

最近在思考 MDD 结合 SRE,花了两周的时间打造了小程序端的可观测平台,接下来和大家分享一下整个心历路程。谈谈我的一些启发,顺便谈谈当工程师具备 MDD 意识后,是否能如虎添翼。 事情的背景是这样的,2 月 10 日,好大夫部分小程序用户投诉上传图片失败。整个排查过程有 10 多人参加,排查了三天才有结论。我们来回顾一下当时的情况。
一、一团乱麻,谁人背锅侠?
大家知道上传图片失败问题,一直是个老大难,因为失败的原因太多了。对一般的工程师而言,整个流程可能是一个黑盒模型,缺少一个抓手去分析问题。
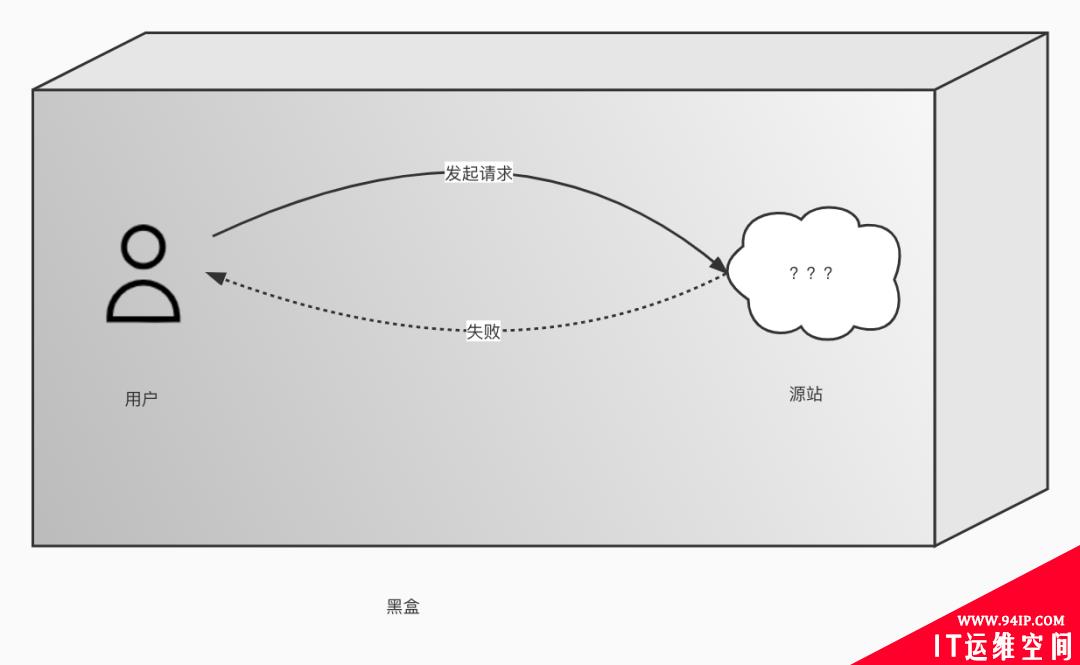 这时候工程师大脑中会有一堆问号。
简单说一下这个问题是如何排查的。
这时候工程师大脑中会有一堆问号。
简单说一下这个问题是如何排查的。
-
怀疑用户网络问题,联系用户切换网络尝试依然失败。加上分析 Kong 日志,发现部分用户重试多次都是失败,切换到好大夫的 APP 能上传成功,前端认为不是用户侧网络问题。
怀疑链路传输问题,我们有多家网络节点运营商,尝试切换链路,甚至直接回源,问题还依然存在。期间通过抓包并和运营商技术一起排查未能明确问题原因,给出的反馈还是用户侧问题。
怀疑小程序版本问题,2 月 9 日有个业务方向上线了小程序,修改的是 http2 相关的,大家很兴奋,时间点也能对上,觉得抓到罪魁祸首了,然后就是紧急上线,用户更新包后问题依然存在,这下打击有点大。
怀疑 Kong 进程处理异常。前面几个关键点都怀疑了,大家谁都说服不了谁的问题。11 日晚上重启 Kong 进程,担心 Kong 进程启动太久,有垃圾没有回收,有点病急乱投医了,试一试总不差。重启后第二天问题依然没有得到缓解。
经过几轮排查,对比最近几天 code=400 的占比趋势,2 月 10 ~ 11 日比之前多了一倍,code=400 的 route_name 基本上也都是小程序侧的上传图片接口。基本上定位是小程序端的问题,越发怀疑微信端是否异常了。联系微信社区,联系微信内部开发,2 月 13 日下午才得到反馈:“2 月 9 日下午微信升级了基础库,灰度了 1%IOS 用户,并于 2 月 11 日回滚,部分用户还有异常需要清理缓存”。
虽然这次问题是找到了,整整三天,包括运维、前端、服务端、系统架构组一共有 10 多人参入了排查。
痛定思痛,有没方式缩短异常定位时长呢?首先我们来看看用户上传会经历哪几个环节。
一次网络请求,中间其实经历了很多环节,细节这里就不展开讨论了,我们来看一下简化后的模型,用户发起请求,到网络节点,再到源站处理,再经过网络节点返回响应给用户。
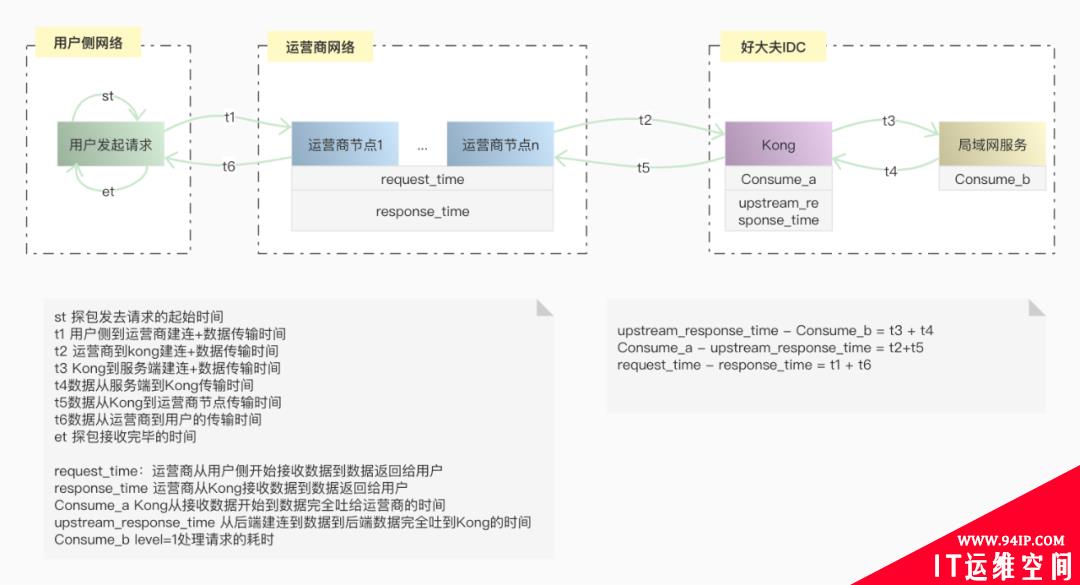 从图中可以看出,上传失败存在几个关键的环节中:用户侧、网络节点、入口网关、后端服务。
从图中可以看出,上传失败存在几个关键的环节中:用户侧、网络节点、入口网关、后端服务。
-
可能是用户侧本地异常,如机器内存不足,小程序闪退。可能是用户网络不稳定,还有可能是用户在上传图片的过程中,中途将小程序切换到后台,重新唤起小程序续传失败。
为了请求的安全和加速,在请求打到源站入口网关前,是先走运营商传输节点,传输节点也对接了多家运营商,传输不稳定或命中防火墙策略也会造成上传失败。
入口网关用的是 kong,如果路由策略配置异常,或者 Kong 节点异常,或者某个 upstream 节点异常都会造成上传失败。
后端图片服务,如果处理能力不足,负载高,进程夯住,或其他异常也会造成上传失败。
经过思考,如何做到普适性呢,就要面临以下几个问题。
-
异常能被有效地观测到吗?
异常定位对经验要求很高,如何减少传承成本?
异常分析有哪些提效的工具链,能平台化吗?
异常千千万万,再加上排练组合,真的能通过数据分析出来吗?
异常分析平台增加了学习成本,会不会增加工程师负担,会质疑研发平台的受益?
深入思考,有点细思极恐,异常定位好难呀,提效异常定位更难!
二、追本溯源,能否提效异常定位?
很多工程师在分析异常的时候,往往聚焦单次问题,一上来就陷入个案分析的细节,耗神耗力,心态都会查崩。
随着网站拓扑的演进,异常定位也越来难,很多公司都在推进 SRE 体系建设,其中对可观测性呼声也越来越高。异常如何被量化,被观测。这其实是一个“工程问题”。
所谓工程问题本质上是数学,需要在一个定义良好的环境里,用定义良好的参数描写一个定义良好的问题。引起网站异常的的原因有各种各样,就像诊断患者一样。统计分析健康的人和病患各项身体基能指标的差异性,从而判断病患程度及探究病因。
结合我的一些日常排障经验,来看一下异常定位这个工程问题。
异常定位需要在一个参照系中进行,通过可视化界面去呈现 SLI 的波动性,而 SLI 的波动性往往是和引起异常的根因相关联。分析不同 SLI 波动振幅差异性大小,从而推断异常的可能性原因。
简单来说,就是给异常进行数学建模,并关联到可观测的 SLI 上。透过 SLI 的表象反查异常原因。说起来比较简单,和医生诊断一样,往往一种病理现象对应了不同的病因,而同一种病因也会有不同的表象。有急性有慢性,还有扩散传递性,一种病变可能引发一系列身体其他的病变,溯源病因可能需要多次会诊。当然经验越丰富,数据越多,模型分析也就越准确。
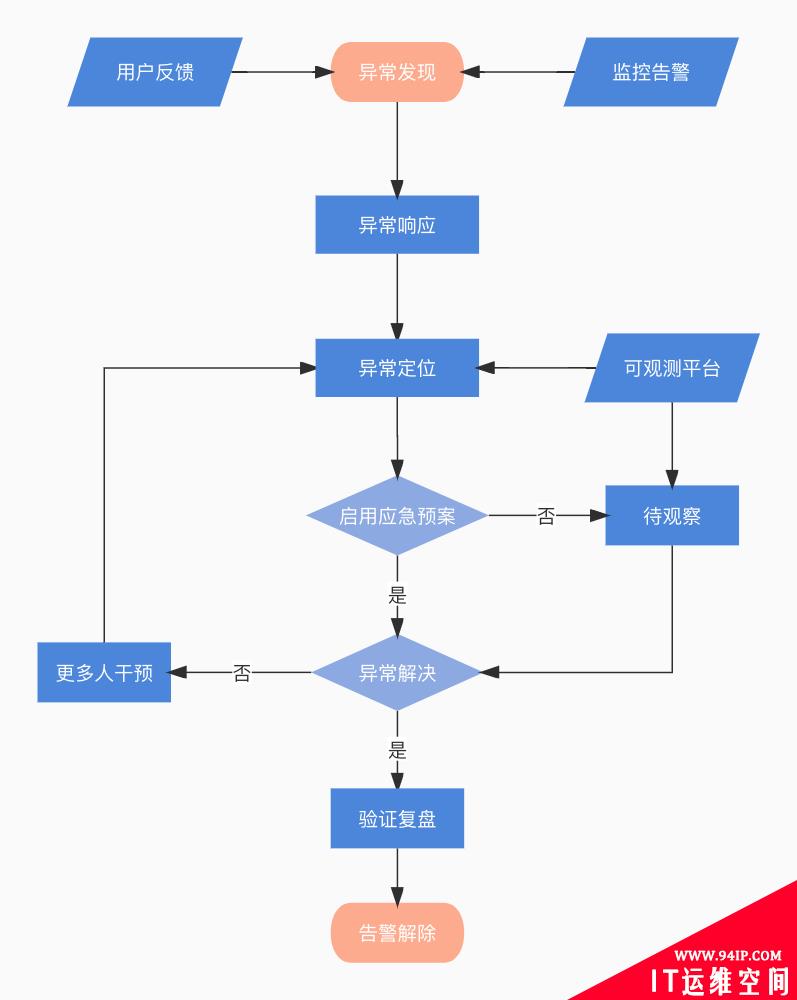 总结一下提效异常定位,首要任务就是需要量化异常,让异常可被观测到。其次就是友好的界面提示一步步引导大家定位问题。
接下来一起探讨一下如何建设小程序上传图片整体链路的可观测性,去尝试建模分析异常定位这个工程问题。
总结一下提效异常定位,首要任务就是需要量化异常,让异常可被观测到。其次就是友好的界面提示一步步引导大家定位问题。
接下来一起探讨一下如何建设小程序上传图片整体链路的可观测性,去尝试建模分析异常定位这个工程问题。
三、破而后立,MDD 劈开黑盒模型
具体到上传图片的场景中,SRE 体系关注各个环节及整体链路的可用性。MDD 思想就是需要我们提炼合适的 SLI,设定 SLO,达成共识,进而围绕这些 SLO 开展工作。
来一起看一下,上传图片各个环节中我们感兴趣的点。
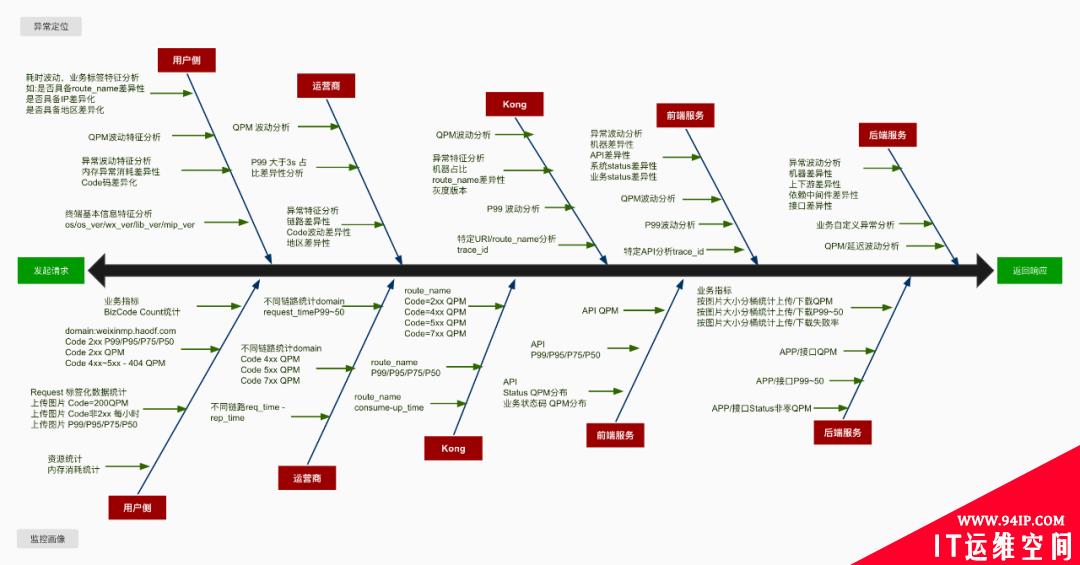 这里总结一些经验:”两点一线,分两面,一面监控画像,一面异常定位“。
为了尽可能的观测各个环节,我们需要梳理一个脉络,如请求的开始到结束,抓住这两点,连成一线,分两面,一面关注长期趋势,一面关注异常分析。
具体提炼 SLI 可参考 Google VALET(Volume、Available、Latency、Error、Ticket)模型。
从图中我们可以看出,评估链路各个环节是否有风险或者有异常,需要一个参考系,长期的指标趋势和经验阈值都是参考的数据源。故而设置 SLO 有两种模式,第一根据经验设置固定阈值,如 QPS 峰值不得大于 10k;第二是设置相对值,如 code=404 环比增加 20%。
有了这些准备工作,提炼了以下 SLI 和 SLO,大家可以参考一下。
这里总结一些经验:”两点一线,分两面,一面监控画像,一面异常定位“。
为了尽可能的观测各个环节,我们需要梳理一个脉络,如请求的开始到结束,抓住这两点,连成一线,分两面,一面关注长期趋势,一面关注异常分析。
具体提炼 SLI 可参考 Google VALET(Volume、Available、Latency、Error、Ticket)模型。
从图中我们可以看出,评估链路各个环节是否有风险或者有异常,需要一个参考系,长期的指标趋势和经验阈值都是参考的数据源。故而设置 SLO 有两种模式,第一根据经验设置固定阈值,如 QPS 峰值不得大于 10k;第二是设置相对值,如 code=404 环比增加 20%。
有了这些准备工作,提炼了以下 SLI 和 SLO,大家可以参考一下。
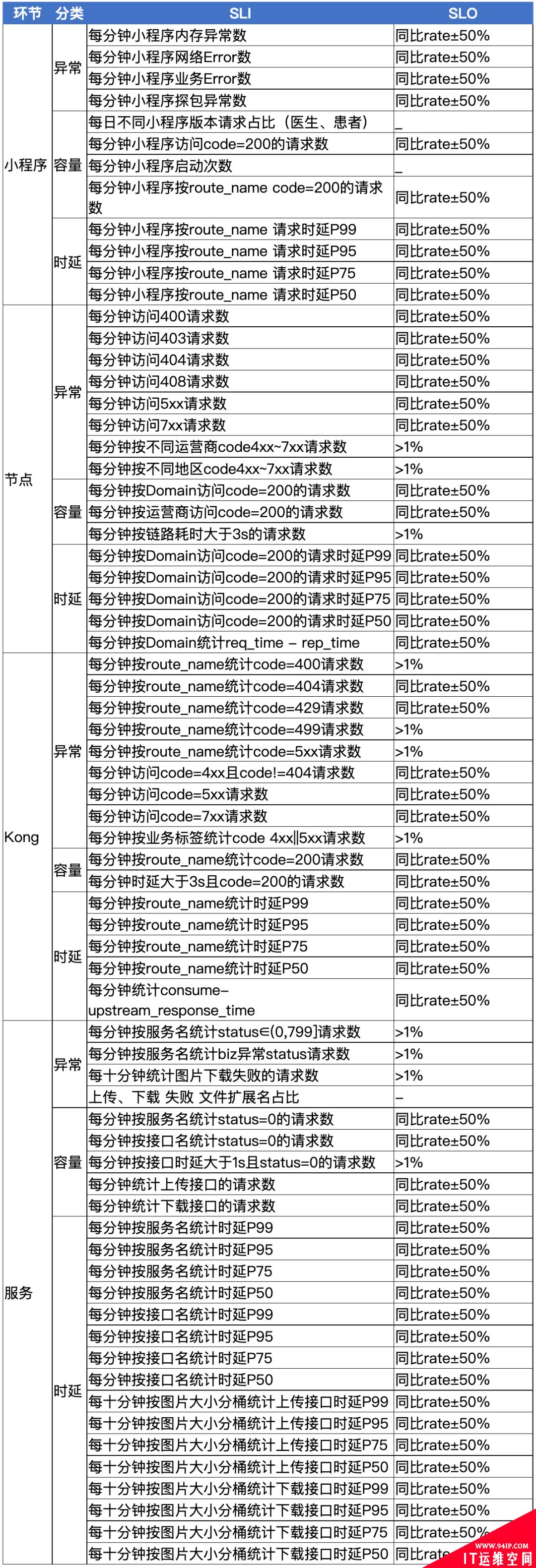 为了异常的可观测性,需要按不同的维度去细分 SLI,这次上传图片异常是由于微信灰度了特定的基础库,改造后需要收集终端相关信息,如设备平台,设备型号,微信版本,微信基础库版本以及小程序版本。
在为上传图片链路建模分析的时候,也一直在考虑能否将这些经验延伸到小程序整体的可观测性中呢?
于是进一步细化了分析维度,按不同的小程序包,统计了不同 code 码、路由、domain 的请求数及时延。这样就能更好地支持下钻,并能迁移到整个小程序异常分析中。接下来一起看一下如何落地改造各个环节以便 SLI 的收集。
为了异常的可观测性,需要按不同的维度去细分 SLI,这次上传图片异常是由于微信灰度了特定的基础库,改造后需要收集终端相关信息,如设备平台,设备型号,微信版本,微信基础库版本以及小程序版本。
在为上传图片链路建模分析的时候,也一直在考虑能否将这些经验延伸到小程序整体的可观测性中呢?
于是进一步细化了分析维度,按不同的小程序包,统计了不同 code 码、路由、domain 的请求数及时延。这样就能更好地支持下钻,并能迁移到整个小程序异常分析中。接下来一起看一下如何落地改造各个环节以便 SLI 的收集。
四、顺势而为,落地整体链路改造
1、用户侧
-
每次小程序启动的时候发起一个探包请求,会上报一下版本信息(平台/版本/微信版本/微信基础库版本/小程序包名/小程序版本),当然为了安全审计不会收集用户隐私相关的信息。探包请求还额外获得了小程序启动频次的粗略统计数据。
通过 hash 算法生成版本信息的指纹 hash_key,后续的用户请求 url 和 http header 中都携带这个 hash_key。
通过 hash_key 关联 kong 日志和版本信息,从而能提炼出终端不同维度的 SLI。
为了将整个链路串联起来,小程序每次请求生成 trace_id,并通过 header 透传下去。
小程序网络不佳的时候,会先将 Error 等日志信息暂存到 LocalStorage 队列中,等有网了再次上报。所有记录日志的地方都会记上 trace_id,方便后续异常定位分析。
2、网络节点
-
新增运营商标识,方便对比分析不同运营商传输的可用性。
收集运营商的日志,存储到 Clickhouse 中,方便后续分析,尽可能让网络传输节点可观测。
3、入口网关
-
按业务类型拆分 route_name,如上传,订单提交等等。
route_name 支持打标签,如业务部门,所属页面等,方便告警监控及识别到的风险通知到具体的业务部门。
插件支持生成 trace_id 或透传已生成的 trace_id,打通 KongLog 和后端服务 TraceLog。
4、后端服务
-
增加日志埋点,分析不同图片尺寸大小的上传下载相关的指标。
定义好不同的 code 码,方便异常定位分析。
5、可观测平台
-
鉴于之前研发了强大的分析器,只用添加分析,告警规则就能满足这次场景需求。
为了节约研发成本,SLI 存储到了 Clickhouse,可视化基于 Grafana 写 SQL 绘制。
新增地理位置分析,将请求 ip 转换成经纬度,方便提炼地区维度的 SLI。
整个小程序日志上报的流程如下:
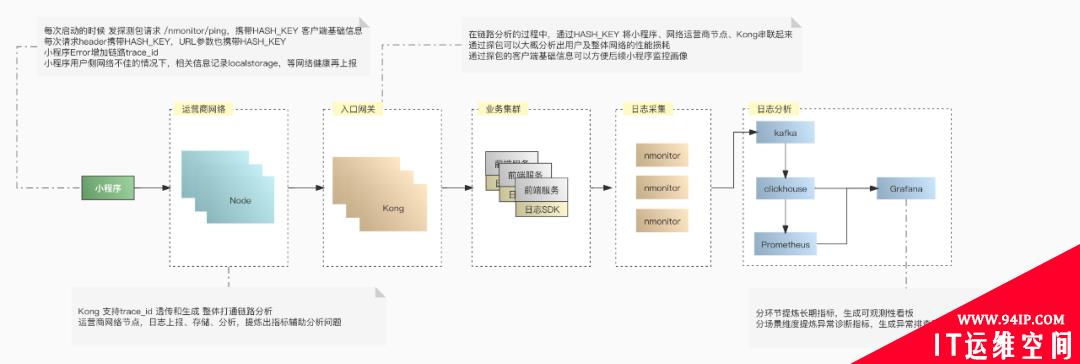 在改造的过程中也遇到了不少问题。
在改造的过程中也遇到了不少问题。
-
控制 Error 信息大小。单条信息过大会导致 Flume 收集异常,重复收集获丢失日志。
采样上报,控制频次。一般异常发生可能会产生连锁反应,瞬时产生大量日志,需要避免频繁上报导致用户带宽的消耗。
降噪处理。如腾讯周期性安全扫描可能会产生一些干扰异常,如 499 等,会影响用户维度 SLI 的准确性,需要识别这些干扰进行降噪处理。
提升分析性能,简化 SQL,很多分析需要连表查询,数据量增大的时候,会存在性能问题。于是添加了大量视图,重建了不同维度的索引表。将数据按分钟维度聚合成 SLI,避免了分析查询原始日志的性能开销。
接下来,一起看一下最终成果。
五、应运而生,建设可观测性平台
在整个改造的过程中,大家也看到了基本上都是一次投入,后续持续受益。整个流程运转起来后,后续就是提炼感兴趣的 SLI,并基于 Grafana 展示即可。
整个可观测性平台是基于 Grafana+Clickhouse+Prometheus 构建的,符合低代码平台研发,只要会写 SQL 就行。
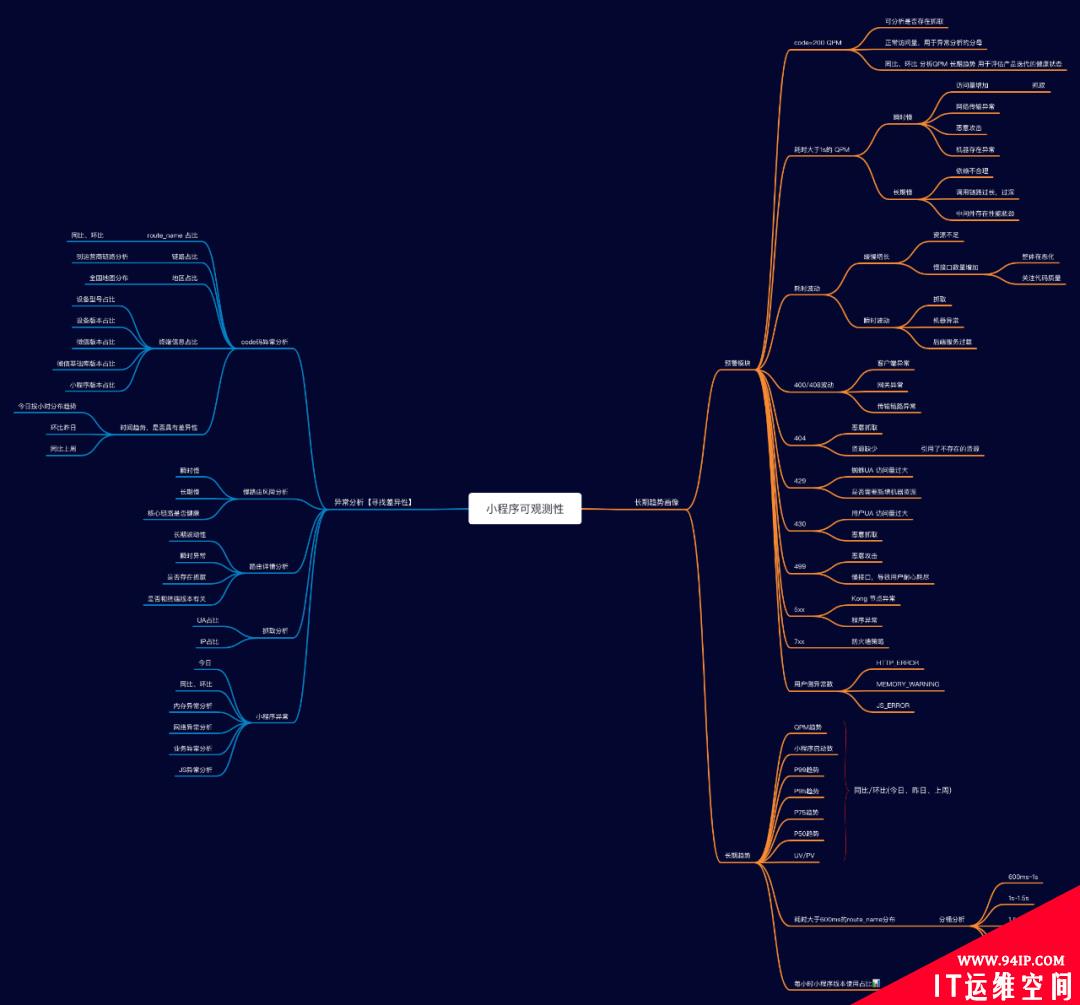 我们一起看一下具体的看板。
我们一起看一下具体的看板。
1、小程序分析首页
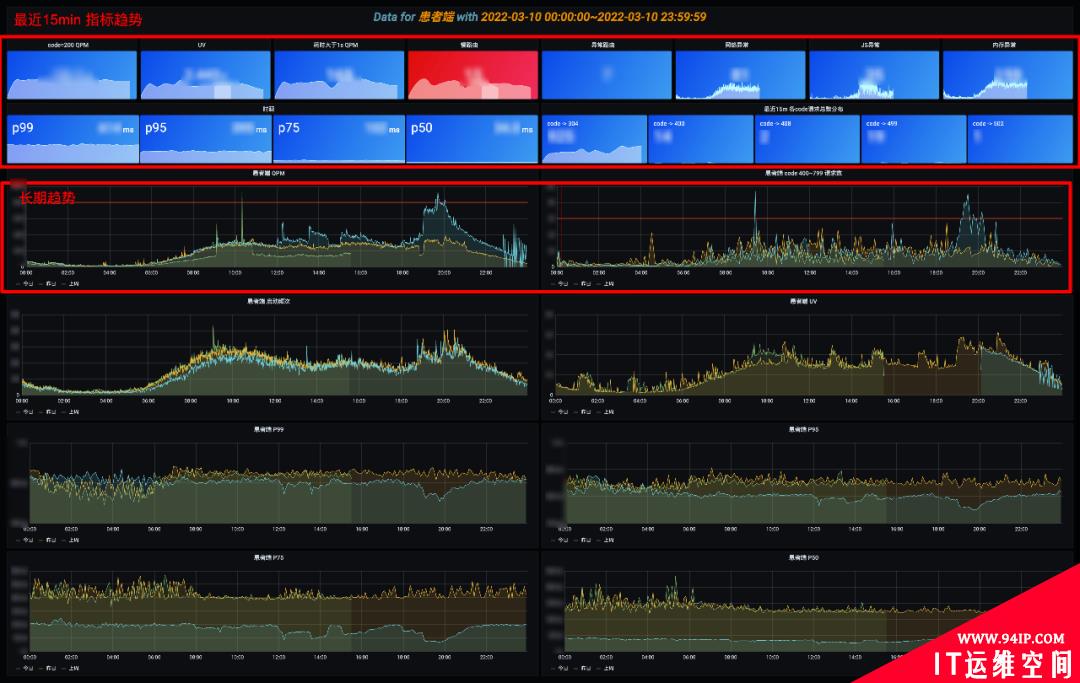 首页看板用于大盘投屏使用的,包括两个部分,上部分是最近 15min 的瞬时数据,大于某个经验阈值会标红显示,下部分是长期趋势,比对同比和环比,各个面板都支持下钻分析。
首页一定要清爽,列出最关心的 SLI,如 QPS/UV、慢路由请求数、异常请求数。根据时延和 ErrorCode 分布,下钻到具体的分析页面。也可以通过分析长期趋势,查看小程序整体的状态,如慢路由风险是否在增加。
首页看板用于大盘投屏使用的,包括两个部分,上部分是最近 15min 的瞬时数据,大于某个经验阈值会标红显示,下部分是长期趋势,比对同比和环比,各个面板都支持下钻分析。
首页一定要清爽,列出最关心的 SLI,如 QPS/UV、慢路由请求数、异常请求数。根据时延和 ErrorCode 分布,下钻到具体的分析页面。也可以通过分析长期趋势,查看小程序整体的状态,如慢路由风险是否在增加。
2、长期趋势分析
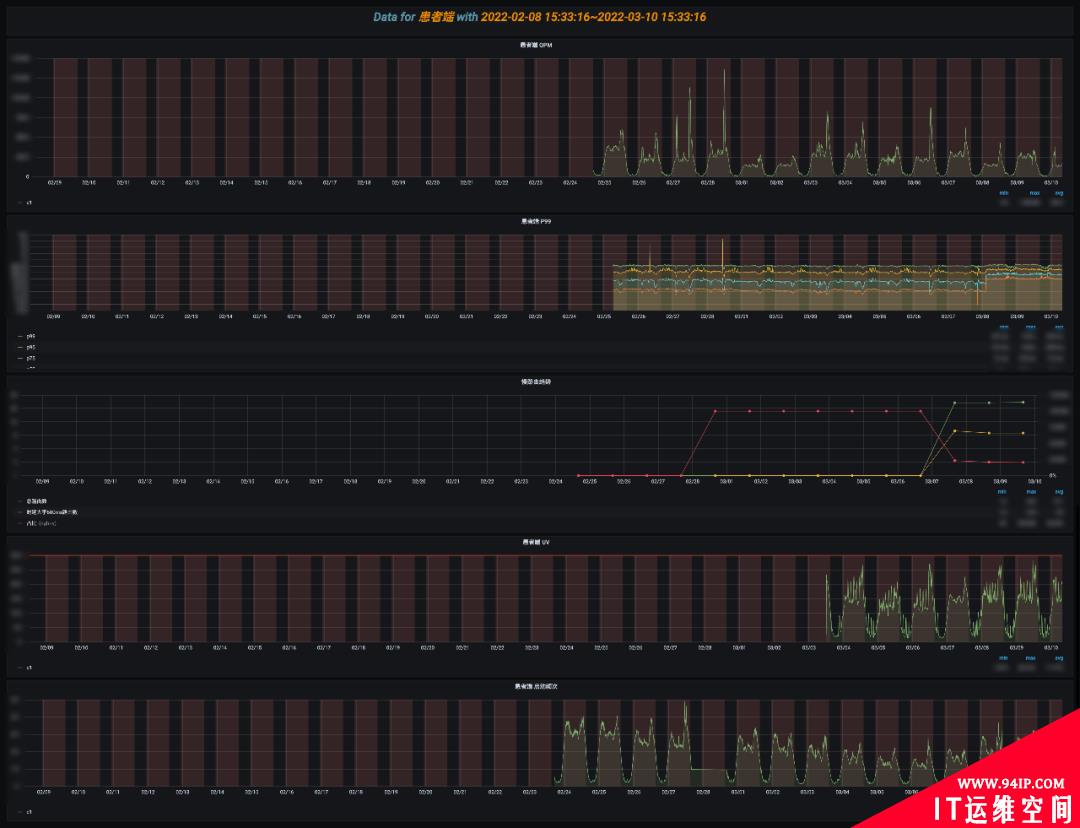 通过首页跳转到长期趋势分析,可以查看最近 1 周/1 月/1 年的宏观趋势,这块可以结合项目上线计划,分析上线节点前后的变化,如 UV 是否有增加,慢路由是否有增多的趋势,还可继续下钻分析具体哪些路由慢了。
通过首页跳转到长期趋势分析,可以查看最近 1 周/1 月/1 年的宏观趋势,这块可以结合项目上线计划,分析上线节点前后的变化,如 UV 是否有增加,慢路由是否有增多的趋势,还可继续下钻分析具体哪些路由慢了。
3、Code 异常分析
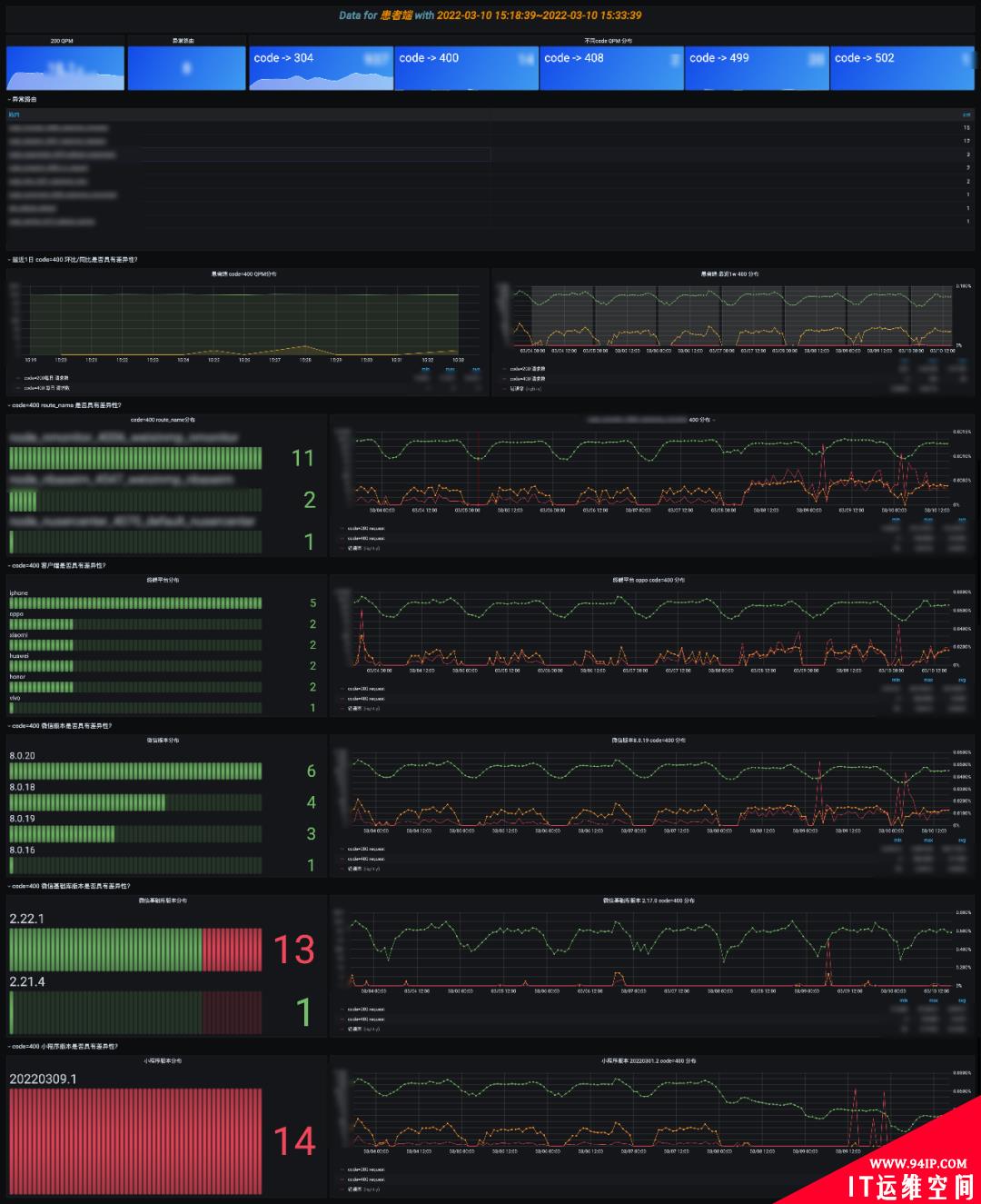 在首页可以观察异常 code 分布,下钻到具体的 code 分析页,这里模拟分析一下 code=400 量增加的场景。
整个过程其实是一个模型匹配问答的模式。
在首页可以观察异常 code 分布,下钻到具体的 code 分析页,这里模拟分析一下 code=400 量增加的场景。
整个过程其实是一个模型匹配问答的模式。
-
是否需要人工介入?假定 SLO 为 code=400 的错误率<0.5%,p = total_400_request / (total_200_request + total_400_request),如 code=200 访问量是 10K,如果这时候 400 访问量达到 500 则需要人工介入排查。
-
同比环比是否具有差异性?分析当日请求判断是否具有突发性,分析一周数据判断是否具有周期性。比如每晚直播访问量就会到峰值,这个点错误率增加了可能是机器负载过高了,从而给排查提供一个方向。
-
是否具有路由差异性?是大面积无异常报错还是特定的路由异常,结合一周趋势,从而给出排查方向。
-
同理分析异常特征是否具有终端平台、微信版本、微信基础库版本、小程序版本差异性?
-
整个差异性分析的过程,其实是判断差异显著程度的过程,这里可能存在认知误区,如 iPhone 异常数比 oppo 大,很可能是 iPhone 总体访问基数大,这个时候其实是看各自长期占比趋势的。
如果判断出来特定 route_name 异常具有显著差异,可能是有突出抓取,或者业务代码异常,或者业务机器负载过高等等,这时候需要下钻分析。可下钻到”NO5.路由详情分析“,”NO6.抓取分析“。
4、慢路由风险分析
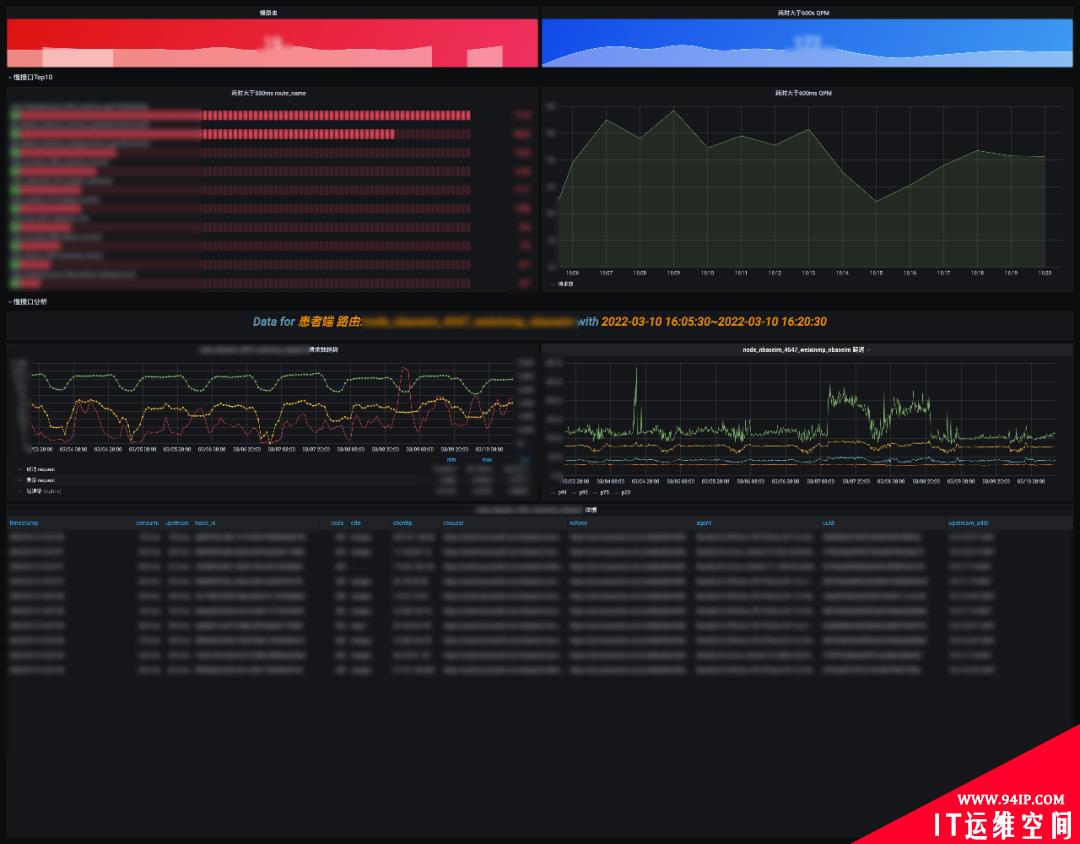 慢,会影响用户体验,随着业务的发展,如果不关注性能问题,整个接口会朝熵增的方向恶化,可能会越来越慢。
一般重点关注 Top10 的慢路由,可以分析是长期慢,还是突发抓取的慢,结合 APM 链路分析,整个请求慢在哪,是依赖中间件慢还是请求路径过长抑或是存在其他慢风险。这部分依然可下钻到”NO5.路由详情分析“,”NO6.抓取分析“。
慢,会影响用户体验,随着业务的发展,如果不关注性能问题,整个接口会朝熵增的方向恶化,可能会越来越慢。
一般重点关注 Top10 的慢路由,可以分析是长期慢,还是突发抓取的慢,结合 APM 链路分析,整个请求慢在哪,是依赖中间件慢还是请求路径过长抑或是存在其他慢风险。这部分依然可下钻到”NO5.路由详情分析“,”NO6.抓取分析“。
5、路由详情分析
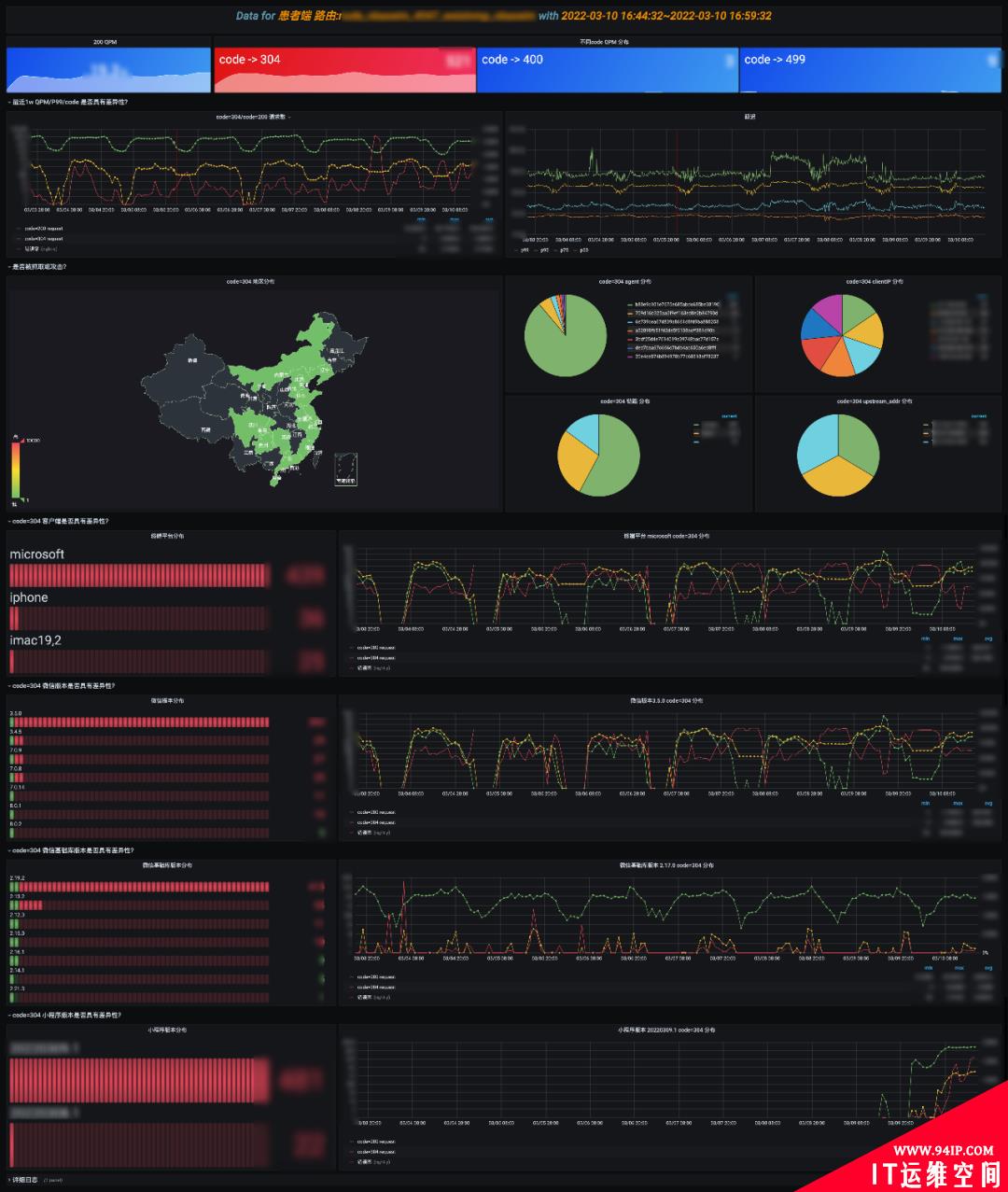 这部分依然在做问答题,主要是围绕给定的 route_name 展开分析的。
这部分依然在做问答题,主要是围绕给定的 route_name 展开分析的。
-
code 分布是否具有显著差异性,如 P99 时延增加了,可能是缓存命中率 code=304 过低了。
-
同比环比是否具有差异性?尤其是周期性存在明显波动,或突发波动的会被优先怀疑。由于是在分析具体的路由,首要怀疑是否有线上变更,如图中 P99 具有显著差异性,是因为当天业务有修改线上配置造成的。结合链路分析慢的问题,最终优化了链路请求解决了这个问题。
-
是否是抓取造成的?另外一个常见的异常是由于蜘蛛突发抓取造成的,为了资源最大利用率,一般不会冗余过多的机器,当蜘蛛突发抓取冷数据的时候可能会造成波动。这部分主要是分析 UA,为了避免 UA 过长带来的分析性能损耗,采用了 hash ua 的方式。结合 ua 占比,ClientIP 占比,评估是否存在抓取的可能,具体可以下钻到”NO6.抓取分析“。
-
是否存在地域差异性?如北京用户异常占比过高,可能是北京链路出现了异常。
-
异常分布运营商节点是否存在显著差异?比如腾讯回源造成缓存穿透。
-
异常分布在后端节点上是否具有显著差异性?从而判断是否存在机器问题。这部分可以继续往机器的维度下钻,分析是 CPU 或其他资源异常。
-
如果以上常见场景都没命中,可以分析客户端相关信息是否具有显著差异性。
6、抓取分析
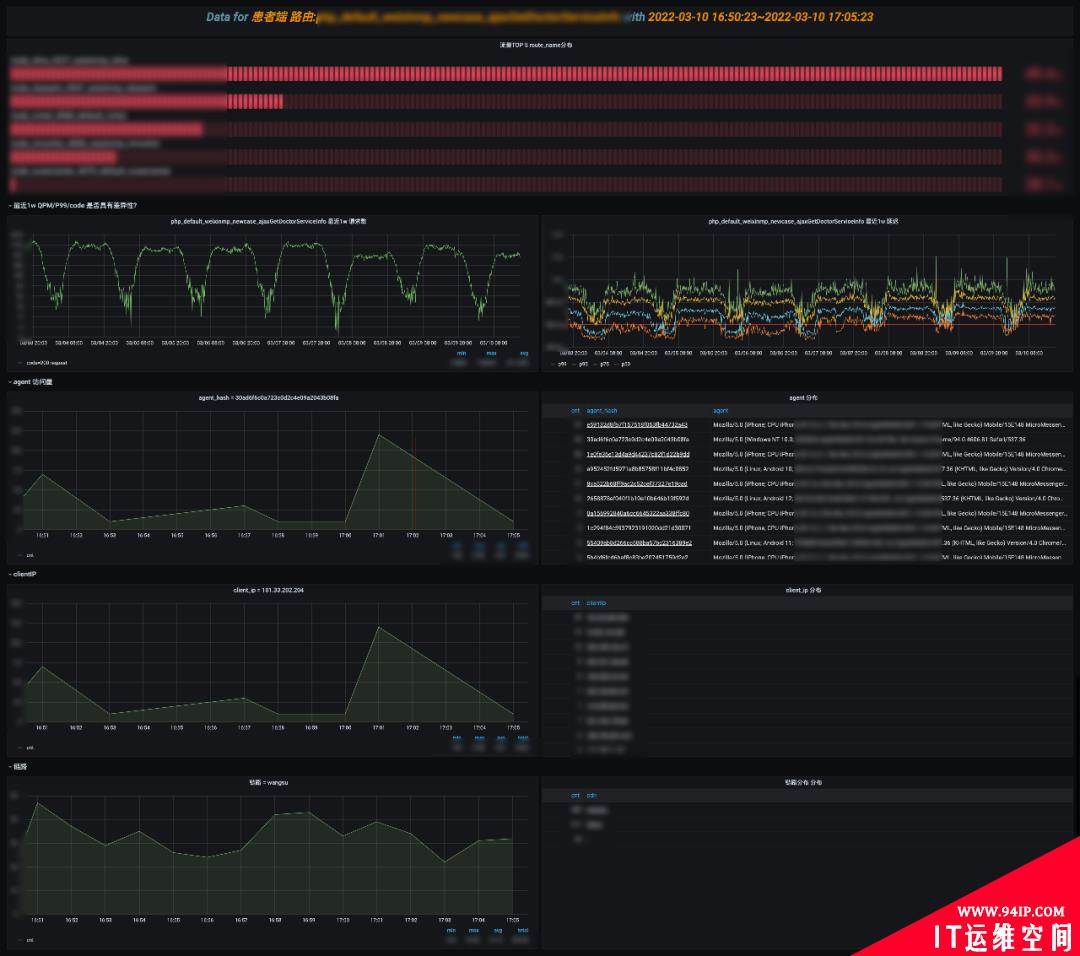 抓取分析就比较简单了,判断 UA 和 ClientIP 访问占比,抓取一般特征是单个 UA 访问量突增,ClientIP 比较集中,结合 QPM 长期趋势,判断是正常访问还是抓取。
抓取分析就比较简单了,判断 UA 和 ClientIP 访问占比,抓取一般特征是单个 UA 访问量突增,ClientIP 比较集中,结合 QPM 长期趋势,判断是正常访问还是抓取。
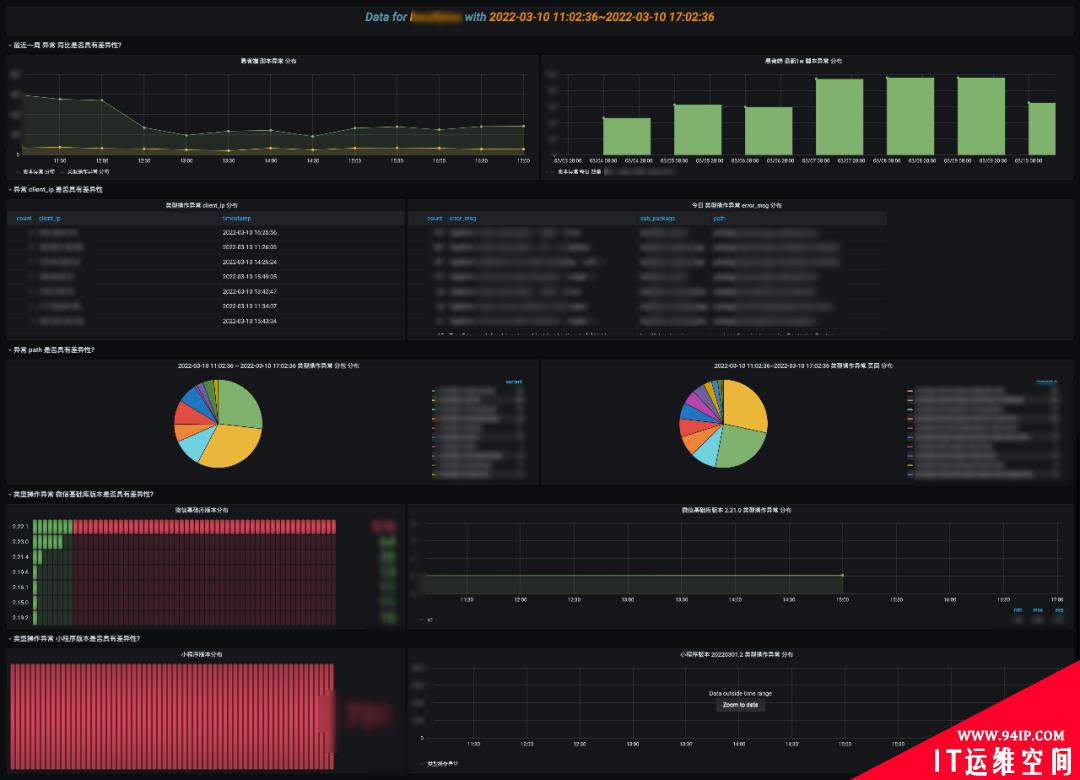
7、程序异常分析概览
为了更好的反映小程序的异常,会收集异常信息进行统计分析,这里和前面类似了,就不展开分析了。
六、道阻且长, 思考从 1 到 n 的演化
做到这,小程序可观测性平台已经从 0 到 1 了,但这只是一个开始,后续要如何演化推进,还面临了很多困难。
1、如何验证?
可观测性平台是否能帮助异常定位呢,线上真实异常可以验证,但太被动了,能否主动模拟异常?如模拟抓取,或单个机器异常。这部分也是今年主要发力的地方,会通过混沌实验平台去辅助故障演练。
2、如何推广?
小程序面向的业务场景茫茫多,如何让工程师转变习惯去适应新的排障工具,也是一个难点。这部分除了培训分享以及持续迭代平台外,可以召集大家攻防演练,在实践中让大家快速掌握新工具,发现平台的不足一起共建。
3、如何横向迁移?
其实这次只是做了小程序端的可观测性,能否延伸到其他各端(触屏/PC/APP)呢?能否推广到中间件,能否推广到其他业务呢?试想一下,业务团队基于 MDD 达成共识后,工程师很多工作就能被量化了,比如优化了几个慢路由,降低了 p99 时延,先于用户发现问题,加速定位问题,是否提升了 UV 等等,都可被观测到。其次工程师可以主动发现一些问题,如上线后接口变慢了,到底慢在了哪里,是否存在慢 SQL 风险等等,就会主动去探寻风险点。
4、如何更快定位异常?
工程问题是需要数学建模,可观测性只是第一步,要想提效不能靠人脑经验分析,如何评估异常的显著差异及关联性,需要选择相应的算法,通过函数拟合建模分析。
5、如何优化用户体验?
数据分析,不同的人会有不同的思路,可观测性反映的现象由于每个人的经验不同,排查思路可能也迥异。另外异常分析定位平台无法穷举所有的异常,就像患者病因溯源一样,很多分析场景具有跳跃性。平台能做的就是尽可能多的给出工程师常用排障按钮,就像超链接一样,让大家按照自己的思路去排查。后续分析这些行为,选择最短路径,固化到程序中,从而达到 AI 智能根因定位。
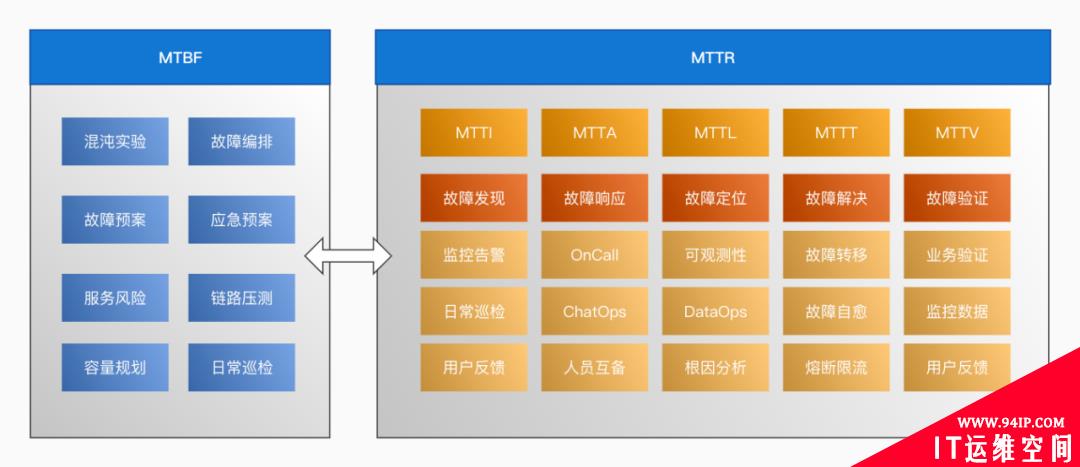
缩短 MTTR 还有很长的路要走,一起共勉,道阻且长, 行则将至,行而不辍, 未来可期。
转载请注明:IT运维空间 » 运维技术 » 小小故障排查三天,早用上可观测性哪来这么多麻烦事!
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-
如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/1.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值













发表评论