

通常,系统的鲁棒性来自全面有效的错误管理。由于在我们的软硬件系统环境中,任何一个部分都可能发生错误,因此我们需要以不同的方式予以处理。例如:
-
数据中心——整个数据中心(DC)可能由于电源故障、网络连接故障、环境灾难等,而变得不可用。
硬件设备——服务器、存储部件可能出现硬盘故障、磁盘写满、可分配的资源耗尽、以及其他硬件错误等问题。
软件应用——无论应用程序的技术堆栈如何,都可能出现应用报错、软件行为异常、以及程序级别的缺陷等。
为了应对上述来自各个方面的故障,我们往往需要通过如下手段,来提供系统的自愈能力:
-
通过监控,提供电源、网络、冷却系统、以及其他方面的冗余,来实现数据中心的高可用性。
通过云端部署,来减少错误的实例,使用更加成熟的技术堆,基于微服务的分布式架构。
监控服务器的各种参数,采用各种高可用性的部署模式,运用带有DevOps强大功能的容器化模式。
通过应用各种可替代的架构与设计模式,来最小化错误。例如,用户请求的异步处理,可以有助于避免服务器过载的出现,并能够为用户提供一致性的体验。
可见,无论是系统架构师、还是应用设计人员,他们的主要目标都要根据实际业务需求和成本影响,精心考虑和设计各个组件的高可用性,并能够优雅地处理应用程序的错误。
模式的简要说明
目前,业界有许多种架构模式和方法,可以满足不同的应用架构范式、功能需求、NFR(Non-Failure Request)、以及应用程序的故障恢复能力。例如:
-
如果应用是基于微服务的,那么我们的重点就应当放在微服务的集成依赖性的容错上。
如果应用是基于事件的架构,那么除了正常的错误处理之外,我们还应该注意处理幂等性、以及在出现问题时可能造成的数据丢失上。
基于API同步的应用程序,虽然可以便捷地将错误返回给调用者,但是如果问题持续更长的时间,我们则需要更加实用的监控、以及事件管理机制。
在基于批处理的组件中,我们可能应该将重点放在以幂等的方式,重新启动或恢复原有的批处理能力上。
错误代码
如果没有关于错误代码的通用约定与指南,每个应用或系统将会按照自定义的默认错误代码方式,根据用例和设计自行处理。而这有可能会导致不同方式相互之间的冲突。可见,在应用程序的错误处理过程中,我们该事先定义好错误代码,通过标准化且直观的错误处理方式,既提高解决问题的效率,又能够通过离线分析的方式,统计错误数量、负载峰值、以及特定类型故障的影响等细节。
错误处理
下面的示意图展示了如何在基于事件的应用程序中,处理各种错误。当然,其中具体涉及到的步骤,可能会因架构模式的不同而有所差异。
首先,我们应当区分应用程序的可重试(retryable)错误和不可重试(non-retryable)错误。例如,当输入的消息本身存在问题时,通常除非得到人工干预,否则重试此类错误是没有意义的。而那些数据库连接方面的问题,是值得进行重试的。
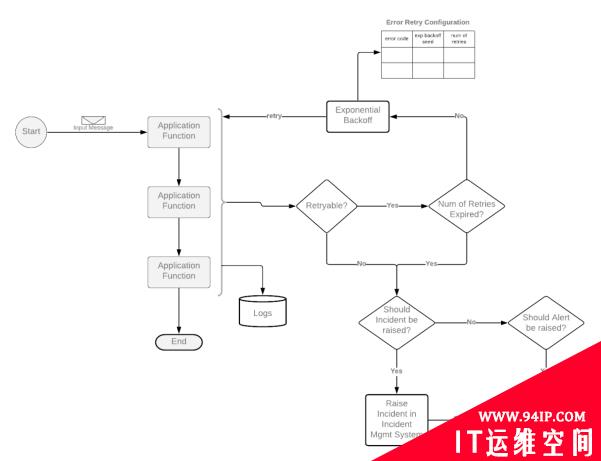 当应用程序出现重试类型的错误时,我们可以选择统一的“错误重试配置”方式,来进行微调处理。如下表所示,在基于事件的服务中,一旦基础设施组件出现可用性的缺失,我们需要通过预定义的反复重试机制,来及时确认运营商是否已及时修复。这往往比直接怀疑和处置由并发量请求所引发的问题可能性,要更加符合常理。
当应用程序出现重试类型的错误时,我们可以选择统一的“错误重试配置”方式,来进行微调处理。如下表所示,在基于事件的服务中,一旦基础设施组件出现可用性的缺失,我们需要通过预定义的反复重试机制,来及时确认运营商是否已及时修复。这往往比直接怀疑和处置由并发量请求所引发的问题可能性,要更加符合常理。
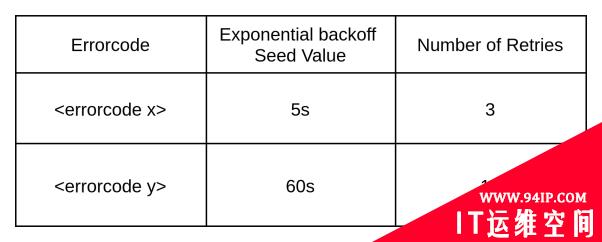
触发事件
在所有重试都以失败告终时,我们需要有一种方法,来触发事件并升级错误。在简单情况下,我们可以将问题的相关信息,直接以通知的形式,反馈给用户,并且建议其重新提交所需的请求。但是有些问题源于某个内部技术问题,所引发并导致的用户体验度的骤降。例如,在基于事件的架构中,异步集成模式通常使用DLQ(译者注:Dead Letter Queue,死信队列)作为错误处理模式。不过,DLQ只是整个过程中的一个临时步骤。我们仍然需要通过触发事件或发送警报的方式,去可靠地升级错误。那么,我们该如何设计一个事件与警报相集成的管理系统呢?下面,我们将讨论两种主要的方法: 第一种方法:当应用程序完成了所有重试之后,我们需要利用其可用的日志功能,构建可靠的错误报告路径,以减少丢失出错信息的可能。虽然业界已有成熟的日志记录标准。但是,我们仍然需要将各个错误日志区别开来,以免事件管理系统中充满了不相关的错误信息。我们通常将此类日志称为“错误警报”。它们往往是由专用的代码库和组件,按照预先设定的格式,及时产生大量的错误信息。下面是一段代码示例:
Java
{
"logType": "ErrorAlert",
"errorCode": "subA.compA.DB.DatabaseA.Access_Error",
"businessObjectId": "234323",
"businessObjectName": "ACCOUNT",
"InputDetails" : "<Input object/ event object>",
"InputContext" : " any context info with the input",
"datetime": "date time of the error",
"errorDetails" : "Error trace",
"..other info as needed": "..."
}
由于大多数组织会使用不同的日志监控技术栈,因此,我在此以日志聚合器(log
aggregator)为例,会将各种日志路由到不同的组件处,以便读取日志事件、对应的配置,并按需触发警报。如下图所示,如果出现需要在监控的基础上,去解决被发现的问题时,我们往往需要再次调用DLQ予以处理。
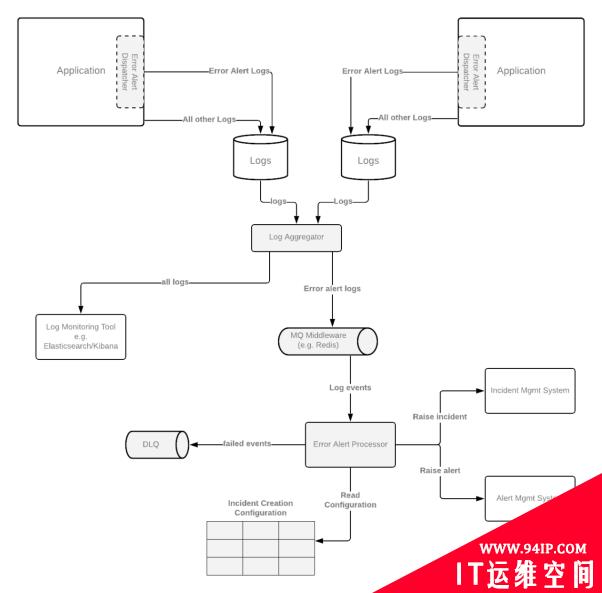 为了让警报能够反应有意义且具有操作性的事件,我们通常需要对它们进行必要的配置。由于组织采用的事件管理系统存在着差异性,因此不同的配置可能会驱动不同类型的后续操作。以下是各种需要配置属性的示例。其错误代码会在整个系统中遵循特定的分类方法。当然,它们也可以按需集中到一个中央的配置管理系统中。
为了让警报能够反应有意义且具有操作性的事件,我们通常需要对它们进行必要的配置。由于组织采用的事件管理系统存在着差异性,因此不同的配置可能会驱动不同类型的后续操作。以下是各种需要配置属性的示例。其错误代码会在整个系统中遵循特定的分类方法。当然,它们也可以按需集中到一个中央的配置管理系统中。
 如下图所示,第二种方法是将错误警报的调度程序组件写入DLQ,而非各个日志中,而其他方面则与第一种方法基本相似。也就是说,它是基于DLQ的。
如下图所示,第二种方法是将错误警报的调度程序组件写入DLQ,而非各个日志中,而其他方面则与第一种方法基本相似。也就是说,它是基于DLQ的。
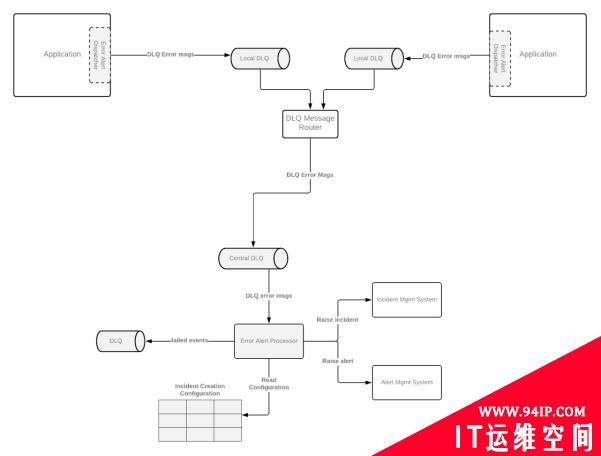
哪种方法更好?
从应用程序的角度来看,基于日志的方法更具有灵活性,当然也存在着如下缺点:
在错误到达事件管理系统之前,我们需要处理各个部件之间的相互集成。 一般来说,日志数据的关键性程度并不是很高,但是如果我们用它来触发事件的话,那么就需要检查它是否存在着丢失或不全的风险。在曾经的系统实施的过程中,我就曾碰到过应用请求出现的峰值,导致日志数据丢失的问题。当时我们就不得不放弃了该方法。当然,这是一种极端的情况,并非所有的日志记录环境都会遇到此类状况。而基于DLQ的方法则存在着如下优、缺点:
我们可以在消息传递系统上,将基于DLQ的方法,作为非DLQ方式的冗余传输链路。当然,是否真的需要此类冗余机制,则完全取决于所传输的数据的重要性。 如果我们需要结合现有系统中的其他应用,那么在将其连接至中央总线(central bus)并发送错误警报时,消息路由器的数量则可能会受到一定的限制。而就这种结合方案本身而言,它不但会增加系统的复杂性,而且提高了额外出错的可能性。 推倒重来的方式只是“看起来很美”。毕竟越少的组件或总线需要被集成,错误警报事件传输的可靠性才会越高。小结
可见,为了有效地处理应用程序中可能出现的错误,我们需要一种整体的解决方法,能够无缝地集成到现有的IT系统中,实现对于错误和问题的有效管理。虽然上文主要讨论的是如何将应用程序的错误处理,集成到事件管理系统中,但是对于本文开头提到的各种硬件问题,此类思路与方法同样具有适用性。当然,所有这些都应当以自动化的方式,聚集到一处,以便它们能够进一步关联上各种错误与问题,进而采用单一的解决方案,来处置所有可能出现的问题。 前文也向您展示了两种依赖于事件管理系统、并能够与现代技术(如API或某种SDK)相集成的处置方法。当然,具体方法的采用也会因平台而异。不过值得注意的是,在根据问题创建重复性事件时,为了避免“淹没”事件管理系统。我们应当尽量少地使用集成,而尽量多地采用开箱即用的事件管理系统。对此,一些自动化的、智能化的事件去重方案,往往能够有效地解决此类问题。
转载请注明:IT运维空间 » 运维技术 » 通过有效的错误管理提高系统的鲁棒性
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-
oracle 常用select sql语句
-
JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/1.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值













发表评论