

 前文我们介绍了当插入数据的时候会先去添加索引数据,索引构建完成后又是如何去持久化数据的呢?保存的数据又是怎样的格式呢?本节我们将对此进行详细讲解。
前文我们介绍了当插入数据的时候会先去添加索引数据,索引构建完成后又是如何去持久化数据的呢?保存的数据又是怎样的格式呢?本节我们将对此进行详细讲解。
添加索引数据
索引构建完成后会调用AddItems函数将索引添加到Table中去:
// lib/mergeset/table.go
// AddItems 添加指定的 items 到 table 中去
func (tb *Table) AddItems(items [][]byte) error {
if err := tb.rawItems.addItems(tb, items); err != nil {
return fmt.Errorf("cannot insert data into %q: %w", tb.path, err)
}
return nil
}
Table的结构如下所示:
// lib/mergeset/table.go
// Table 代表 mergeset table.
type Table struct {
activeMerges uint64
mergesCount uint64
itemsMerged uint64
assistedMerges uint64
// merge 索引
mergeIdx uint64
// 路径
path string
// flush回调
flushCallback func()
flushCallbackWorkerWG sync.WaitGroup
needFlushCallbackCall uint32
// 在将指定项的整个块刷新到持久存储之前,在合并期间调用的回调
prepareBlock PrepareBlockCallback
// parts 列表
partsLock sync.Mutex
parts []*partWrapper
// rawItems 包含最近添加的尚未转换为 parts 的数据
// 出于性能原因,未在搜索中使用 rawItems
rawItems rawItemsShards
snapshotLock sync.RWMutex
flockF *os.File
stopCh chan struct{}
partMergersWG syncwg.WaitGroup
rawItemsFlusherWG sync.WaitGroup
convertersWG sync.WaitGroup
rawItemsPendingFlushesWG syncwg.WaitGroup
}
一个索引Table就对应着一个 indexDB,也就是数据目录indexdb下面的文件夹:
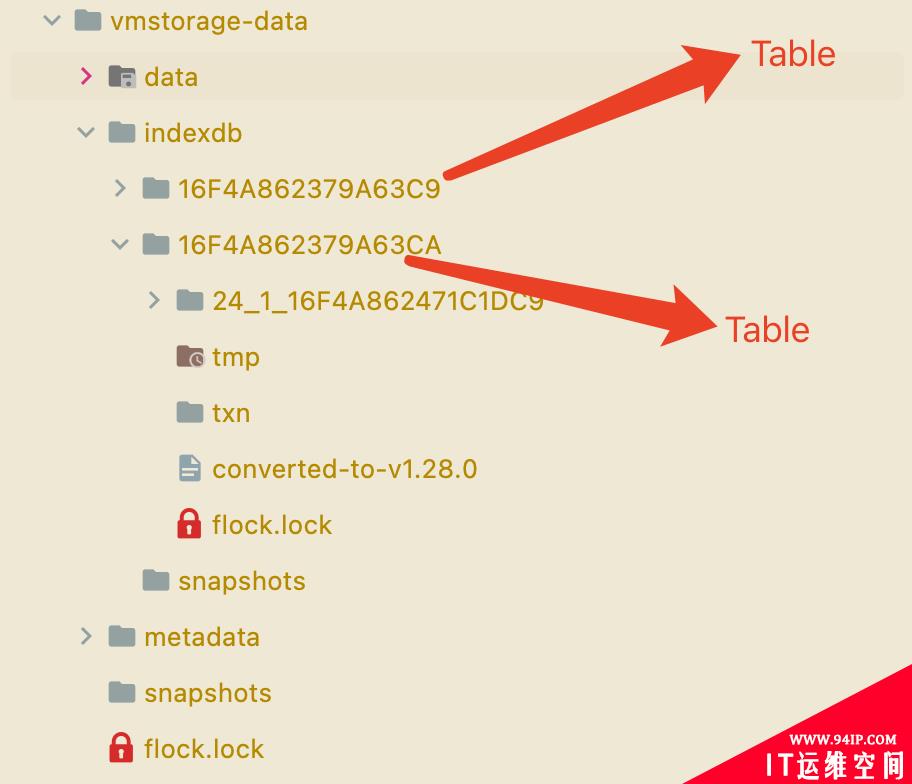 其中核心的是parts和rawItems两个属性。
parts主要是存储 merge 后的 blocks,一个part与文件系统上的一个目录对应,比如上图中的24_1_16F4A862471C1DC9目录就是一个part。
rawItems是用于预处理Items的,是一个rawItemsShards对象。
rawItemsShards结构体定义如下所示:
其中核心的是parts和rawItems两个属性。
parts主要是存储 merge 后的 blocks,一个part与文件系统上的一个目录对应,比如上图中的24_1_16F4A862471C1DC9目录就是一个part。
rawItems是用于预处理Items的,是一个rawItemsShards对象。
rawItemsShards结构体定义如下所示:
// lib/mergeset/table.go
type rawItemsShards struct {
shardIdx uint32
// 在多 cpu 系统上添加 rows 数据时,shards 分片可以减少锁竞争
shards []rawItemsShard
}
// 每个 table 的 rawItems 分片数
var rawItemsShardsPerTable = cgroup.AvailableCPUs()
// 每个分片最大的Block数
const maxBlocksPerShard = 512
// 当在打开Table的时候就会调用该函数进行初始化
func (riss *rawItemsShards) init() {
riss.shards = make([]rawItemsShard, rawItemsShardsPerTable)
}
// 添加 items 元素
func (riss *rawItemsShards) addItems(tb *Table, items [][]byte) error {
n := atomic.AddUint32(&riss.shardIdx, 1)
shards := riss.shards
idx := n % uint32(len(shards))
shard := &shards[idx]
return shard.addItems(tb, items)
}
rawItemsShards其实就是加了一个分片功能用于保存索引数据,addItems函数就是将要添加的数据添加到对应的分片上去,最终执行的逻辑是shard.addItems。
// lib/mergeset/table.go
type rawItemsShard struct {
mu sync.Mutex
ibs []*inmemoryBlock
lastFlushTime uint64
}
// 添加items元素
func (ris *rawItemsShard) addItems(tb *Table, items [][]byte) error {
var err error
var blocksToFlush []*inmemoryBlock
ris.mu.Lock()
ibs := ris.ibs
if len(ibs) == 0 {
ib := getInmemoryBlock()
ibs = append(ibs, ib)
ris.ibs = ibs
}
// 取最后一个内存块
ib := ibs[len(ibs)-1]
for _, item := range items {
// 添加索引item到内存块
if !ib.Add(item) { // 超过了内存块大小
// 重新获取一个内存块,此时肯定为空
ib = getInmemoryBlock()
// 重新添加
if !ib.Add(item) {
putInmemoryBlock(ib)
err = fmt.Errorf("cannot insert an item %q into an empty inmemoryBlock; it looks like the item is too large? len(item)=%d", item, len(item))
break
}
ibs = append(ibs, ib)
ris.ibs = ibs
}
}
// 超过了每个分片的最大内存块的数量
if len(ibs) >= maxBlocksPerShard {
// 将内存块放到待刷新的内存块列表中去
blocksToFlush = append(blocksToFlush, ibs...)
// 释放前面的内存块资源
for i := range ibs {
ibs[i] = nil
}
ris.ibs = ibs[:0]
ris.lastFlushTime = fasttime.UnixTimestamp()
}
ris.mu.Unlock()
// 执行merge合并操作
tb.mergeRawItemsBlocks(blocksToFlush, false)
return err
}
// lib/mergeset/encoding.go
// 内存中的一个Block块结构
type inmemoryBlock struct {
commonPrefix []byte
data []byte // 用来存储数据
items []Item // 用来存储每个item数据的起始偏移量
}
// Item 表示用于存储在 mergeset 中的单个 item 数据
type Item struct {
// 数据的开始偏移量
Start uint32
// 数据的结束偏移量
End uint32
}
// maxInmemoryBlockSize 是 memoryblock.data 的最大值。
//
// 它必须适合 CPU 缓存大小,即当前 CPU 的缓存大小为64kb。
const maxInmemoryBlockSize = 64 * 1024
// Add 将 x 添加到内存卡 ib 的末尾
//
// 如果由于块大小限制,x 未添加到 ib,则返回 false
func (ib *inmemoryBlock) Add(x []byte) bool {
data := ib.data
// 操过块大小限制了
if len(x)+len(data) > maxInmemoryBlockSize {
return false
}
if cap(data) == 0 {
// 预分配 data 和 items 以减少内存分配
data = make([]byte, 0, maxInmemoryBlockSize)
ib.items = make([]Item, 0, 512)
}
dataLen := len(data)
data = append(data, x...) // 将 x 添加到 data
ib.items = append(ib.items, Item{ // 更新 items
Start: uint32(dataLen),
End: uint32(len(data)),
})
ib.data = data
return true
}
rawItemsShard表示保存索引数据的一个分片,里面其实就是一个inmemoryBlock的内存块切片,每个分片最多有 512 个内存块,每个内存块占用 64KB 的容量,当每个分片中的内存块数量超过最大数量(512)会去将内存块数据刷新为Part。 如果分片中的内存块数量没超过上限,则会通过一个任务去定时(1s)将 rawItem 数据刷新(转换)为Part,以便它们对搜索可见。
// lib/mergeset/table.go
// 将最近的 rawItem 刷新(转换)为 Part,以便它们对搜索可见。
const rawItemsFlushInterval = time.Second
// 启动 rawItems Flusher 任务
func (tb *Table) startRawItemsFlusher() {
tb.rawItemsFlusherWG.Add(1)
go func() {
tb.rawItemsFlusher()
tb.rawItemsFlusherWG.Done()
}()
}
func (tb *Table) rawItemsFlusher() {
ticker := time.NewTicker(rawItemsFlushInterval)
defer ticker.Stop()
for {
select {
case <-tb.stopCh:
return
case <-ticker.C:
tb.flushRawItems(false)
}
}
}
合并内存数据
将内存块数据转换为Part都是通过mergeRawItemsBlocks函数去实现的。
// lib/mergeset/table.go
// 一次合并的默认 parts 数
//
// 这个数字是根据经验得出的,它提供了尽可能低的开销
// 有关详细信息,请参阅 appendPartsToMerge test
const defaultPartsToMerge = 15
// merge 内存块数据
func (tb *Table) mergeRawItemsBlocks(ibs []*inmemoryBlock, isFinal bool) {
if len(ibs) == 0 {
return
}
tb.partMergersWG.Add(1)
defer tb.partMergersWG.Done()
pws := make([]*partWrapper, 0, (len(ibs)+defaultPartsToMerge-1)/defaultPartsToMerge)
var pwsLock sync.Mutex
var wg sync.WaitGroup
for len(ibs) > 0 {
// 一次最大合并的内存块数量
n := defaultPartsToMerge
if n > len(ibs) {
n = len(ibs)
}
wg.Add(1)
go func(ibsPart []*inmemoryBlock) {
defer wg.Done()
// merge inmemoryBlock
pw := tb.mergeInmemoryBlocks(ibsPart)
if pw == nil {
return
}
pw.isInMerge = true
pwsLock.Lock()
pws = append(pws, pw)
pwsLock.Unlock()
}(ibs[:n])
ibs = ibs[n:]
}
wg.Wait()
if len(pws) > 0 {
if err := tb.mergeParts(pws, nil, true); err != nil {
logger.Panicf("FATAL: cannot merge raw parts: %s", err)
}
if tb.flushCallback != nil {
if isFinal {
tb.flushCallback()
} else {
atomic.CompareAndSwapUint32(&tb.needFlushCallbackCall, 0, 1)
}
}
}
for {
tb.partsLock.Lock()
ok := len(tb.parts) <= maxParts
tb.partsLock.Unlock()
if ok {
return
}
// The added part exceeds maxParts count. Assist with merging other parts.
//
// Prioritize assisted merges over searches.
storagepacelimiter.Search.Inc()
err := tb.mergeExistingParts(false)
storagepacelimiter.Search.Dec()
if err == nil {
atomic.AddUint64(&tb.assistedMerges, 1)
continue
}
if errors.Is(err, errNothingToMerge) || errors.Is(err, errForciblyStopped) {
return
}
logger.Panicf("FATAL: cannot merge small parts: %s", err)
}
}
mergeRawItemsBlocks函数将指定的内存块进行 merge 合并操作,一次合并最大的内存块数量为 15,然后在独立的 goroutine 中去进行合并操作,使用mergeInmemoryBlocks函数。
// lib/mergeset/table.go
// merge InmemoryBlocks
func (tb *Table) mergeInmemoryBlocks(ibs []*inmemoryBlock) *partWrapper {
// 将 InmemoryBlock 列表转换成 inmemoryPart 列表
// inmemoryPart 表示内存中的Part
mps := make([]*inmemoryPart, 0, len(ibs))
for _, ib := range ibs {
if len(ib.items) == 0 {
continue
}
mp := getInmemoryPart()
mp.Init(ib) // 将inmemoryBlock转换为inmemoryPart
putInmemoryBlock(ib)
mps = append(mps, mp)
}
if len(mps) == 0 {
return nil
}
if len(mps) == 1 {
// 没有要合并的内容。只需返回单个 inmemory part。
mp := mps[0]
p := mp.NewPart()
return &partWrapper{
p: p,
mp: mp,
refCount: 1,
}
}
defer func() {
for _, mp := range mps {
putInmemoryPart(mp)
}
}()
atomic.AddUint64(&tb.mergesCount, 1)
atomic.AddUint64(&tb.activeMerges, 1)
defer atomic.AddUint64(&tb.activeMerges, ^uint64(0))
// 为每个 `inmemoryPart` 构造 `blockStreamReader`, 用于迭代读取 items
bsrs := make([]*blockStreamReader, 0, len(mps))
for _, mp := range mps {
bsr := getBlockStreamReader()
bsr.InitFromInmemoryPart(mp)
bsrs = append(bsrs, bsr)
}
// 准备一个 blockStreamWriter 用于合并写入的 part
bsw := getBlockStreamWriter()
// 不要通过 getInmemoryPart() 获取 mpDst,因为与池中的其他条目相比,它的大小可能太大。
// 这可能会导致内存使用量增加,因为存在大量的碎片。
// 创建一个新的 inmemoryPart,接收合并的数据
mpDst := &inmemoryPart{}
bsw.InitFromInmemoryPart(mpDst)
// 开始 merge 数据
// 该 merge 不应该被 stopCh 中断,因为它可能是 stopCh 关闭后的最终结果
err := mergeBlockStreams(&mpDst.ph, bsw, bsrs, tb.prepareBlock, nil, &tb.itemsMerged)
if err != nil {
logger.Panicf("FATAL: cannot merge inmemoryBlocks: %s", err)
}
putBlockStreamWriter(bsw)
for _, bsr := range bsrs {
putBlockStreamReader(bsr)
}
p := mpDst.NewPart()
return &partWrapper{
p: p,
mp: mpDst,
refCount: 1,
}
}
上面的函数会将指定的内存块转换成partWrapper,该结构就是一个包含part和inmemoryPart的包装器。
// lib/mergeset/table.go
type partWrapper struct {
p *part
mp *inmemoryPart
refCount uint64
isInMerge bool
}
part的结构如下所示:
// lib/mergeset/part.go
type part struct {
ph partHeader
path string
size uint64
mrs []metaindexRow
indexFile fs.MustReadAtCloser
itemsFile fs.MustReadAtCloser
lensFile fs.MustReadAtCloser
}
一个part就是Table下面的一个数据目录。
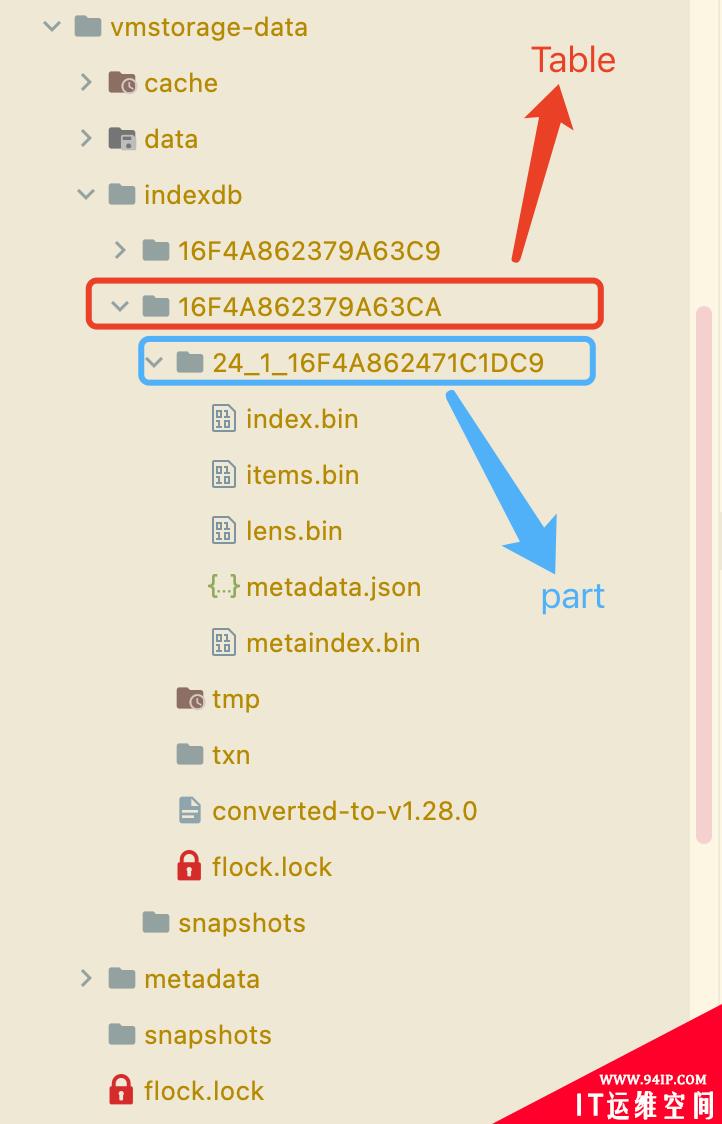 part中包含一个partHeader,该属性中包含当前part的一些 Meta 信息,一共有多少个 items、有多少 blocks、第一个和最后一个 item,对应着part目录下面的metadata.json文件。
part中包含一个partHeader,该属性中包含当前part的一些 Meta 信息,一共有多少个 items、有多少 blocks、第一个和最后一个 item,对应着part目录下面的metadata.json文件。
// lib/mergeset/part_header.go
type partHeader struct {
// part 包含的 items 数
itemsCount uint64
// part 包含的 blocks 数
blocksCount uint64
// part 中的第一个 item
firstItem []byte
// part 中的最后一个 item
lastItem []byte
}
part中另外的属性path表示当前part的路径,size表示大小,另外三个属性indexFile、itemsFile、lensFile对应中part目录下面的三个文件:index.bin、items.bin、lens.bin。此外part结构中还有最后一个mrs属性,是一个[]metaindexRow。
// lib/mergeset/metaindex_row.go
// metaindexRow 描述了一个 blockHeaders 即索引块。
type metaindexRow struct {
// 第一个 block 中的第一个 item 元素
// 它用于快速查找所需的索引块
firstItem []byte
// 块包含的 blockHeaders 的数量
blockHeadersCount uint32
// 索引文件中块的偏移量
indexBlockOffset uint64
// 索引文件中块的大小
indexBlockSize uint32
}
除了part之外还有一个内存中的inmemoryPart结构,其基本结构和part类似,不同的是几个相关的属性不是文件对象,而是ByteBuffer,因为是内存中的结构。
// lib/mergeset/inmemory_part.go
// 在内存中的 Part 结构
type inmemoryPart struct {
// partHeader 记录 itemsCount, blocksCount, firstItem, lastItem 信息, 最后会序列化到 metadata.json
ph partHeader
// 当前 block 的 header 信息,有 commonPrefix, firstItem, marshalType, itemsCount, itemsBlockOffset, lenBlockOffset, itemsBlockSize, lenBlockSize
bh blockHeader
// 当前 block 的 metaindex 信息,存储了当前 blockHeader 的 firstItem, blockHeaderCount, indexBlockOffset, indexBlockSize
mr metaindexRow
// 用于序列化后写入内存/磁盘文件使用
metaindexData bytesutil.ByteBuffer // -> metaindex.bin
indexData bytesutil.ByteBuffer // -> index.bin
itemsData bytesutil.ByteBuffer // -> items.bin
lensData bytesutil.ByteBuffer // -> lens.bin
}
其他几个属性上面介绍过,blockHeader结构如下所示,用于记录 block 头信息:
// lib/mergeset/block_header.go
type blockHeader struct {
// 块中所有 items 的公用前缀
commonPrefix []byte
// 第一个 item
firstItem []byte
// 用于块压缩的 Marshal 类型
marshalType marshalType
// 块中的 items 数,不包括第一个 item
itemsCount uint32
// items block 的偏移量
itemsBlockOffset uint64
// lens block 的偏移量
lensBlockOffset uint64
// items block 的大小
itemsBlockSize uint32
// lens block 的大小
lensBlockSize uint32
}
整个part的结构看上去确实比较复杂,为什么需要设计这些属性?核心肯定就是为了快速索引,我们先往下分析,待会再回过头来看。 inmemoryPart是part读入内存中的结构, 在inmemoryBlockmerge 之前,每个inmemoryBlock都会先通过mp.Init转换成一个inmemoryPart的结构,inmemoryPart中metaindexData、indexData、itemsData、lensData数据结构与磁盘对应的文件内容一致。
序列化数据
现在我们再回到上面的mergeInmemoryBlocks函数,流程如下所示:
-
1.将所有的inmemoryBlock转换为inmemoryPart结构。
2.为每个inmemoryPart构造blockStreamReader,用于迭代读取 items。
3.创建一个新的inmemoryPart,并构造一个blockSteamWriter用于合并写入的数据。
4.然后调用mergeBlockStreams函数执行真正的merge操作。
首先通过Init函数将inmemoryBlock转换为inmemoryPart结构。
// lib/mergeset/inmemory_part.go
// Init 初始化 mp 从 ib.
func (mp *inmemoryPart) Init(ib *inmemoryBlock) {
mp.Reset()
sb := &storageBlock{}
sb.itemsData = mp.itemsData.B[:0]
sb.lensData = mp.lensData.B[:0]
// 使用尽可能小的压缩等级来压缩 inmemoryPart,因为它很快就会被合并到文件 part 去。
compressLevel := -5
// 序列化乱序的数据
mp.bh.firstItem, mp.bh.commonPrefix, mp.bh.itemsCount, mp.bh.marshalType = ib.MarshalUnsortedData(sb, mp.bh.firstItem[:0], mp.bh.commonPrefix[:0], compressLevel)
// 获取 partHeader 值
mp.ph.itemsCount = uint64(len(ib.items))
mp.ph.blocksCount = 1
mp.ph.firstItem = append(mp.ph.firstItem[:0], ib.items[0].String(ib.data)...)
mp.ph.lastItem = append(mp.ph.lastItem[:0], ib.items[len(ib.items)-1].String(ib.data)...)
// 获取itemsData,更新blockHeader的items偏移和数量
mp.itemsData.B = sb.itemsData
mp.bh.itemsBlockOffset = 0
mp.bh.itemsBlockSize = uint32(len(mp.itemsData.B))
// 获取lensData,更新blockHeader的lens偏移和数量
mp.lensData.B = sb.lensData
mp.bh.lensBlockOffset = 0
mp.bh.lensBlockSize = uint32(len(mp.lensData.B))
// 获取 indexData,blockHeader序列化的值
bb := inmemoryPartBytePool.Get()
bb.B = mp.bh.Marshal(bb.B[:0])
mp.indexData.B = encoding.CompressZSTDLevel(mp.indexData.B[:0], bb.B, 0)
// 获取 metaindexData,metaindexRow序列化的值
mp.mr.firstItem = append(mp.mr.firstItem[:0], mp.bh.firstItem...)
mp.mr.blockHeadersCount = 1
mp.mr.indexBlockOffset = 0
mp.mr.indexBlockSize = uint32(len(mp.indexData.B))
bb.B = mp.mr.Marshal(bb.B[:0])
mp.metaindexData.B = encoding.CompressZSTDLevel(mp.metaindexData.B[:0], bb.B, 0)
inmemoryPartBytePool.Put(bb)
}
上面的函数将inmemoryBlock转换成inmemoryPart,首先会通过一个MarshalUnsortedData函数来序列化未排序的数据。
// MarshalUnsortedData 序列化未排序的 items 从 ib 到 sb.
//
// It also:
// - 将第一个 item 追加到 firstItemDst 并返回结果
// - 将所有 item 的公共前缀附加到 commonPrefixDst 并返回结果
// - 返回包含第一个 item 的编码项的数量
// - 返回用于编码的 marshal 类型
func (ib *inmemoryBlock) MarshalUnsortedData(sb *storageBlock, firstItemDst, commonPrefixDst []byte, compressLevel int) ([]byte, []byte, uint32, marshalType) {
if !ib.isSorted() {
sort.Sort(ib) // 排序
}
// 更新内存块的公共前缀
ib.updateCommonPrefix()
// 序列化数据
return ib.marshalData(sb, firstItemDst, commonPrefixDst, compressLevel)
}
上面的序列化函数中首先会对未排序的数据进行排序,然后更新内存块的公共前缀:
// lib/mergeset/encoding.go
// 更新公共前缀
func (ib *inmemoryBlock) updateCommonPrefix() {
ib.commonPrefix = ib.commonPrefix[:0] // 公共前缀
if len(ib.items) == 0 {
return
}
items := ib.items // 数据前后位置
data := ib.data // 数据
cp := items[0].Bytes(data) // 第一段数据
if len(cp) == 0 {
return
}
for _, it := range items[1:] { // 后面的数据
// 计算公共前缀的长度
cpLen := commonPrefixLen(cp, it.Bytes(data))
if cpLen == 0 {
return
}
// 截取公共前缀数据
cp = cp[:cpLen]
}
// 设置内存块的公共前缀
ib.commonPrefix = append(ib.commonPrefix[:0], cp...)
}
公共前缀就是把每段数据包含的共同前缀提取出来,这样存储的时候后面就可以不需要存储共同的部分了,减少存储空间。
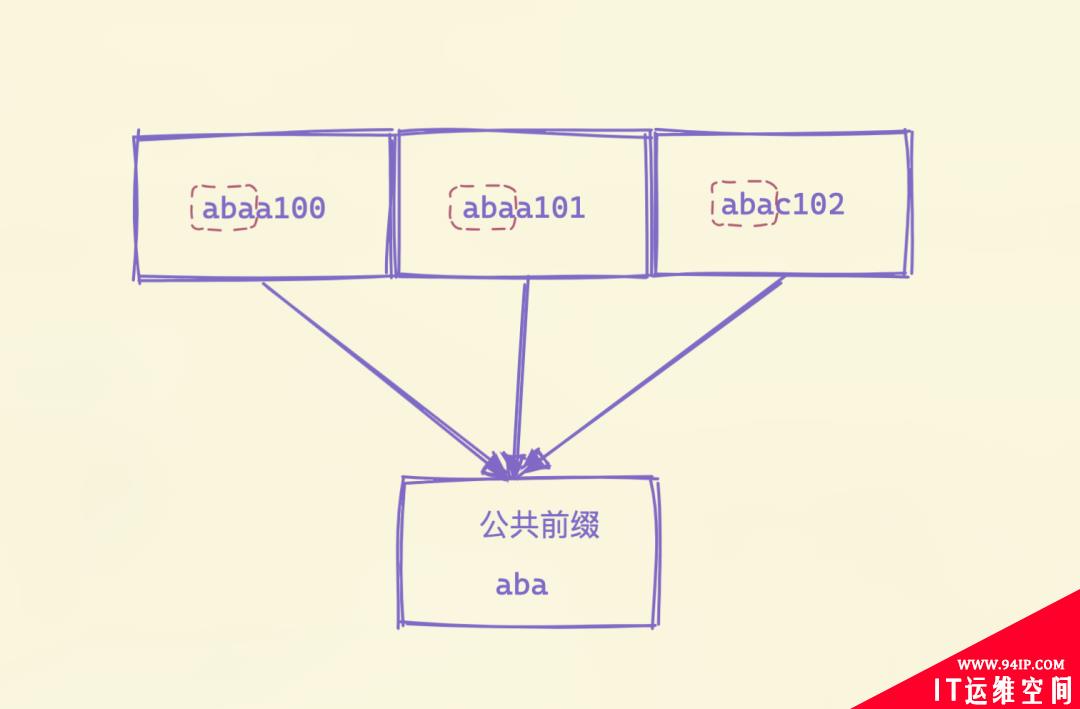 公共前缀提取出来后,接下来调用marshalData函数去序列化数据。
公共前缀提取出来后,接下来调用marshalData函数去序列化数据。
// lib/mergeset/encoding.go
// 前提条件:
// - ib.items 必须排序
// - updateCommonPrefix 必须被调用
// 序列化数据
func (ib *inmemoryBlock) marshalData(sb *storageBlock, firstItemDst, commonPrefixDst []byte, compressLevel int) ([]byte, []byte, uint32, marshalType) {
......
// 拷贝 inmemoryBlock 数据块的 firstItem(排序后的第一条数据)
data := ib.data // 内存块数据
firstItem := ib.items[0].Bytes(data) // 第一条数据
firstItemDst = append(firstItemDst, firstItem...)
// 最大公共前缀
commonPrefixDst = append(commonPrefixDst, ib.commonPrefix...)
// 内存块数据小于2段或(数据大小-公共前缀长度*数据段大小 < 64) 则定义为小块
if len(data)-len(ib.commonPrefix)*len(ib.items) < 64 || len(ib.items) < 2 {
// 对small block使用普通序列化,因为它更便宜
ib.marshalDataPlain(sb)
return firstItemDst, commonPrefixDst, uint32(len(ib.items)), marshalTypePlain
}
bbItems := bbPool.Get()
bItems := bbItems.B[:0] // 保存目的 items 数据的内存 buffer
bbLens := bbPool.Get()
bLens := bbLens.B[:0] // 保存目的 lens 数据的内存buffer
// 序列化 items 数据
// 第一项数据不需要存储,所以获取的 Uint64s 大小要减1
xs := encoding.GetUint64s(len(ib.items) - 1)
defer encoding.PutUint64s(xs)
cpLen := len(ib.commonPrefix) // 公共前缀的长度
prevItem := firstItem[cpLen:] // 第一项数据(排除公共前缀)
prevPrefixLen := uint64(0)
// 从第二个元素开始遍历(第一个 firstItem 单独存储)
for i, it := range ib.items[1:] {
// 偏移到公共前缀之后的位置
it.Start += uint32(cpLen)
// Bytes(data) 得到的数据不包含公共前缀的部分
item := it.Bytes(data)
// 计算第 N 项和 N-1 项的公共前缀长度
prefixLen := uint64(commonPrefixLen(prevItem, item))
// 仅仅只把差异的部分拷贝到目的buffer
bItems = append(bItems, item[prefixLen:]...)
// 第一次,与0异或,还是等于原值。异或后,两个整数值前面相同的部分都为0了,数值变得更短,能够便于压缩。
xLen := prefixLen ^ prevPrefixLen
// 上次的除去公共前缀的item
prevItem = item
// 上次计算得到的公共前缀长度
prevPrefixLen = prefixLen
xs.A[i] = xLen // 异或后的公共前缀值
}
// 对N-1个长度进行序列化(将uint64数组序列化成byte数组)
bLens = encoding.MarshalVarUint64s(bLens, xs.A)
// 将items数据(只有差异的部分)ZSTD压缩后,写入storageBlock
sb.itemsData = encoding.CompressZSTDLevel(sb.itemsData[:0], bItems, compressLevel)
bbItems.B = bItems
bbPool.Put(bbItems)
// 序列化 lens 数据
// 第一项数据大小(排除公共前缀)
prevItemLen := uint64(len(firstItem) - cpLen)
for i, it := range ib.items[1:] { // 从第二个元素开始遍历
// item长度 = End-Start-公共前缀大小
itemLen := uint64(int(it.End-it.Start) - cpLen)
// 与前面一个元素长度异或
xLen := itemLen ^ prevItemLen
// 上次去除公共前缀的长度
prevItemLen = itemLen
xs.A[i] = xLen // 异或后的元素长度
}
// 前面记录的是两两相对的长度,这里记录的是数据的真实长度
// 长度信息包含两种,相对长度和总长度
bLens = encoding.MarshalVarUint64s(bLens, xs.A)
// 将lens数据进行ZSTD压缩后,写入storageBlock
sb.lensData = encoding.CompressZSTDLevel(sb.lensData[:0], bLens, compressLevel)
bbLens.B = bLens
bbPool.Put(bbLens)
// 如果压缩不到90%则选择不压缩
if float64(len(sb.itemsData)) > 0.9*float64(len(data)-len(ib.commonPrefix)*len(ib.items)) {
// 压缩率不高的时候,选择不压缩
ib.marshalDataPlain(sb)
return firstItemDst, commonPrefixDst, uint32(len(ib.items)), marshalTypePlain
}
// 很好的压缩率
return firstItemDst, commonPrefixDst, uint32(len(ib.items)), marshalTypeZSTD
}
上面的序列化函数看上去比较复杂,实际上核心的一点就是想办法尽可能减少存储空间。首先将数据块的第一个数据拷贝出来放入firstItemDst,然后后面就从第二个元素开始去循环处理,首先计算第N项和N-1项的公共前缀长度,然后将差异的数据部分保存起来,为了能够反序列化回数据,还需要将两两之间公共前缀的长度保存下来,为了能够便于压缩,使用异或的方式来计算两两之间的公共前缀长度值。
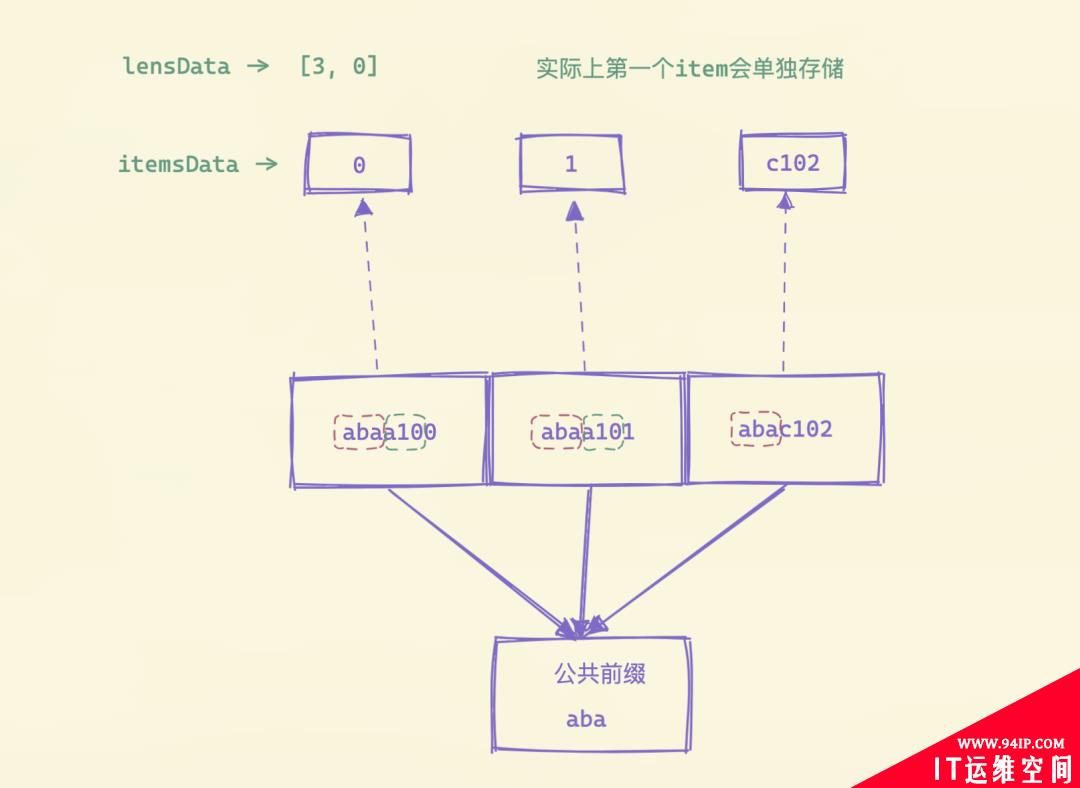 循环计算后,将保存的两两之间的公共前缀长度进行序列化,下面的函数将一个uint64类型的切片转换成字节切片,如果数据小于 128 直接转换即可,如果大于 127 则用一个 7bit 来表示数值的内容,最高位后面的一个字节用来表示长度,这样就可以用变长长度来序列化数值,而不是每个数值都占用固定的长度。
循环计算后,将保存的两两之间的公共前缀长度进行序列化,下面的函数将一个uint64类型的切片转换成字节切片,如果数据小于 128 直接转换即可,如果大于 127 则用一个 7bit 来表示数值的内容,最高位后面的一个字节用来表示长度,这样就可以用变长长度来序列化数值,而不是每个数值都占用固定的长度。
// lib/encoding/int.go
// 将uint64切片转成字节切片
func MarshalVarUint64s(dst []byte, us []uint64) []byte {
for _, u := range us {
if u < 0x80 { // 小于128,直接加入到 dst,能直接存到 byte 中去
// Fast path
dst = append(dst, byte(u))
continue
}
for u > 0x7f { // 大于127,则超过的部分保留为 0x80,低位右移7位继续计算
dst = append(dst, 0x80|byte(u))
u >>= 7
}
dst = append(dst, byte(u))
}
return dst
}
长度数据序列化后,将 items 数据(只有差异的部分)进行ZSTD压缩后,写入 storageBlock。 只记录两两之间的公共前缀长度还不够,还需要记录数据的真实长度,最后同样再将 lens 数据进行ZSTD压缩后,写入 storageBlock。 如果最后的结果压缩不到 90% 则选择不压缩,不压缩则使用marshalDataPlain函数进行序列化:
// lib/mergeset/encoding.go
// 普通序列化数据
func (ib *inmemoryBlock) marshalDataPlain(sb *storageBlock) {
data := ib.data
// 序列化 items 数据
// 不需要序列化第一项数据,因为它会在 marshalData 中返回给调用者。
cpLen := len(ib.commonPrefix) // 公共前缀长度
b := sb.itemsData[:0]
for _, it := range ib.items[1:] { // 第一项之后的数据
it.Start += uint32(cpLen) // 跳过公共前缀
b = append(b, it.String(data)...) // 添加移出公共前缀的数据
}
sb.itemsData = b // itemsData数据
// 序列化 lens 数据
b = sb.lensData[:0]
for _, it := range ib.items[1:] { // 第一项之后的数据
// 原始的End-Start-公共前缀长度
b = encoding.MarshalUint64(b, uint64(int(it.End-it.Start)-cpLen))
}
sb.lensData = b
}
经过上面的序列化过后就可以得到第一个数据、公共前缀、items 个数以及序列化类型,然后将这些数据存入blockHeader中去,后面就是一些比较简单的常规操作。 转换成inmemoryPart后,再包装成blockStreamReader,创建一个新的inmemoryPart,并构造一个blockSteamWriter用于合并写入的数据,然后调用mergeBlockStreams函数执行真正的merge操作。
// lib/mergeset/merge.go
// mergeBlockStreams 合并 bsrs 并将结果写入 bsw
//
// 也填充了 ph
//
// prepareBlock 是可选的
//
// 当 stopCh 关闭时,该函数立即返回
//
// 它还以原子方式将合并的 items 添加到 itemsMerged
func mergeBlockStreams(ph *partHeader, bsw *blockStreamWriter, bsrs []*blockStreamReader, prepareBlock PrepareBlockCallback, stopCh <-chan struct{},
itemsMerged *uint64) error {
// 将多个 blockStreamReader 构造成一个 blockStreamMerger 结构
bsm := bsmPool.Get().(*blockStreamMerger)
if err := bsm.Init(bsrs, prepareBlock); err != nil {
return fmt.Errorf("cannot initialize blockStreamMerger: %w", err)
}
err := bsm.Merge(bsw, ph, stopCh, itemsMerged)
bsm.reset()
bsmPool.Put(bsm)
bsw.MustClose()
if err == nil {
return nil
}
return fmt.Errorf("cannot merge %d block streams: %s: %w", len(bsrs), bsrs, err)
}
首先把多个blockStreamReader构造成一个blockStreamMerger结构, merger 里面主要是一个bsrHeap堆用于维护bsrs,用于 merge 数据时的排序。首先通过 merger 的Init函数构造堆排序的结构,然后核心是调用 merger 的Merge函数进行处理。
// lib/mergeset/merge.go
func (bsm *blockStreamMerger) Merge(bsw *blockStreamWriter, ph *partHeader, stopCh <-chan struct{}, itemsMerged *uint64) error {
again:
if len(bsm.bsrHeap) == 0 {
// 将最后的 inmemoryBlock(可能不完整)写入 bsw
bsm.flushIB(bsw, ph, itemsMerged)
return nil
}
select {
case <-stopCh:
return errForciblyStopped
default:
}
// 取出 blockStreamReader
bsr := heap.Pop(&bsm.bsrHeap).(*blockStreamReader)
var nextItem []byte // 下一个 blockStreamReader
hasNextItem := false
if len(bsm.bsrHeap) > 0 {
nextItem = bsm.bsrHeap[0].bh.firstItem
hasNextItem = true
}
items := bsr.Block.items
data := bsr.Block.data
// 循环所有的 items
for bsr.blockItemIdx < len(bsr.Block.items) {
item := items[bsr.blockItemIdx].Bytes(data)
if hasNextItem && string(item) > string(nextItem) {
break
}
// 添加元素
if !bsm.ib.Add(item) {
// bsm.ib 已满,将其刷新到 bsw 并继续
bsm.flushIB(bsw, ph, itemsMerged)
continue
}
bsr.blockItemIdx++
}
if bsr.blockItemIdx == len(bsr.Block.items) {
// bsr.Block 已完全读取,处理下一个 block
if bsr.Next() {
heap.Push(&bsm.bsrHeap, bsr)
goto again
}
if err := bsr.Error(); err != nil {
return fmt.Errorf("cannot read storageBlock: %w", err)
}
goto again
}
// bsr.Block 中的下一个 item 超过了 nextItem
// 调整 bsr.bh.firstItem 并将 bsr 返回到堆
bsr.bh.firstItem = append(bsr.bh.firstItem[:0], bsr.Block.items[bsr.blockItemIdx].String(bsr.Block.data)...)
heap.Push(&bsm.bsrHeap, bsr)
goto again
}
这里主要解决的问题是多个有序的字节数组(inmemoryPart),按照字节序排序,合成一个inmemoryPart的过程,在 merge 的过程中,每 64KB 会单独创建一个blockHeader,用于快速索引该 block 里面的 Items。
持久化数据
最后重复上面的过程,将n个inmemoryBlock合并成(n-1)/defaultPartsToMerge+1个inmemoryPart,最后再调用mergeParts函数完成索引持久化操作,持久化后生成的索引 part,主要包含metaindex.bin、index.bin、lens.bin、items.bin、metadata.json等 5 个文件。 这几个文件的关系如下图所示,metaindex.bin文件通过metaindexRow索引index.bin文件,index.bin文件通过indexBlock中的blockHeader同时索引items.bin文件和items.bin文件。
这几个文件的关系如下图所示,metaindex.bin文件通过metaindexRow索引index.bin文件,index.bin文件通过indexBlock中的blockHeader同时索引items.bin文件和items.bin文件。
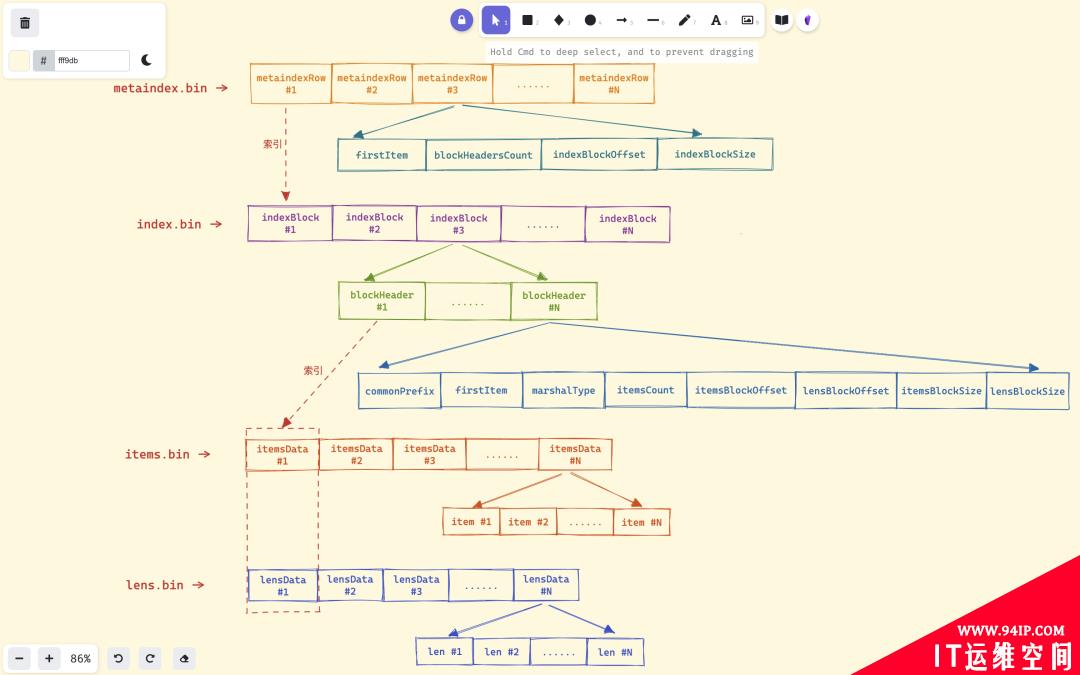 metaindex.bin:文件包含一系列的metaindexRow数据,每个metaindexRow中包含第一条数据firstItem、索引块包含的块头部数blockHeadersCount、索引块偏移indexBlockOffset以及索引块大小indexBlockSize。
metaindex.bin:文件包含一系列的metaindexRow数据,每个metaindexRow中包含第一条数据firstItem、索引块包含的块头部数blockHeadersCount、索引块偏移indexBlockOffset以及索引块大小indexBlockSize。
-
metaindexRow在文件中按照firstItem的大小的字典序排序存储,以支持二分查找。
metaindex.bin文件使用 ZSTD 进行压缩。
metaindex.bin文件中的内容在 part 打开时,会全部读出加载至内存中,以加速查询过滤。
metaindexRow包含的firstItem为其索引的indexBlock中所有blockHeader中字典序最小的firstItem。
查找时根据firstItem进行二分检索。
index.bin:文件中包含一系列的indexBlock, 每个indexBlock又包含一系列blockHeader,每个blockHeader包含 item 的公共前缀commonPrefix、第一项数据firstItem、itemsData的序列化类型marshalType、itemsData包含的 item 数、item 块的偏移itemsBlockOffset等内容,就是前面使用将inmemoryBlock转换为inmemoryPart结构的Init函数得到的。
-
每个indexBlock使用ZSTD压缩算法进行压缩。
在indexBlock中查找时,根据firstItem进行二分检索blockHeader。
items.bin文件中,包含一系列的itemsData, 每个itemsData又包含一系列的 Item。
-
itemsData会视情况而定来是否使用 ZTSD 压缩,当 item 个数小于 2 时,或者itemsData的长度小于 64 字节时,不压缩;当itemsData使用 ZSTD 压缩后的压缩率大于90%的时候也不压缩。
每个 item 在存储时,去掉了blockHeader中的公共前缀commonPrefix以提高压缩率。
lens.bin文件中,包含一系列的lensData, 每个lensData又包含一系列 8 字节的长度 len, 长度 len 标识items.bin文件中对应 item 的长度。在读取或者需要解析itemsData中的 item 时,先要读取对应的lensData中对应的长度 len。 当itemsData进行压缩时,lensData会先使用异或算法进行压缩,然后再使用 ZSTD 算法进一步压缩。 到这里我们就了解了索引数据是实现和存储原理了,那么真正的指标数据又是如何去存储的呢?
转载请注明:IT运维空间 » 运维技术 » VictorialMetrics存储原理之索引存储格式
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/8.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值







发表评论