

作者 | vivo 互联网服务器团队-You Shuo 副本迁移是Kafka最高频的操作,对于一个拥有几十万个副本的集群,通过人工去完成副本迁移是一件很困难的事情。Cruise Control作为Kafka的运维工具,它包含了Kafka 服务上下线、集群内负载均衡、副本扩缩容、副本缺失修复以及节点降级等功能。显然,Cruise Control的出现,使得我们能够更容易的运维大规模Kafka集群。 备注:本文基于 Kafka 2.1.1开展。
一、 Kafka 负载均衡
1.1 生产者负载均衡
Kafka 客户端可以使用分区器依据消息的key计算分区,如果在发送消息时未指定key,则默认分区器会基于round robin算法为每条消息分配分区; 否则会基于murmur2哈希算法计算key的哈希值,并与分区数取模的到最后的分区编号。 很显然,这并不是我们要讨论的Kafka负载均衡,因为生产者负载均衡看起来并不是那么的复杂。
1.2 消费者负载均衡
考虑到消费者上下线、topic分区数变更等情况,KafkaConsumer还需要负责与服务端交互执行分区再分配操作,以保证消费者能够更加均衡的消费topic分区,从而提升消费的性能; Kafka目前主流的分区分配策略有2种(默认是range,可以通过partition.assignment.strategy参数指定):
-
range:在保证均衡的前提下,将连续的分区分配给消费者,对应的实现是RangeAssignor;
round-robin:在保证均衡的前提下,轮询分配,对应的实现是RoundRobinAssignor;
0.11.0.0版本引入了一种新的分区分配策略StickyAssignor,其优势在于能够保证分区均衡的前提下尽量保持原有的分区分配结果,从而避免许多冗余的分区分配操作,减少分区再分配的执行时间。
无论是生产者还是消费者,Kafka 客户端内部已经帮我们做了负载均衡了,那我们还有讨论负载均衡的必要吗?答案是肯定的,因为Kafka负载不均的主要问题存在于服务端而不是客户端。
二、 Kafka 服务端为什么要做负载均衡
我们先来看一下Kafka集群的流量分布(图1)以及新上线机器后集群的流量分布(图2):
 图1
图1
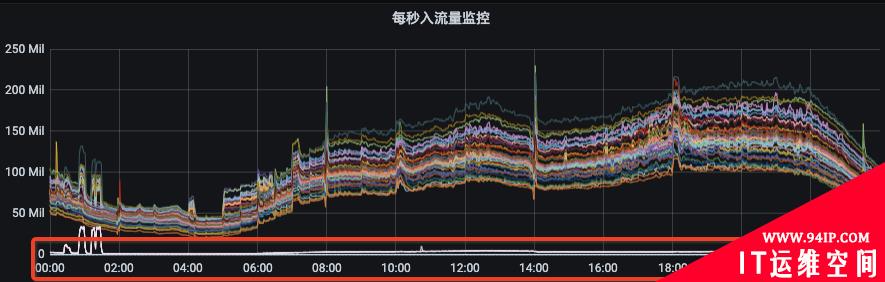 图2
从图1可以看出资源组内各broker的流量分布并不是很均衡,而且由于部分topic分区集中分布在某几个broker上,当topic流量突增的时候,会出现只有部分broker流量突增。
这种情况下,我们就需要扩容topic分区或手动执行迁移动操作。
图2是我们Kafka集群的一个资源组扩容后的流量分布情况,流量无法自动的分摊到新扩容的节点上。此时,就需要我们手动的触发数据迁移,从而才能把流量引到新扩容的节点上。
图2
从图1可以看出资源组内各broker的流量分布并不是很均衡,而且由于部分topic分区集中分布在某几个broker上,当topic流量突增的时候,会出现只有部分broker流量突增。
这种情况下,我们就需要扩容topic分区或手动执行迁移动操作。
图2是我们Kafka集群的一个资源组扩容后的流量分布情况,流量无法自动的分摊到新扩容的节点上。此时,就需要我们手动的触发数据迁移,从而才能把流量引到新扩容的节点上。
2.1 Kafka 存储结构
为什么会出现上述的问题呢?这个就需要从Kafka的存储机制说起。 下图是Kafka topic的存储结构,其具体层级结构描述如下:
每个broker节点可以通过logDirs配置项指定多个log目录,我们线上机器共有12块盘,每块盘都对应一个log目录。 每个log目录下会有若干个[topic]-[x]字样的目录,该目录用于存储指定topic指定分区的数据,对应的如果该topic是3副本,那在集群的其他broker节点上会有两个和该目录同名的目录。 客户端写入kafka的数据最终会按照时间顺序成对的生成.index、.timeindex、.snapshot以及.log文件,这些文件保存在对应的topic分区目录下。 为了实现高可用目的,我们线上的topic一般都是2副本/3副本,topic分区的每个副本都分布在不同的broker节点上,有时为了降低机架故障带来的风险,topic分区的不同副本也会被要求分配在不同机架的broker节点上。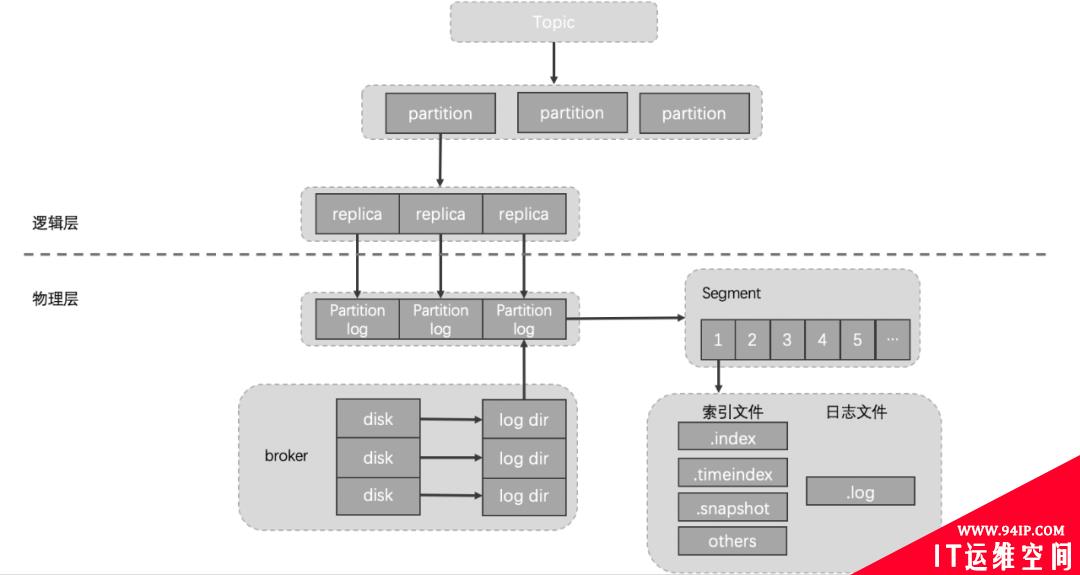 了解完Kafka存储机制之后,我们可以清晰的了解到,客户端写入Kafka的数据会按照topic分区被路由到broker的不同log目录下,只要我们不人工干预,那每次路由的结果都不会改变。因为每次路由结果都不会改变,那么问题来了:
随着topic数量不断增多,每个topic的分区数量又不一致,最终就会出现topic分区在Kafka集群内分配不均的情况。
比如:topic1是10个分区、topic2是15个分区、topic3是3个分区,我们集群有6台机器。那6台broker上总会有4台broker有两个topic1的分区,有3台broke上有3个topic3分区等等。
这样的问题就会导致分区多的broker上的出入流量可能要比其他broker上要高,如果要考虑同一topic不同分区流量不一致、不同topic流量又不一致,再加上我们线上有7000个topic、13万个分区、27万个副本等等这些。
这么复杂的情况下,集群内总会有broker负载特别高,有的broker负载特别低,当broker负载高到一定的时候,此时就需要我们的运维同学介入进来了,我们需要帮这些broker减减压,从而间接的提升集群总体的负载能力。
当集群整体负载都很高,业务流量会持续增长的时候,我们会往集群内扩机器。有些同学想扩机器是好事呀,这会有什么问题呢?问题和上面是一样的,因为发往topic分区的数据,其路由结果不会改变,如果没有人工干预的话,那新扩进来机器的流量就始终是0,集群内原来的broker负载依然得不到减轻。
了解完Kafka存储机制之后,我们可以清晰的了解到,客户端写入Kafka的数据会按照topic分区被路由到broker的不同log目录下,只要我们不人工干预,那每次路由的结果都不会改变。因为每次路由结果都不会改变,那么问题来了:
随着topic数量不断增多,每个topic的分区数量又不一致,最终就会出现topic分区在Kafka集群内分配不均的情况。
比如:topic1是10个分区、topic2是15个分区、topic3是3个分区,我们集群有6台机器。那6台broker上总会有4台broker有两个topic1的分区,有3台broke上有3个topic3分区等等。
这样的问题就会导致分区多的broker上的出入流量可能要比其他broker上要高,如果要考虑同一topic不同分区流量不一致、不同topic流量又不一致,再加上我们线上有7000个topic、13万个分区、27万个副本等等这些。
这么复杂的情况下,集群内总会有broker负载特别高,有的broker负载特别低,当broker负载高到一定的时候,此时就需要我们的运维同学介入进来了,我们需要帮这些broker减减压,从而间接的提升集群总体的负载能力。
当集群整体负载都很高,业务流量会持续增长的时候,我们会往集群内扩机器。有些同学想扩机器是好事呀,这会有什么问题呢?问题和上面是一样的,因为发往topic分区的数据,其路由结果不会改变,如果没有人工干预的话,那新扩进来机器的流量就始终是0,集群内原来的broker负载依然得不到减轻。
三、如何对 Kafka 做负载均衡
3.1 人工生成迁移计划和迁移
如下图所示,我们模拟一个简单的场景,其中的T0-P0-R0表示topic-分区-副本,假设topic各分区流量相同,假设每个分区R0副本是leader。
我们可以看到,有两个topic T0和T1,T0是5分区2副本(出入流量为10和5),T1是3分区2副本(出入流量为5和1),如果严格考虑机架的话,那topic副本的分布可能如下:
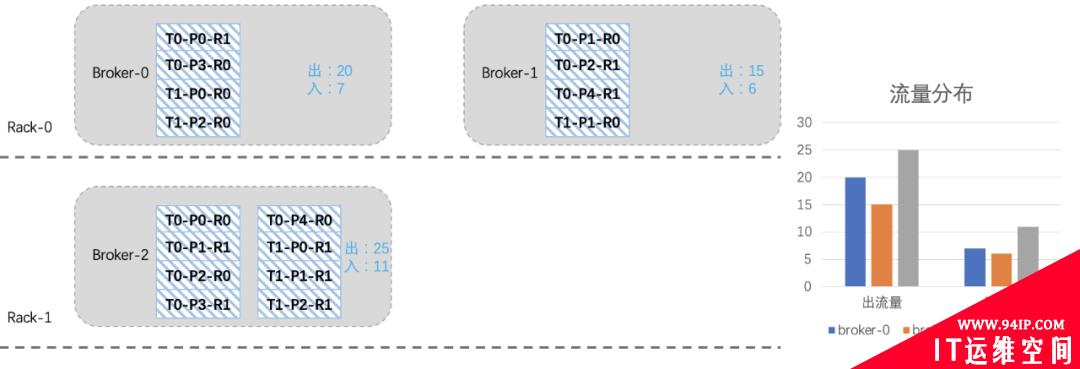 假设我们现在新扩入一台broker3(Rack2),如下图所示:由于之前考虑了topic在机架上的分布,所以从整体上看,broker2的负载要高一些。
假设我们现在新扩入一台broker3(Rack2),如下图所示:由于之前考虑了topic在机架上的分布,所以从整体上看,broker2的负载要高一些。
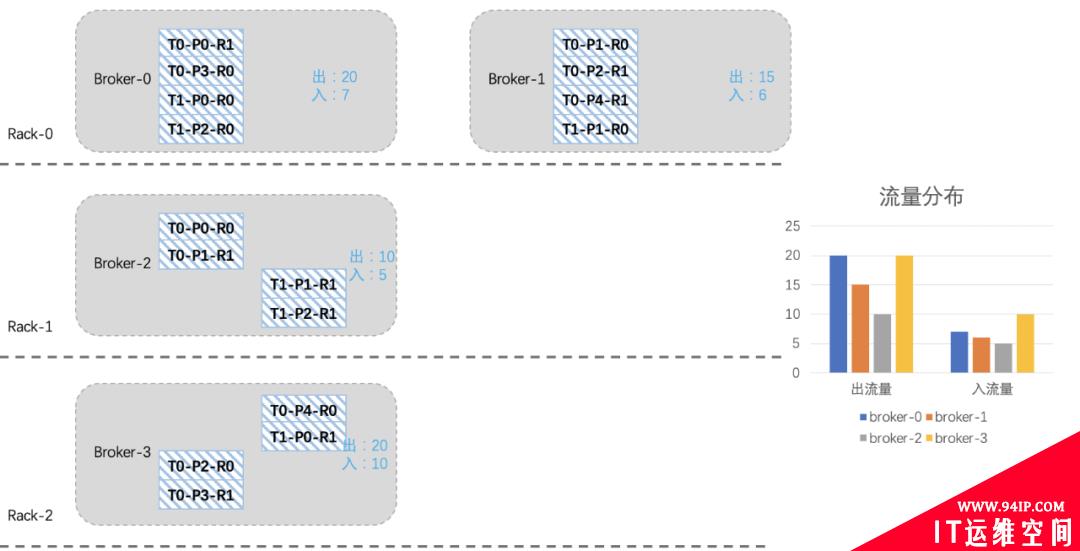
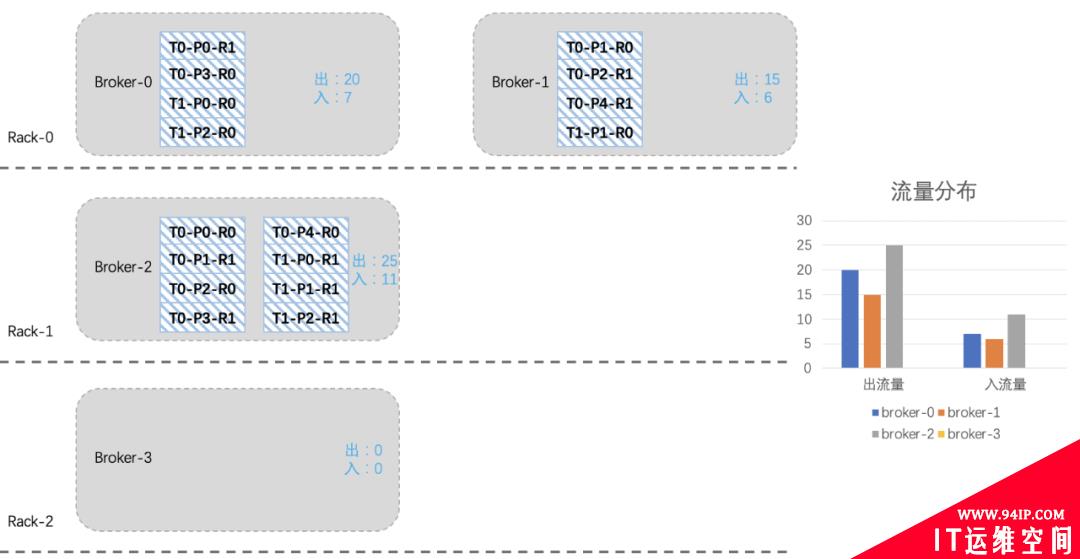 我们现在想把broker2上的一些分区迁移到新扩进来的broker3上,综合考虑机架、流量、副本个数等因素,我们将T0-P2-R0、T0-P3-R1、T0-P4-R0、T1-P0-R1四个分区迁移到broker3上。
我们现在想把broker2上的一些分区迁移到新扩进来的broker3上,综合考虑机架、流量、副本个数等因素,我们将T0-P2-R0、T0-P3-R1、T0-P4-R0、T1-P0-R1四个分区迁移到broker3上。
 看起来还不是很均衡,我们再将T1-P2分区切换一下leader:
看起来还不是很均衡,我们再将T1-P2分区切换一下leader:
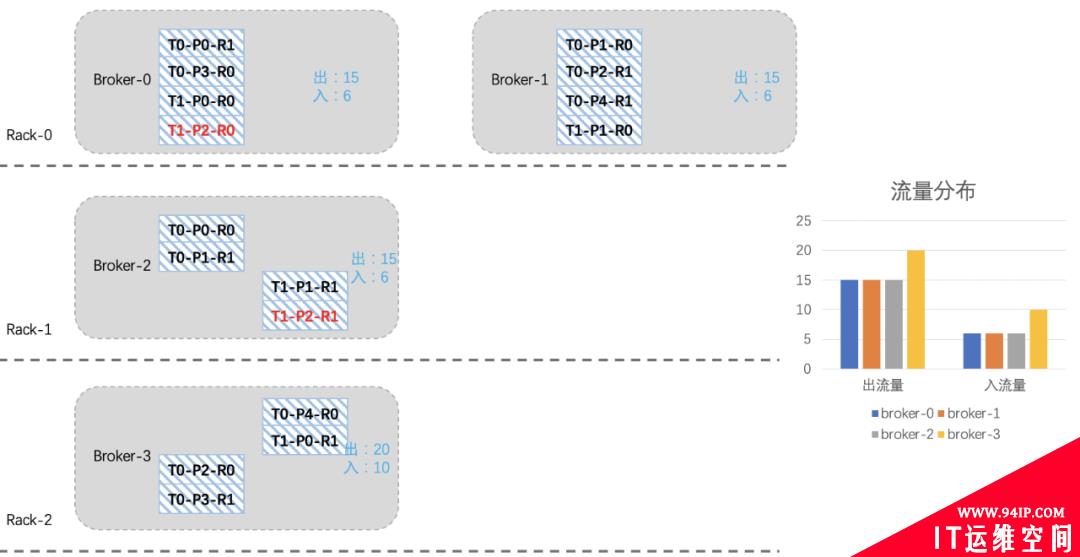 经历一番折腾后,整个集群就均衡许多了,关于上面迁移副本和leader切换的命令参考如下:
Kafka 副本迁移脚本
经历一番折腾后,整个集群就均衡许多了,关于上面迁移副本和leader切换的命令参考如下:
Kafka 副本迁移脚本
# 副本迁移脚本:kafka-reassign-partitions.sh
# 1. 配置迁移文件
$ vi topic-reassignment.json
{"version":1,"partitions":[
{"topic":"T0","partition":2,"replicas":[broker3,broker1]},
{"topic":"T0","partition":3,"replicas":[broker0,broker3]},
{"topic":"T0","partition":4,"replicas":[broker3,broker1]},
{"topic":"T1","partition":0,"replicas":[broker2,broker3]},
{"topic":"T1","partition":2,"replicas":[broker2,broker0]}
]}
# 2. 执行迁移命令
bin/kafka-reassign-partitions.sh --throttle 73400320 --zookeeper zkurl --execute --reassignment-json-file topic-reassignment.json
# 3. 查看迁移状态/清除限速配置
bin/kafka-reassign-partitions.sh --zookeeper zkurl --verify --reassignment-json-file topic-reassignment.json
3.2使用负载均衡工具-cruise control
经过对Kafka存储结构、人工干预topic分区分布等的了解后,我们可以看到Kafka运维起来是非常繁琐的,那有没有一些工具可以帮助我们解决这些问题呢? 答案是肯定的。 cruise control是LinkedIn针对Kafka集群运维困难问题而开发的一个项目,cruise control能够对Kafka集群各种资源进行动态负载均衡,这些资源包括:CPU、磁盘使用率、入流量、出流量、副本分布等,同时cruise control也具有首选leader切换和topic配置变更等功能。
3.2.1cruise cotnrol 架构
我们先简单介绍下cruise control的架构。
如下图所示,其主要由Monitor、Analyzer、Executor和Anomaly Detector四部分组成:
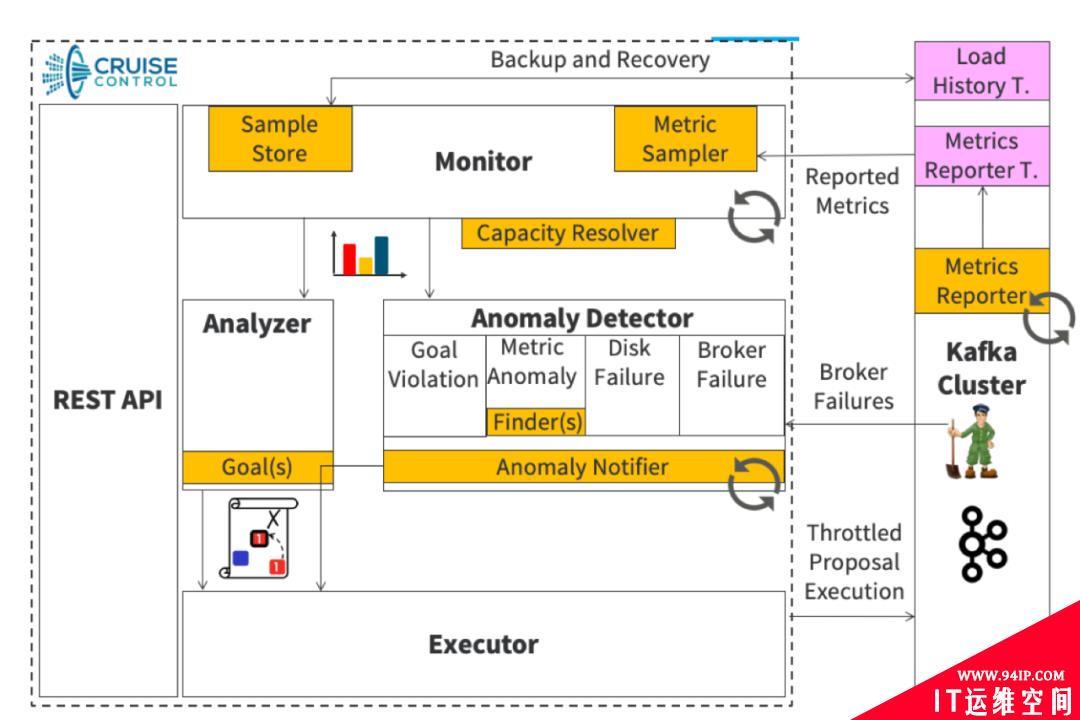 (
(
转载请注明:IT运维空间 » 运维技术 » Kafka 负载均衡在 vivo 的落地实践
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-
JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/10.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值








发表评论