占比等;其他采集指标项20多项。随着业务发展,运维场景不断丰富,所需的采集指标项也不断完善,简而言之“与时俱进”。将运行数据终以图形呈现,全面检测,快速识别异常。
全面的运行数据采集包括底层资源数据、数据仓库系统运行数据、业务运行数据等众多方面。
底层资源数据:既包括CPU、内存、IO、网络,还包括系统层各项进程的资源消耗,尤其是底层资源的横向对比。数据仓库的最大特点就是集中,而集中的最大的故障隐患就是牵一发而动全身,资源节点瓶颈很大的概率就会将整个数据仓库的处理性能拉低。就运维经验而言,除了全局性的性能问题,大概率的性能突降等问题或由“木桶效应”局部故障引起的整体性能下降,而局部故障能从全局底层资源的横向对比或历史资源消耗纵向比对,快速的定位局部,进而快速的处理,恢复业务生产。
数据仓库运行数据:数据仓库运行与常规的数据库运行不同,常规数据库运行可根据QPS、TPS等指标综合判断,而数据参仓库受限于运行的业务场景特点万难梳理一两个指标来判断整理运行状态,而由于处理数据规模及场景的复杂,通常一个常规SQL也将会导致整体的数据仓库运行压力飙升。这也就是数据仓库运行与业务数据库运行的不同之处。
业务运行数据:业务运行数据同样是不可或缺的一部分。不同于单一的业务系统数据库,数据仓库往往立足于复杂的多业务场景,必须适应所有接入的业务。通过对业务运行数据的监测,发现业务场景的变化,能够有效的快速的定位问题。由果寻因,业务发展变化往往是数据仓库运行变化的根因,将业务运行数据采集监控并纳入数据仓库的整体运行监测是必须的。
G行在探索实践过程中,各项数据采集监测告警指标项100多项,其中底层资源采集指标20余项,除常规的CPU、内存、IO等资源更关注可能对数仓运行产生影响明细项,如磁盘坏块数量,负载波动,进程资源消耗,文件系统文件数,内存分页效率,句柄使用量,僵尸、残留进程等明细指标项;数据库运行等采集指标50余项,包括库执行效率,实时访问量、访问时长,阻塞排队,库实例级资源消耗,倾斜SQL,低效节点,Xlog同步、数据页读取效率等;业务相关指标采集10余项,时点业务并发,单项任务时长、累计时长,完成任务占比等;其他采集指标项20多项。随着业务发展,运维场景不断丰富,所需的采集指标项也不断完善,简而言之“与时俱进”。将运行数据终以图形呈现,全面检测,快速识别异常。
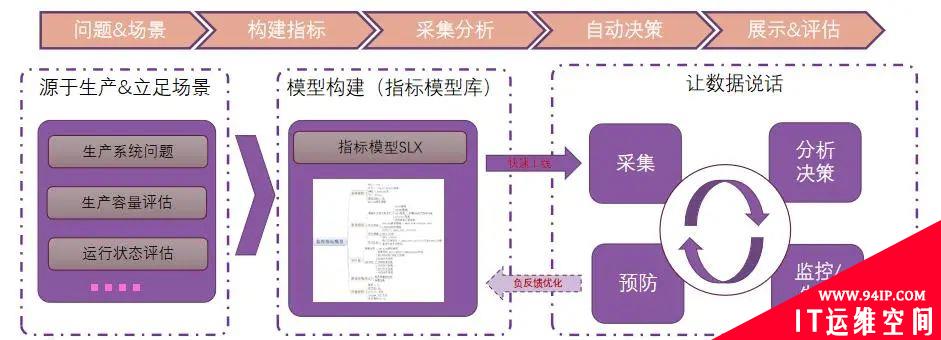
 立足于数据仓库的各类运行数据,根据生产运行场景以及日常运维需求,形成有针对性的监测模型,通过模型来监测发现运行异常,运行变化等问题。同时,在运行模型基础上再通过实际结果的反馈,逐步优化监测模型,进而优化各项监测采集指标,形成一个可行性极高的闭环系统。通过场景模型上线、反馈优化,不断的完善反馈,逐步形成数据仓库的数字化运维平台。
立足于数据仓库的各类运行数据,根据生产运行场景以及日常运维需求,形成有针对性的监测模型,通过模型来监测发现运行异常,运行变化等问题。同时,在运行模型基础上再通过实际结果的反馈,逐步优化监测模型,进而优化各项监测采集指标,形成一个可行性极高的闭环系统。通过场景模型上线、反馈优化,不断的完善反馈,逐步形成数据仓库的数字化运维平台。
 随着运行分析模型的建立和完善,除了在一定程度上实现潜在运行故障的提前预判、突发运行故障的快速定位之外,还有一种重要的运维场景:故障回溯。所以在很多故障发生时,往往不可能有充足的时间分析定位问题,而有些问题又隐藏的很深,一旦发生影响生产的事件,一般采用强制手段恢复生产,强制手段很大程度升就破坏的现场,而全面的运行数据采集保留,能够在一定程度上实现保留现场,为后续的故障分析定位提供运行数据的支撑。
随着运行分析模型的建立和完善,除了在一定程度上实现潜在运行故障的提前预判、突发运行故障的快速定位之外,还有一种重要的运维场景:故障回溯。所以在很多故障发生时,往往不可能有充足的时间分析定位问题,而有些问题又隐藏的很深,一旦发生影响生产的事件,一般采用强制手段恢复生产,强制手段很大程度升就破坏的现场,而全面的运行数据采集保留,能够在一定程度上实现保留现场,为后续的故障分析定位提供运行数据的支撑。
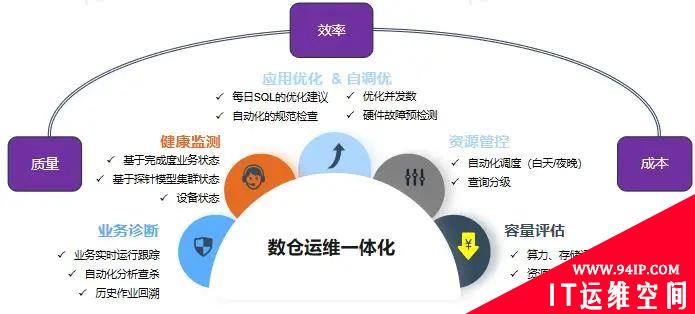 数据仓库运行数据采集的基础建立后,可向上逐步衍生,实现运维功能自动化。G行数据仓库运维平台建设本着建立自动化,标准化,数字化的原则,建立在兼顾运维成本、运维质量和运维效率基础上,包括如下五个方面功能:
业务诊断:通过实施业务运行跟踪监测,实施探查业务运行状态;通过历史故障分析模型对实时提交的业务进行分析,发现模型匹配的异常业务访问进行自动处理;在针对实时业务进行监测的同时,经运行信息做历史留存,为后续故障定位、场景分析、业务回溯做好准备。
健康监测:实时监测应用状态,基础资源使用情况,模拟业务场景不间断进行平台监测,做到实时健康监测,运行出现偏差立即响应。
闭环优化:包括应用业务优化和数仓自优化,应用业务优化通过采集的业务运行信息,进行梳理将低效的业务信息以及优化建议自动推送给相关人员,敦促进行整改,提升业务体验;数仓自优化通过检测访问连接、并发,底层资源使用情况进行动态调整资源分配情况。
容量评估:通过对数仓各个集群的算力、空间、业务运行时效等多个维度进行综合容量评估,每日、每周、每月形成报告推送,能够快捷有效的进行数仓容量监测评估,实现有计划的进行数仓容量管理。
随着G行各项运行指标数据采集的积累沉淀,立足于业务以及运维需求场景,利用每天几十GB的运行数据,根据不同需求场景建立支撑模型,利用日趋完善的数字化、自动化框架,实现快速需求响应。
数据仓库运行数据采集的基础建立后,可向上逐步衍生,实现运维功能自动化。G行数据仓库运维平台建设本着建立自动化,标准化,数字化的原则,建立在兼顾运维成本、运维质量和运维效率基础上,包括如下五个方面功能:
业务诊断:通过实施业务运行跟踪监测,实施探查业务运行状态;通过历史故障分析模型对实时提交的业务进行分析,发现模型匹配的异常业务访问进行自动处理;在针对实时业务进行监测的同时,经运行信息做历史留存,为后续故障定位、场景分析、业务回溯做好准备。
健康监测:实时监测应用状态,基础资源使用情况,模拟业务场景不间断进行平台监测,做到实时健康监测,运行出现偏差立即响应。
闭环优化:包括应用业务优化和数仓自优化,应用业务优化通过采集的业务运行信息,进行梳理将低效的业务信息以及优化建议自动推送给相关人员,敦促进行整改,提升业务体验;数仓自优化通过检测访问连接、并发,底层资源使用情况进行动态调整资源分配情况。
容量评估:通过对数仓各个集群的算力、空间、业务运行时效等多个维度进行综合容量评估,每日、每周、每月形成报告推送,能够快捷有效的进行数仓容量监测评估,实现有计划的进行数仓容量管理。
随着G行各项运行指标数据采集的积累沉淀,立足于业务以及运维需求场景,利用每天几十GB的运行数据,根据不同需求场景建立支撑模型,利用日趋完善的数字化、自动化框架,实现快速需求响应。
四、数据仓库运维展望
我们相信,随着运维技术的不断演进与发展以及运维经验的不断积累、工具化、自动化的深入发展,量变会引起质变,数据仓库运维的智能化也将在不久的将来实现。
转载请注明:IT运维空间 » 运维技术 » 数据仓库运维探索实践
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-
oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/6.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值







发表评论