


1.序篇
本节是 flink sql 流 join 系列的下篇,上篇的链接如下:
flink sql 知其所以然之:流 join 很难嘛???(上)
废话不多说,咱们先直接上本文的目录和结论,小伙伴可以先看结论快速了解博主期望本文能给小伙伴们带来什么帮助:
- 背景及应用场景介绍:博主期望你能了解到,flink sql 提供的丰富的 join 方式(总结 6 种:regular join,维表 join,快照 join,interval join,array 拍平,table function)对我们满足需求提供了强大的后盾, 这 6 种 join 中涉及到流与流的 join 最常用的是 regular join 以及 interval join,本节主要介绍 interval join
- 来一个实战案例:博主以上节说到的曝光日志流点击日志流为案例展开,主要是想告诉小伙伴 flink sql left join 数据不会互相等待,存在 retract 问题,会导致写入 kafka 的数据量变大, 然后转变思路为使用 flink sql interval join 的方式可以使得数据互相等待一段时间进行 join,这种方式不会存在 retract 问题
- flink sql interval join 的解决方案以及原理的介绍:主要介绍 interval join 的在上述实战案例的运行结果及分析源码机制,博主期望你能了解到,interval join 的执行机制是会在你设置的 interval 区间之内互相等待一段时间,一旦时间推进(事件时间由 watermark 推进)到区间之外(即当前这条数据再也不可能被另一条流的数据 join 到时),outer join 会输出没有 join 到的数据,inner join 会从 state 中删除这条数据
- 总结及展望
2.背景及应用场景介绍
书接上文,上文介绍了曝光流在关联点击流时,使用 flink sql regular join 存在的 retract 问题。
本文介绍怎么使用 flink sql interval join 解决这些问题。
3.来一个实战案例
flink sql 知其所以然之流 join 很难嘛???(上)
看看上节的实际案例,来看看在具体输入值的场景下,输出值应该长啥样。
场景:即常见的曝光日志流(show_log)通过 log_id 关联点击日志流(click_log),将数据的关联结果进行下发。
来一波输入数据:
曝光数据:
| log_id | timestamp | show_params |
|---|---|---|
| 1 | 2021-11-01 00:01:03 | show_params |
| 2 | 2021-11-01 00:03:00 | show_params2 |
| 3 | 2021-11-01 00:05:00 | show_params3 |
点击数据:
| log_id | timestamp | click_params |
|---|---|---|
| 1 | 2021-11-01 00:01:53 | click_params |
| 2 | 2021-11-01 00:02:01 | click_params2 |
预期输出数据如下:
| log_id | timestamp | show_params | click_params |
|---|---|---|---|
| 1 | 2021-11-01 00:01:00 | show_params | click_params |
| 2 | 2021-11-01 00:01:00 | show_params2 | click_params2 |
| 3 | 2021-11-01 00:02:00 | show_params3 | null |
上节的 flink sql regular join 解决方案如下:
INSERTINTOsink_table SELECT show_log.log_idaslog_id, show_log.timestampastimestamp, show_log.show_paramsasshow_params, click_log.click_paramsasclick_params FROMshow_log LEFTJOINclick_logONshow_log.log_id=click_log.log_id;
上节说道,flink sql left join 在流数据到达时,如果左表流(show_log)join 不到右表流(click_log) ,则不会等待右流直接输出(show_log,null),在后续右表流数据代打时,会将(show_log,null)撤回,发送(show_log,click_log)。这就是为什么产生了 retract 流,从而导致重复写入 kafka。
对此,我们也是提出了对应的解决思路,既然 left join 中左流不会等待右流,那么能不能让左流强行等待右流一段时间,实在等不到在数据关联不到的数据即可。
当当当!!!
本文的 flink sql interval join 登场,它就能等。
4.flink sql interval join
4.1.interval join 定义
大家先通过下面这句话和图简单了解一下 interval join 的作用(熟悉 DataStream 的小伙伴萌可能已经使用过了),后续会详细介绍原理。
interval join 就是用一个流的数据去关联另一个流的一段时间区间内的数据。关联到就下发关联到的数据,关联不到且在超时后就根据是否是 outer join(left join,right join,full join)下发没关联到的数据。
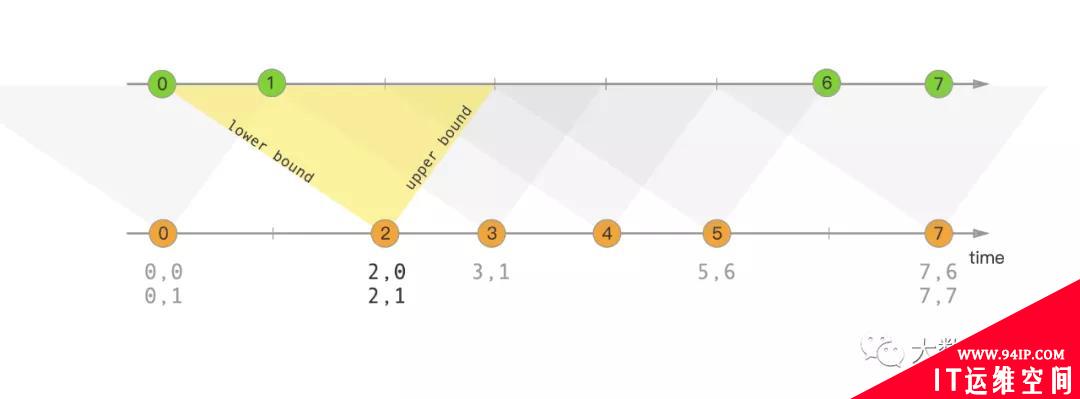
interval join
4.2.案例解决方案
来看看上述案例的 flink sql interval join sql 怎么写:
INSERTINTOsink_table SELECT show_log.log_idaslog_id, show_log.timestampastimestamp, show_log.show_paramsasshow_params, click_log.click_paramsasclick_params FROMshow_logLEFTJOINclick_logONshow_log.log_id=click_log.log_id ANDshow_log.row_time BETWEENclick_log.row_time-INTERVAL'10'MINUTE ANDclick_log.row_time+INTERVAL'10'MINUTE;
这里设置了 show_log.row_time BETWEEN click_log.row_time – INTERVAL ’10’ MINUTE AND click_log.row_time + INTERVAL ’10’ MINUTE代表 show_log 表中的数据会和 click_log 表中的 row_time 在前后 10 分钟之内的数据进行关联。
运行结果如下:
+[1|2021-11-0100:01:03|show_params|click_params] +[2|2021-11-0100:03:00|show_params|click_params] +[3|2021-11-0100:05:00|show_params|null]
如上就是我们期望的正确结果了。
flink web ui 算子图如下:

flink web ui
那么此时你可能有一个问题,结果中的前两条数据 join 到了输出我是理解的,那当 show_log join 不到 click_log 时为啥也输出了?原理是啥?
博主带你们来定位到具体的实现源码。先看一下 transformations。
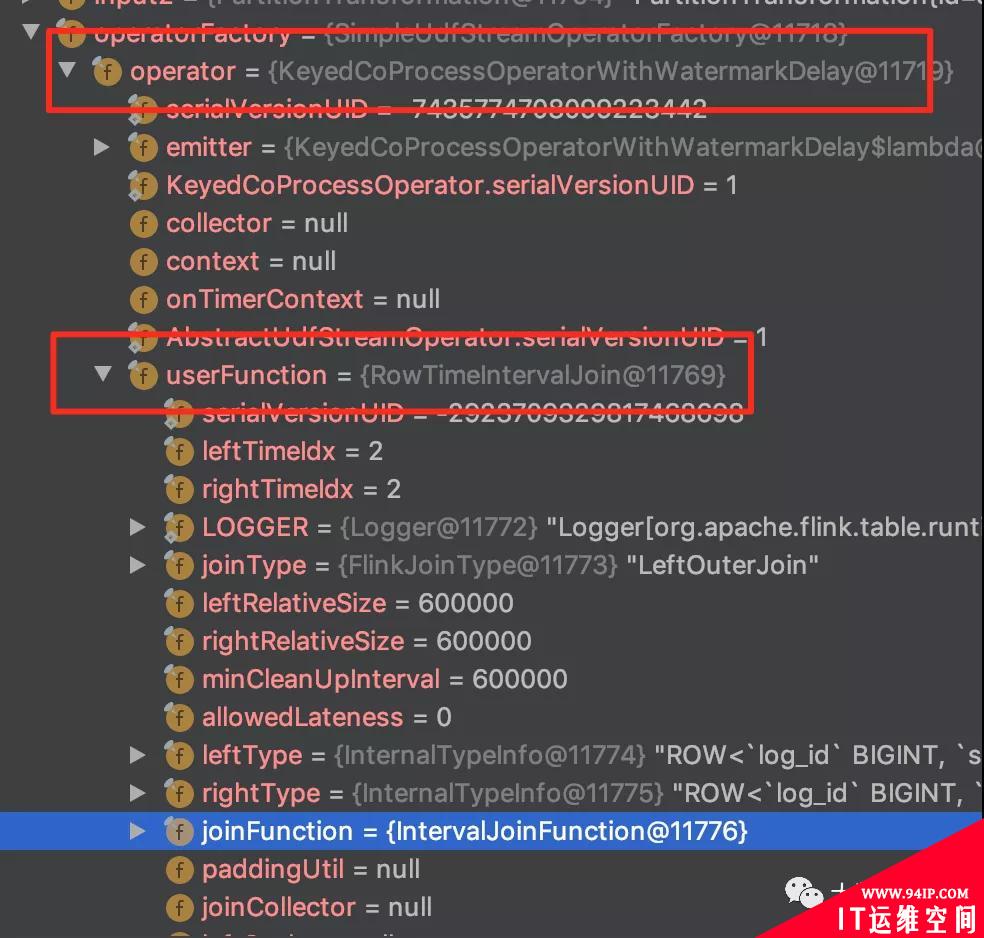
transformations
可以看到事件时间下 interval join 的具体 operator 是 org.apache.flink.table.runtime.operators.join.KeyedCoProcessOperatorWithWatermarkDelay。
其核心逻辑就集中在 processElement1 和 processElement2 中,在 processElement1 和 processElement2 中使用 org.apache.flink.table.runtime.operators.join.interval.RowTimeIntervalJoin 来处理具体 join 逻辑。RowTimeIntervalJoin 重要方法如下图所示。
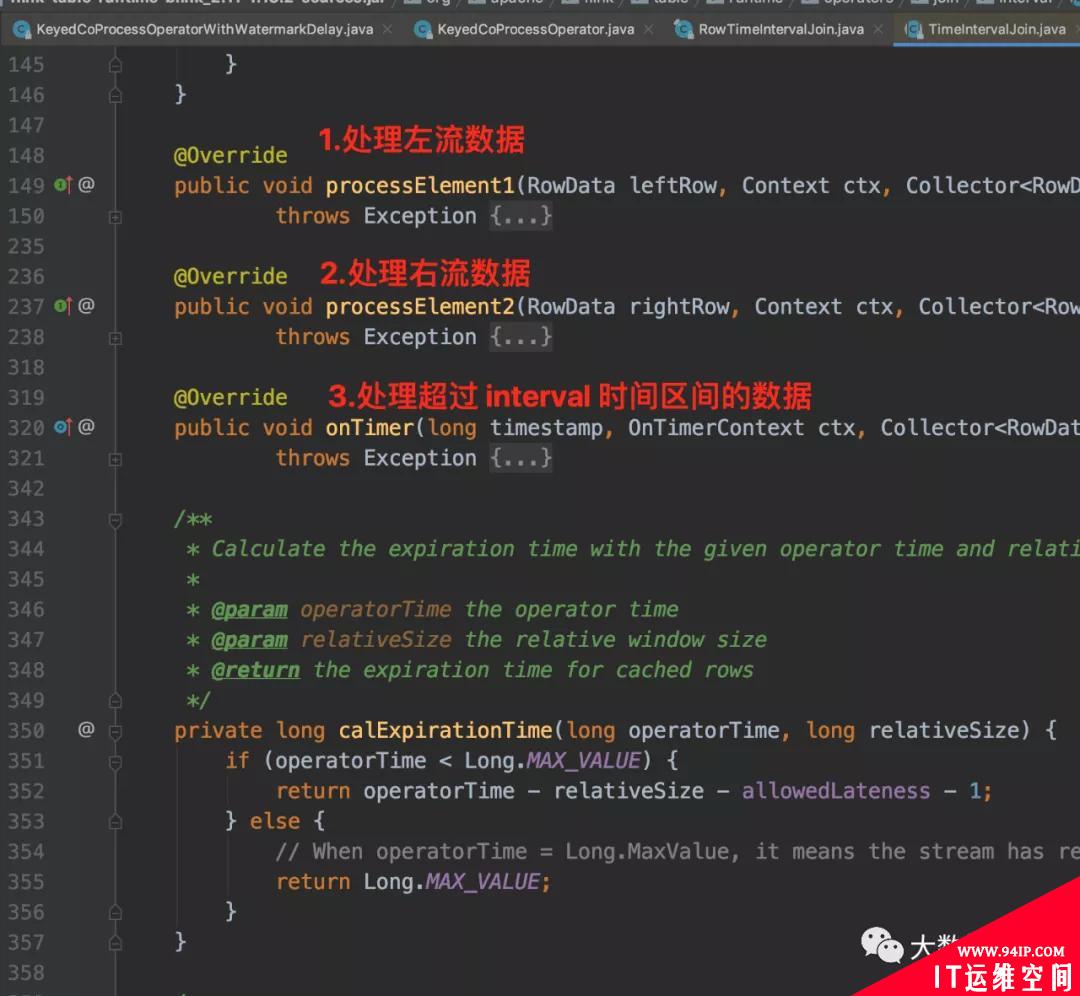
TimeIntervalJoin
下面详细给大家解释一下。
4.3.TimeIntervalJoin 简版说明
join 时,左流和右流会在 interval 时间之内相互等待,如果等到了则输出数据[+(show_log,click_log)],如果等不到,并且另一条流的时间已经推进到当前这条数据在也不可能 join 到另一条流的数据时,则直接输出[+(show_log,null)],[+(null,click_log)]。
举个例子,show_log.row_time BETWEEN click_log.row_time – INTERVAL ’10’ MINUTE AND click_log.row_time + INTERVAL ’10’ MINUTE, 当 click_log 的时间推进到 2021-11-01 11:00:00 时,这时 show_log 来一条 2021-11-01 02:00:00 的数据, 那这条 show_log 必然不可能和 click_log 中的数据 join 到了,因为 click_log 中 2021-11-01 01:50:00 到 2021-11-01 02:10:00 之间的数据以及过期删除了。则 show_log 直接输出 [+(show_log,null)]
Notes:
如果你设置了 allowLateness,join 不到的数据的输出和 state 的清理会多保留 allowLateness 时间
4.4.TimeIntervalJoin 详细实现说明
以上面案例的 show_log(左表) interval join click_log(右表) 为例(不管是 inner interval join,left interval join,right interval join 还是 full interval join,都会按照下面的流程执行):
第一步,首先如果 join xxx on 中的条件是等式则代表 join 是在相同 key 下进行的(上述案例中 join 的 key 即 show_log.log_id,click_log.log_id),相同 key 的数据会被发送到一个并发中进行处理。如果 join xxx on 中的条件是不等式,则两个流的 source 算子向 join 算子下发数据是按照 global 的 partition 策略进行下发的,并且 join 算子并发会被设置为 1,所有的数据会被发送到这一个并发中处理。
第二步,相同 key 下,一条 show_log 的数据先到达,首先会计算出下面要使用的最重要的三类时间戳:
- 根据 show_log 的时间戳(l_time)计算出能关联到的右流的时间区间下限(r_lower)、上限(r_upper)
- 根据 show_log 目前的 watermark 计算出目前右流的数据能够过期做过期处理的时间的最小值(r_expire)
- 获取左流的 l_watermark,右流的 r_watermark,这两个时间戳在事件语义的任务中都是 watermark
第三步,遍历所有同 key 下的 click_log 来做 join
- 对于遍历的每一条 click_log,走如下步骤
- 经过判断,如果 on 中的条件为 true,则和 click_log 关联,输出[+(show_log,click_log)]数据;如果 on 中的条件为 false,则啥也不干
- 接着判断当前这条 click_log 的数据时间(r_time)是否小于右流的数据过期时间的最小值(r_expire)(即判断这条 click_log 是否永远不会再被 show_log join 到了)。如果小于,并且当前 click_log 这一侧是 outer join,则不用等直接输出[+(null,click_log)]),从状态删除这条 click_log;如果 click_log 这一侧不是 outer join,则直接从状态里删除这条 click_log。
第四步,判断右流的时间戳(r_watermark)是否小于能关联到的右流的时间区间上限(r_upper):
- 如果是,则说明这条 show_log 还有可能被 click_log join 到,则 show_log 放到 state 中,并注册后面用于状态清除的 timer。
- 如果否,则说明关联不到了,则输出[+(show_log,null)]
第五步,timer 触发时:
- timer 触发时,根据当前 l_watermark,r_watermark 以及 state 中存储的 show_log,click_log 的 l_time,r_time 判断是否再也不会被对方 join 到,如果是,则根据是否为 outer join 对应输出[+(show_log,null)],[+(null,click_log)],并从状态中删除对应的 show_log,click_log。
上面只是左流 show_log 数据到达时的执行流程(即 ProcessElement1),当右流 click_log 到达时也是完全类似的执行流程(即 ProcessElement2)。
4.5.使用注意事项
小伙伴萌在使用 interval join 需要注意的两点事项:
interval join 的时间区间取决于日志的真实情况:设置大了容易造成任务的 state 太大,并且时效性也会变差。设置小了,join 不到,下发的数据在后续使用时,数据质量会存在问题。所以小伙伴萌在使用时建议先使用离线数据做一遍两条流的时间戳 diff 比较,来确定真实情况下的时间戳 diff 的分布是怎样的。举例:你通过离线数据 join 并做时间戳 diff 后发现 99% 的数据都能在时间戳相差 5min 以内 join 到,那么你就有依据去设置 interval 时间差为 5min。
interval join 中的时间区间条件即支持事件时间,也支持处理时间。事件时间由 watermark 推进。
5.总结与展望
源码公众号后台回复1.13.2 sql interval join获取。
本文主要介绍了 flink sql interval 是怎么避免出现 flink regular join 存在的 retract 问题的,并通过解析其实现说明了运行原理,博主期望你读完本文之后能了解到:
背景及应用场景介绍:博主期望你能了解到,flink sql 提供的丰富的 join 方式(总结 6 种:regular join,维表 join,快照 join,interval join,array 拍平,table function)对我们满足需求提供了强大的后盾, 这 6 种 join 中涉及到流与流的 join 最常用的是 regular join 以及 interval join,本节主要介绍 interval join
来一个实战案例:博主以上节说到的曝光日志流点击日志流为案例展开,主要是想告诉小伙伴 flink sql left join 数据不会互相等待,存在 retract 问题,会导致写入 kafka 的数据量变大, 然后转变思路为使用 flink sql interval join 的方式可以使得数据互相等待一段时间进行 join,这种方式不会存在 retract 问题
flink sql interval join 的解决方案以及原理的介绍:主要介绍 interval join 的在上述实战案例的运行结果及分析源码机制,博主期望你能了解到,interval join 的执行机制是会在你设置的 interval 区间之内互相等待一段时间,一旦时间推进(事件时间由 watermark 推进)到区间之外(即当前这条数据再也不可能被另一条流的数据 join 到时),outer join 会输出没有 join 到的数据,inner join 会从 state 中删除这条数据
总结及展望
转载请注明:IT运维空间 » 运维技术 » Flink SQL 知其所以然之流 Join 很难嘛???(下)
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-
JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值













发表评论