


Buffer Pool 缓冲池回顾
在讲插入缓冲这个振奋人心的 InnoDB 新特性之前,我们有必要先来回顾下 Buffer Pool(缓存池)的概念。
前文说过,InnoDB 存储引擎是基于磁盘存储的,并将其中的记录按照页的方式进行管理。因此可将其视为基于磁盘的数据库系统(Disk-base Database)。为了缓解 CPU 与磁盘速度之间的矛盾,基于磁盘的数据库系统通常使用缓冲池技术来提高数据库的整体性能。
缓冲池其实就是一块内存区域,没什么特别的。
- 对于数据库中页的读取操作,首先会将从磁盘读到的页存放在缓冲池中,这个过程也称为将页 FIX 在缓冲池中。这样,下一次再读相同的页时,如果该页是否在缓冲池中,则直接读取该页就行了,不用去磁盘上读取。
- 对于数据库中页的修改操作,则首先修改在缓冲池中的页,然后再以一定的频率刷新到磁盘上。
简单来说,缓冲池就是通过内存的速度来弥补磁盘速度较慢对数据库性能的影响。
当然了,缓冲池毕竟不是无限大的,不能把所有的数据都存在缓冲池上面,InnoDB 通过一种称为 Checkpoint 的机制来决定哪些数据该从缓冲池移出去(移到磁盘上),这个在前面文章中我们也解释过啦,遗忘的小伙伴可以翻看下前文。
Insert Buffer 插入缓冲
Insert Buffer 这个名字可能会让小伙伴们认为它是 Buffer Pool 中的一个组成部分。其实不然,Insert Buffer 是物理页的一个组成部分,是一颗 B+ 树,页是存在磁盘中的,而 Buffer Pool 它是一块内存区域。
不过,需要注意的是,Buffer Pool 中会包含 Insert Buffer 的某些信息,来看下 InnoDB 存储引擎的内存结构:
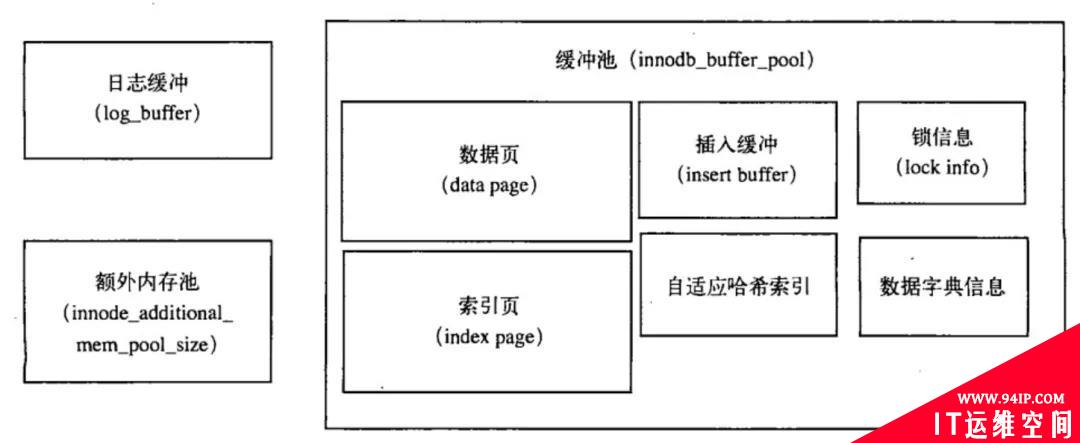
可以看到,Innodb Buffer Pool 包含的数据页类型有:索引页,数据页,undo 页,Insert Buffer,自适应哈希索引,锁信息,数据字典信息等。
以问题为导向,对于 Insert Buffer,我们需要弄清楚的其实就 2 个问题:
- Insert Buffer 能解决什么问题?
- 什么情况下能够使用 Insert Buffer?
通常,我们在建表的时候,都会给主键定一个自增长(AUTO_INCREMENT)的特性,也即主键按照递增的顺序进行插入。上篇文章讲过,聚集索引一般建立在主键上面,也就是说,插入聚集索引一般是顺序的,不需要经过磁盘的随机读取。
举个例子:
CREATETABLEuser( idINT(11)AUTO_INCREMENT, usernameVARCHAR(30), PRIMARYKEY(id) );
id 是自增长的主键,我们在插入一个新的行记录的时候,无须对 id 赋值或者说赋 NULL 值,存储引擎会帮助我们将这个值自动增长。
同时页中的行记录是按照主键 id 的值进行顺序存放的,所以,在我们插入新的行记录的时候,一般来说磁盘是不需要去随机读取另一个页中的记录的,因此速度非常快。
当然了,并不是说所有的主键插入都是顺序的。有些业务场景下可能需要用 UUID 这种作为主键,即使它被定义了自增长类型,如果每次插入的都是通过 UUID 生成的指定值,而不是 NULL,那么显然它的插入就是随机的了。
这样分析下来似乎我们的插入性能会比较好,但是,不可能一张数据库表上只有一个聚集索引吧,还有其他的辅助索引呢。事实上,辅助索引也确实是影响插入性能的关键。
举个例子,我们定义一个非聚集的且不是唯一的索引 username:
CREATETABLEuser( idINT(11)AUTO_INCREMENT, usernameVARCHAR(30), PRIMARYKEY(id), key(username) );
在进行插入操作时,数据页的存放确实还是按自增长的主键 id 来进行顺序存放的,这没错。
但是,索引的本质是什么?是 B+ 树,是一个存在磁盘上的物理文件。那我们在构建辅助索引 username 的这棵 B+ 树的时候,非聚集索引叶子节点的插入不再是顺序的了,也就是说要去离散地访问磁盘页了。
正是由于随机读取的存在导致了插入操作性能下降。
和 “不是所有的主键插入都是顺序的” 类似,在某些情况下,辅助索引的插入可能也是顺序的,或者说是比较有顺序的。
比如用户表中有一个时间字段,用来表示用户买下某个物品的时间。在通常情况下,用户购买时间是一个辅助索引,用来根据时间条件进行查询。但是在插入时却是根据时间的递增而插入的,因此插入也是比较有顺序的。
至此,讲了半天好像还没有看见 Insert Buffer 的影子?
别急,这就来。
InnoDB 存储引擎开创性地设计了 Insert Buffer。对于辅助索引的插入或更新操作,并不是每一次直接插入到索引页(磁盘页)中,而是先判断插入的辅助索引页是否在 Buffer Pool 中:
- 若在,则直接插入;
- 若不在,则先将其放入到一个 Insert Buffer 对象中,就好像骗了数据库一波:告诉数据库这个辅助索引的叶子节点了已经插入成功了(磁盘上),但是实际上并没有,只是存放在内存里的 Insert Buffer 中。
当然,不能将这个叶子节点一直存在 Insert Buffer 中,对吧,这个辅助索引的 B+ 树终归还是得建立起来的。具体来说,InnoDB 会以一定的频率和情况进行 Insert Buffer 和辅助索引页子节点的 Merge(合并)操作,这时,就相当于将多个叶子节点插入操作合并到一个操作中(因为在一个索引页中),这就大大提高了对于辅助索引插入性能
简单概括下:Insert Buffer 就是一棵 B+ 树,若需要实现插入记录的辅助索引页不在 Buffer Pool 中,那么需要将辅助索引记录首先插入到这棵 B+ 树中,然后在适当的情况下将其合并(Merge)到真正的辅助索引中。
举个现实生活中的例子来说:
我们去图书馆还书,对于图书馆管理员来说,他需要做的就是 insert 操作,管理员在 1 小时内接受了 100 本书,这时候他有 2 种做法把还回来的书归位到书架上:
- 每还回来一本书,就把这本书送回架上
- 暂时不做归位操作,等到空闲下来了,再把这些书一次性送回书架上
用方法 1,管理员需要进出图书管 100 次,不停的登高爬低完成图书归位操作,累死累活,效率很差。
用方法 2,管理员只需要对要归位的书进行一个分类,进出图书管 1 次,对同一个位置的书,不管多少,都只要爬一次楼梯,大大减轻了管理员的工作量。
那么,什么条件下可以使用 Insert Buffer 以此来提高插入操作的性能呢?
- 索引是辅助索引
- 索引不是唯一索引
为什么 Insert Buffer 不适用于唯一的辅助索引呢?
一个很简单的套娃问题(滑稽):
如果辅助索引是唯一的,那么当把要插入的对象存到 Insert Buffer 时,数据库就需要去磁盘上查找索引页来判断插入记录的唯一性,显然,如果去查找就会有离散读取的情况发生,从而导致 Insert Buffer 失去了意义。
还以图书管那个例子来说:
如果图书馆中所有的书只允许存在一本,那我们还一本书到图书馆的时候,管理员就必须爬到图书管的指定位置去确认判断一下这本书是不是唯一的,这个过程就相当于产生了一次 IO 操作了。
另外,Insert Buffer 有利有弊,考虑一种极端情况:
如果数据库中涌入了大量的插入操作,并且这些都涉及了不唯一的非聚集索引,也就是使用了 Insert Buffer。若此时数据库崩溃了,这时势必有大量的 Insert Buffer 没有被合并到实际的辅助索引中去,那么这时候的恢复就可能需要很长的时间。
Change Buffer
InnoDB 从 1.0.x 版本开始引入了 Change Buffer,现在有些博客上说的也是 Change Buffer,容易让小白懵逼,其实就是 Insert Buffer 的升级版。
从这个版本开始,InnoDB 存储引擎可以对 DML 操作 — INSERT、DELETE、UPDATE 都进行缓冲,他们分别对应的是:Insert Buffer、Delete Buffer、Purge buffer
同样的,和之前 Insert Buffer 一样,Change Buffer 适用的对象依然是非唯一的辅助索引。
对一条记录进行 UPDATE 操作可能分为两个过程:
- 将记录标记为已删除:对应 Delete Buffer
- 真正将记录删除:对应 Purge Buffer
转载请注明:IT运维空间 » 运维技术 » 不知道 Insert Buffer 的请举手
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/1.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值












发表评论