


在日常开发工作中,我们几乎需要天天与数据库打交道,作为一名只会CRUD的SQL BOY,除了每天用mybatis-generator自动生成DAO层代码之外,我们几乎不用去care数据库中如何处理并发请求,但是突然某一天MYSQL数据库告警了,出现了死锁,我们的内心慌的一匹,不禁想问:这不就是个普通查询吗,咋还锁起来了?
为了避免慌乱的表情被主管捕捉到,我们需要提前了解一下数据库中到底有哪些锁。
在MySQL中,其实将锁分成了两类:锁类型(lock_type)和锁模式(lock_mode)。锁类型描述的锁的粒度,也就是把锁具体加在什么地方;而锁模式描述的是到底加的是什么锁,是读锁还是写锁。锁模式通常和锁类型结合使用。
按锁的模式分
读锁
读锁,又叫共享锁/S锁/share locks。
读锁是某个事务(比如事务A)在进行读取操作(比如读一张表或者读取某一行)时创建出来的锁,其他的事务可以并发地读取这些数据(被加了锁的),但是不能修改这些数据(除非持有锁的用户已经释放锁)。
事务A对数据加上读锁之后,其他事务依然可以对其添加读锁(共享),但是不能添加写锁。
-
在记录上加读锁
InnoDB支持表锁和行锁,在行(也就是记录)上加锁,并不是锁住该条记录,而是在记录对应的索引上加锁。如果where条件中不走索引,则会对所有的记录加锁。
显式加锁语句为:
select*from{tableName}where{condition}lockinsharemode;
注意:这里所说的读,是指当前读,快照读是无需加锁的。普通select读一般都是快照读,除了select…lock in share mode这样的显式加锁语句下会变成当前读,在InnoDB引擎的serializable级别下,普通select读也会变成快照读。
另外需要注意,对于行锁的加锁过程分析,要根据事务隔离级别、是否使用索引(哪种类型的索引)、记录是否存在等因素结合分析,才能判断在哪里加上了锁。
innodb引擎中的加读锁的几种情形
1.普通查询在隔离级别为 serializable 会给记录加S锁。但这也取决于场景:非事务读(auto-commit)在 Serializable 隔离级别下,无需加锁;
Serializable隔离级别时:
-
如果查询条件为唯一索引且是唯一等值查询时:是在该条记录上加S锁;
-
非唯一条件查询(查询会扫描到多条记录时):记录本身+记录的间隙(需要具体分析间隙的范围),加S锁;
2.select … in share mode,会给记录加S锁,但是根据隔离级别的不同,加锁的行为有所不同:
RC隔离级别:是在记录上加S锁。
RR/Serializable隔离级别:
-
如果查询条件为唯一索引且是唯一等值查询时:是在该条记录上加S锁;
-
非唯一条件查询(查询会扫描到多条记录时):记录本身+记录的间隙(需要具体分析间隙的范围),加S锁;
3.通常insert操作是不加锁的,但如果在插入或更新记录时,检查到 duplicate key(或者有一个被标记删除的duplicate key),对于普通的insert/update,会加S锁,而对于类似replace into或者insert … on duplicate 这样的SQL语句加的是X锁。
4.insert … select 插入数据时,会对 select 的表上扫描到的数据加S锁;
5.外键检查:当我们删除一条父表上的记录时,需要去检查是否有引用约束,这时候会扫描子表上对应的记录,并加上S锁。
-
在表上加读锁
表锁由 MySQL服务器实现,无论存储引擎是什么,都可以使用表锁。一般在执行 DDL 语句时,譬如 ALTER TABLE 时就会对整个表进行加锁。在执行 SQL 语句时,也可以明确对某个表加锁。
给表显式加锁语句为:
#加表读锁
locktable{tableName}read;
#释放表锁
unlocktables;
#查看表锁
showopentable;
在使用MYISAM引擎时,通常我们不需要手动加锁,因为MYISAM引擎会针对我们的sql语句自动进行加锁,整个过程不需要用户干预:
1.查询语句(select):会自动给涉及的表加读锁;
2.更新语句(update、delete、insert):会自动给涉及的表加写锁。
写锁
写锁,排他锁/X锁/exclusive locks。写锁的阻塞性比读锁要严格的多,一个事务对数据添加写锁之后,其他的事务对该数据,既不能读取也不能更改。
与读锁加锁的范围相同,写锁既可以加在记录上,也可以加在表上。
-
在记录上加写锁
在记录上加写锁,引擎需要使用InnoDB。
通常普通的select语句是不会加锁的(隔离级别为Serializable除外),想要在查询时添加排他锁需要使用以下语句:
查询时加写锁:
select*from{tableName}where{condition}forupdate;
与加读锁相同,写锁也是加在索引上的。
更新时加写锁:
insert/update/delete语句,会自动在该条记录上加上排他锁
-
在表上加写锁
显式给表加写锁的语句为:
#加表写锁
locktable{tableName}write;
#释放表读锁
unlock
tables
;
当引擎选择myisam时,insert/update/delete语句,会自动给该表加上排他锁。
读写锁兼容性:
1.读锁是共享的,它不会阻塞其他读锁,但会阻塞其他的写锁;
2.写锁是排他的,它会阻塞其他读锁和写锁;
3.总结:读读不互斥,读写互斥,写写互斥
意向锁
意向锁是一种不与行级锁冲突的表级锁,表示表中的记录所需要的锁(S锁或X锁)的类型(其实就是告诉你,这张表中已经存在了行锁(行锁的类型),所以叫意向锁)。InnoDB支持多种粒度的锁,允许行级锁和表级锁的共存。
意向锁分为:
1.意向共享锁(IS锁):IS锁表示当前事务意图在表中的行上设置共享锁
下面语句执行时会首先获取IS锁,因为这个操作在获取S锁:获取S锁:select … lock in share mode
2.意向排它锁(IX锁):IX锁表示当前事务意图在表中的行上设置排它锁
下面语句执行时会首先获取IX锁,因为这个操作在获取X锁:获取X锁:select … for update
事务要获取某个表上的S锁和X锁之前,必须先分别获取对应的IS锁和IX锁。
意向锁有什么作用呢:
如果另一个事务试图在该表级别的共享锁或排它锁,则受到由第一个事务控制的表级别意向锁的阻塞。第二个事务在锁定该表前不必检查各个页或行锁,而只需检查表上的意向锁。
示例:表test_user
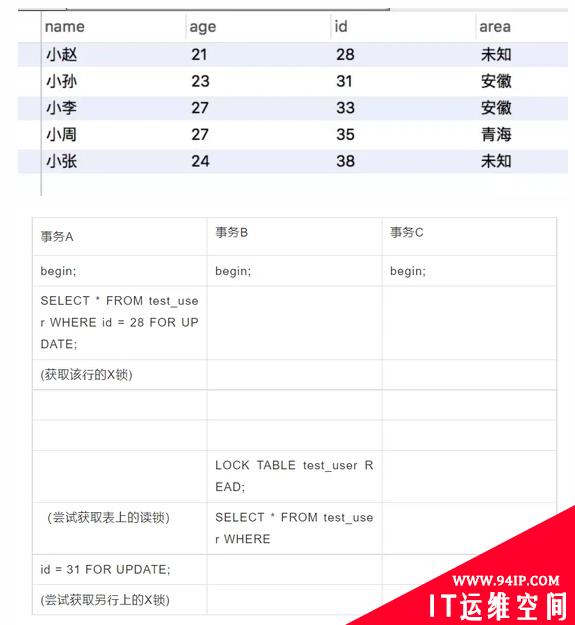
事务 A 获取了某一行的排他锁,并未提交;
事务 B 想要获取 test_user 表的表共享锁;
因为共享锁与排他锁互斥,所以事务 B 在试图对 test_user 表加共享锁的时候,必须保证:
1.当前没有其他事务持有 users 表的排他锁(表排他锁)。
2.当前没有其他事务持有 users 表中任意一行的排他锁(行排他锁)。
为了检测是否满足第二个条件,事务 B 必须在确保 test_user表不存在任何排他锁的前提下,去检测表中的每一行是否存在排他锁。很明显这是一个效率很差的做法,但是有了意向锁之后,情况就不一样了:
因为此时事务A获取了两把锁:users 表上的意向排他锁与 id 为 28 的数据行上的排他锁。
事务 B 想要获取 test_user 表的共享锁:
事务 B 只需要检测事务 A 是否持有 test_user 表的意向排他锁,就可以得知事务 A 必然持有该表中某些数据行的排他锁,那么事务 B 对 test_users 表的加锁请求就会被排斥(阻塞),从而无需去检测表中的每一行数据是否存在排他锁。
事务 C 也想获取 users 表中某一行的排他锁:
1.事务 C 检测到事务 A 持有 test_user 表的意向排他锁;
2.意向锁之间并不互斥,所以事务 C 获取到了 test_user 表的意向排他锁;
3.因为id 为 31 的数据行上不存在任何排他锁,最终事务 C 成功获取到了该数据行上的排他锁。
意向锁与意向锁之间是不互斥的,但是意向锁与其他表锁之间存在一定的兼容互斥,具体如下:
1.意向锁之间的兼容互斥性:
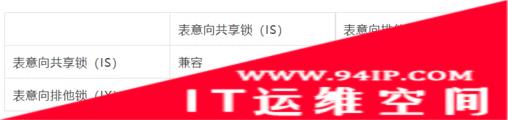
2.意向锁与普通的排他 / 共享锁互斥性:

自增锁
我们在设计表结构的时候,通常会把主键设置成自增长(思考一下为什么?)。
在InnoDB存储引擎中,针对每个自增长的字段都设置了一个自增长的计数器。我们可以执行下面的语句来得到这个计数器的当前值:
selectmax(自增长列)fromtable;
当我们进行插入操作的时候,该操作会根据这个自增长的计数器的当前值进行+1操作,并赋予自增长的列,这个操作我们称之为auto-inc Locking,也就是自增长锁,这种锁其实采用的是特殊的表锁机制,如果insert操作出现在一个事务中,这个锁是在insert操作完成之后立即释放,而不是等待事务提交。
按锁的类型分
全局锁
所谓全局锁,其实就是给整个数据库实例加锁。
数据库实例与数据库是有所区别的:
1.数据库,就是保存数据的仓库,具体到mysql中,数据库其实是一系列数据文件集合(也就是我们通常所说的database,比如创建数据库语句就是 create database…)。
2.数据库实例,是指访问数据库的应用程序,在Mysql中,就是mysqld进程了。
3.简单来理解,数据库实例中包含了你创建的各种数据库。
如果给数据库实例加全局锁会导致整个库处于只读状态(这是非常危险的)。
一般来说,全局锁的典型使用场景是用于全库备份,即把数据库中所有的表都select出来。但是要注意,让整个库都处于只读状态,会导致一些严重的问题:
1.在主库上加全局锁,在加锁期间,不能执行任何更新操作,业务基本上很多功能都不可用了;
2.在从库上加全局锁,在加锁期间,不能执行主从同步,会导致主从同步延迟。
全局锁的加锁语句是:
Flushtableswithreadlock
解除全局锁的方法是:
1.断开执行全局锁的session即可;
2.执行解锁sql语句:unlock tables;
如果需要个数据库备份的话,可以使用官方自带的逻辑备份工具mysqldump。
既然已经有了dump工具,为什么还需要 FTWRL 呢?一致性读是好,但前提是引擎要支持这个隔离级别。比如,MyISAM 这种不支持事务的引擎。这时,我们就需要使用 FTWRL 命令了。
FTWRL 前有读写的话,FTWRL 都会等待读写执行完毕后才执行。
FTWRL 执行的时候要刷脏页的数据到磁盘,因为要保持数据的一致性 ,所以执行FTWRL时候是所有事务都提交完毕的时候。
全局锁的实现还是依赖于元数据锁的。
元数据锁
元数据锁(MetaData Lock),也叫MDL锁,是用来保护元数据信息,系统级的锁无法主动控制。在MySQL5.5版本,开始引入MDL锁,主要是为了在并发环境下对DDL、DML同时操作下保持元数据的一致性。比如下面这种情况:
隔离级别:RR
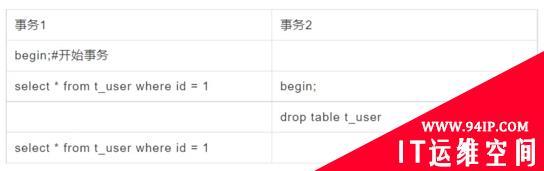
如果没有元数据锁的保护,那么事务2可以直接执行DDL操作,导致事务1出错。MYSQL5.5版本的时候加入 MDL 锁,是为了保护这种情况的发生。由于事务1开启了查询,那么获得了元数据锁,锁的模式为MDL读锁,事务2要执行DDL,则需获得 MDL 写锁,由于读写锁互斥,所以事务2需要等待事务1释放掉读锁才能执行。
1.对表中的记录进行增删改查(DML操作)的时候,自动加MDL读锁;
2.对表的结构(DDL操作)进行修改的时候,自动加MDL写锁。
-
MDL 锁的粒度
MDL锁是Mysql服务器层面中实现的,而不是在存储引擎插件中实现。按照锁定的范围,MDL锁可以分为以下几类:
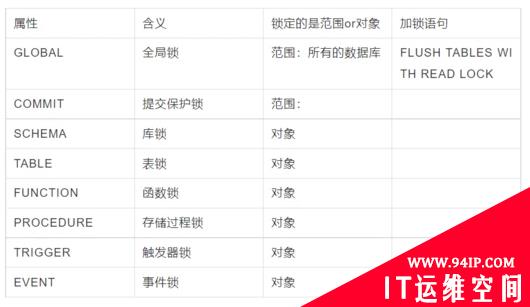
-
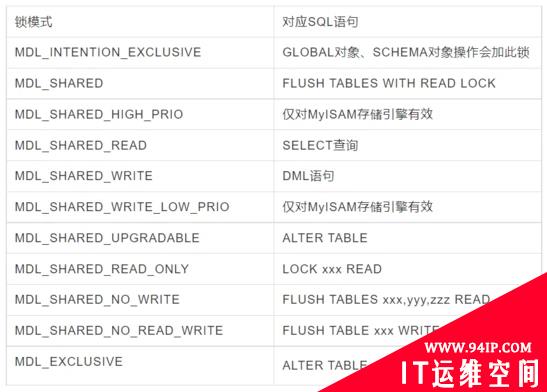
MDL 锁的模式
页级锁
MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。不同的存储引擎支持不同的锁机制。根据不同的存储引擎,MySQL中锁的特性可以大致归纳如下:
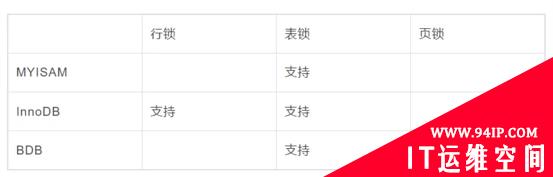
页级锁是MySQL中比较独特的一种锁定级别,应用于BDB引擎,并发度一般,页级锁定的特点是锁定颗粒度介于行级锁定与表级锁之间,所以获取锁定所需要的资源开销,以及所能提供的并发处理能力也同样是介于上面二者之间。另外,页级锁定和行级锁定一样,会发生死锁。
锁定粒度大小比较:表级锁 > 页级锁 > 行级锁
表级锁
表锁在上文我们已经介绍过,相比于行锁的细粒度加锁,表锁是对整张表加锁。由于是对整张表加锁,就没有行锁的加锁方式那么复杂,所以加锁比行锁快,而且不会出现死锁的情况(因为事务是一次性获取想要加的表表锁),但是表锁也存在一些问题:锁的范围过大,在并发比较高的情况下,会导致抢锁的冲突概率变高,这样并发性能就大打折扣了。
-
表锁的加锁方式
引擎选择MYISAM时
MYISAM引擎只支持表锁,不支持行锁。
手动添加表级锁的语句如下:
1、加表读锁:locktable{tableName}read;
2、加表写锁:locktable{tableName}write;
3、释放表锁:unlocktables;或者客户端断开连接也也会自动释放锁
在使用MYISAM引擎时,通常我们不需要手动加锁,因为MYISAM引擎会针对我们的sql语句自动进行加锁,整个过程不需要用户干预:
1.查询语句(select):会自动给涉及的表加读锁;
2.更新语句(update、delete、insert):会自动给涉及的表加写锁
引擎选择InnoDB时
InnoDB引擎同时支持行级锁和表级锁,默认为行级锁。
给InnoDB引擎的表手动加锁,也同样使用 lock table {tableName} read/write 语句进行读/写锁的添加。
除此之外,innodb还支持一种表级锁:意向锁(上文已经介绍过)。
总的来说,InnoDB引擎的表级锁包含五种锁模式:
1.LOCK_IS:表意向读锁
2.LOCK_IX:表意向写锁
3.LOCK_S:表读锁
4.LOCK_X:表写锁
5.LOCK_AUTO_INC:自增锁
行级锁
在编写业务代码的过程中,我们接触最多的就是行级锁了(表级锁由于性能问题,一般不推荐使用)。相比于表级锁,行级锁具有明显的性能优势:
1.冲突少:多线程中访问不同的记录时只存在少量锁定冲突;
2.锁的粒度小:可以长时间锁定单一的行,对其他的行没有影响,所以并发度是最高的;
但是使用行锁时,一旦稍不注意,是非常容易出现死锁的(表锁就不存在死锁现象),所以使用行锁需要注意加锁的顺序和锁定的范围。
InnoDB的行锁是通过对索引项加锁实现的,这表示只有通过索引查询记录时才会使用行锁,如果不走索引查询数据将使用表锁,则性能会大打折扣。
需要记住:行锁也叫记录锁,记录锁都是加在索引上的。
1.where条件指定的是主键索引:则在主键索引上加锁;
2.wehre条件指定的是二级索引:记录锁不仅会加在这个二级索引上,还会加在这个二级索引所对应的聚簇索引上;
3.where条件如果无法走索引:MySQL会给整张表所有数据行加记录锁,存储引擎层将所有记录返回由MySQL服务端进行过滤。
行级锁的几种类型:
-
记录锁:LOCK_REC_NOT_GAP(只锁记录)
记录锁是最简单的行锁。比如在RR隔离级别时,执行 select * from t_user where id = 1 for update 语句时,实际上是对 id = 1 (这里id为主键)这条记录上锁(锁加在聚簇索引上)。
记录锁永远都是加在索引上的,就算一个表没有建索引,数据库也会隐式的创建一个索引。如果 WHERE 条件中指定的列是个二级索引,那么记录锁不仅会加在这个二级索引上,还会加在这个二级索引所对应的聚簇索引上。
注意,如果 SQL 语句无法使用索引时会走主索引实现全表扫描,这个时候 MySQL 会给整张表的所有数据行加记录锁。
如果一个 WHERE 条件无法通过索引快速过滤,存储引擎层面就会将所有记录加锁后返回,再由 MySQL Server 层进行过滤。在没有索引时,不仅会消耗大量的锁资源,增加数据库的开销,而且极大的降低了数据库的并发性能,所以说,更新操作一定要记得走索引(因为更新操作会加X锁)。
-
间隙锁:LOCK_GAP(只锁间隙)
间隙锁是一种区间锁。锁加在不存在的空闲空间上,或者两个索引记录之间,或者第一个索引记录,或者最后一个索引之后的空间,用来表示只锁住一段范围(一般在进行范围查询时且隔离级别在RR或Serializable隔时)。
一般在RR隔离级别下会使用到GAP锁。使用GAP锁,主要是为了防止幻读产生,在被GAP锁锁住的区间,不允许插入数据或者更新数据。
间隙锁的产生条件:innodb的隔离级别为 Repeatable Read 或者 Serializable。
间隙锁的作用范围说明:
隔离级别:RR
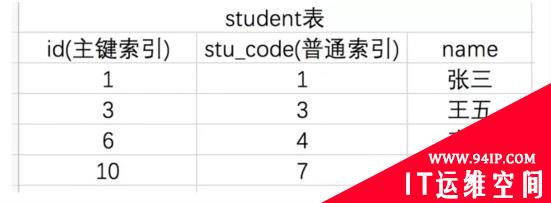
以Student表作为样例数据,id为主键,stu_code为学生编号,添加普通索引。
间隙锁区域定义:
1.根据检索条件向左寻找最靠近的值A,作为左区间,向右寻找最靠近的值B,作为右区间,间隙锁为(A,B)
2.向左找不到最近的值A,也是就无穷小,作为左区间,向右寻找最靠近的值B,作为右区间,间隙锁为(无穷小,B)
3.向左找到最近的值A,作为左区间,向右寻找不到最近的值B,也就是无穷大,作为右区间,间隙锁为(A,无穷大)
区间(A,B)示例:
事务1:
select*fromstudentwherestu_code=4forupdate
事务2:
insertintostudentvaues(2,2,’A’);
insertintostudentvalues(4,5,’B’);
根据事务1的sql语句分析,间隙锁的范围是:stu_code = 4记录是存在的,所以左区间为最近的索引值为stu_code = 3,右区间为最近的索引值为stu_code =7,所以间隙范围为:(3,7),因此事务2的两个insert 语句,一个在范围外,一个在范围内,在范围外的能插入,而范围内的则阻塞,所以(2,2, ‘A’)能插入成功;(4,5, ‘B’)插入阻塞。
区间(无穷小,B)示例:
事务1:
select*fromstudentwherestu_code=1forupdate
事务2:
insertintostudentvaues(2,0,’c’);
insertintostudentvaues(2,2,’r’);
insertintostudentvaues(5,2,’o’);
根据事务1的sql语句分析,间隙锁的范围是:stu_code = 1 是存在的,左边最近没有记录,所以是左边的无穷小,右边最近的索引值为 stu_code = 3,所以间隙锁范围为:(无穷小,3)。所以事务2的第一个和第二个insert sql语句执行被阻塞,是在间隙锁范围内的。第三个insert sql语句能执行成功,不在间隙锁范围内。
区间(A,无穷大)示例:
事务1:
select*fromstudentwherestu_code=7forupdate
事务2:
insertintostudentvaues(2,2,’m’);
insertintostudentvaues(20,22
‘j’
);
根据事务1的sql语句分析,间隙锁的范围是:stu_code = 7 是存在的,左边最近的索引值为 stu_code = 4,而右边是没有索引值的,所以间隙锁的范围为:(4,无穷大),第一个inset语句能执行成功,不在间隙范围内;第二个insert语句执行被阻塞,是在间隙锁范围内的。
如果查询语句在数据库中没有记录,那该怎么锁呢?
以上是查询是有记录的,如果查询语句在数据库中没有记录,那该怎么锁呢?咱们继续往下:
事务1:
updatestudentsetstu_name=’000’wherestu_code=10
事务2:
insertintostudentvaues(2,2,’m’);
insertintostudentvaues(20,22,’j’);
根据上面的执行语句是找不到记录的,向左取最近的记录(10,7,‘小明’)作为左区间,即间隙锁的范围是:(7, 无穷大),第一个insert语句不在区间范围内,能执行成功;第二个insert执行语句在区间内被阻塞,执行失败。如果事务1的where 条件是大于10,也是向左找最近的记录值作为左区间,所以间隙锁的范围也是:(7, 无穷大)
总结:间隙锁产生的条件
RR/Serializable隔离级别下:Select … Where…For Update 时:
1.只使用唯一索引查询,并且只锁定一条记录时,InnoDB会使用行锁。
2.只使用唯一索引查询,但是检索条件是范围检索,或者是唯一检索然而检索结果不存在(试图锁住不存在的数据)时,会产生 Next-Key Lock。
3.使用普通索引检索时,不管是何种查询,只要加锁,都会产生间隙锁。
4.同时使用唯一索引和普通索引时,由于数据行是优先根据普通索引排序,再根据唯一索引排序,所以也会产生间隙锁。
-
下一键锁:LOCK_ORDINARY,也称Next-Key Lock
Next-Key锁是 record lock + gap lock 的组合。和间隙锁一样,在 RC 隔离级别下没有 Next-key 锁(除非通过修改配置强制开启),只有 RR/Serializable隔离级别才有。
MySQL InnoDB工作在可重复读隔离级别(RR)下,并且会以Next-Key Lock的方式对数据行进行加锁,这样可以有效防止幻读的发生。Next-Key Lock是行锁和间隙锁的组合,当InnoDB扫描索引记录的时候,会首先对索引记录加上行锁(Record Lock),再对索引记录两边的间隙加上间隙锁(Gap Lock)。加上间隙锁之后,其他事务就不能在这个间隙修改或者插入记录。
当查询的索引含有唯一属性(唯一索引,主键索引)时,Innodb存储引擎会对next-key lock进行优化,将其降为record lock,即仅锁住索引本身,而不是范围。
-
插入意向锁:LOCK_INSERT_INTENSION
插入意向锁,插入记录时使用,是一种特殊的间隙锁。这个锁表示插入的意向,只有在执行insert语句的时候才会有这个锁。
假设有索引记录的值分别是id = 1和id = 5(1到5之间没有记录),单独的事务分别尝试插入id = 2和 id = 3,在获得插入行的排它锁之前,每个事务都是用插入意图锁来锁定1和5之间的空间,但是不会相互阻塞。因为插入意向锁之间是不会冲突的。
插入意向锁会跟间隙锁或者Next-Key锁冲突:间隙锁的作用是锁住区间防止其他事务插入数据导致幻读。
在上面的场景中,假设提前有事务A获取了id 在(1,5)区间的间隙锁,那么事务B尝试插入 id = 2时,会先尝试获取插入意向锁,但是由于插入意向锁和间隙锁冲突,导致插入失败,也就避免了幻读产生。
结语
MYSQL的锁机制非常复杂,在实际的开发工作中,对于隔离级别的设置都需要非常谨慎,比如RR级别会比RC级别多出一个间隙锁,这就可能导致严重的性能问题。本文从锁的模式和锁的范围对MYSQL锁的分类进行了简单介绍,希望我们在面向数据库开发的过程中,能够仔细分析研究我们的SQL语句是否合理(尤其需要注意是否会产生死锁等问题)!
转载请注明:IT运维空间 » 运维技术 » MYSQL 中锁的各种模式与类型
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/2.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值











发表评论