


CRI shim是什么?
实现了 CRI 接口的容器运行时通常称为 CRI shim, 这是一个 gRPC Server,监听在本地的 unix socket 上;而 kubelet 作为 gRPC 的客户端来调用 CRI 接口,来进行 Pod 和容器、镜像的生命周期管理。另外,容器运行时需要自己负责管理容器的网络,推荐使用 CNI。
kubelet 调用下层容器运行时的执行过程,并不会直接调用Docker 的 API,而是通过一组叫作 CRI(Container Runtime Interface,容器运行时接口)的 gRPC 接口来间接执行的,意味着需要使用新的连接方式与 docker 通信,为了兼容以前的版本,k8s 提供了针对 docker 的 CRI 实现,也就是kubelet包下的dockershim包,dockershim是一个 grpc 服务,监听一个端口供 kubelet 连接,dockershim收到 kubelet 的请求后,将其转化为 REST API 请求,再发送给docker daemon。Kubernetes 项目之所以要在 kubelet 中引入这样一层单独的抽象,当然是为了对 Kubernetes 屏蔽下层容器运行时的差异。

解决思路再次体现了《代码大全2》里提到的那句经典名言:any problem in computer science can be sloved by another layer of indirecition。计算机科学领域的任何问题都可以通过增加一个中间层来解决,我们的 CRI shim就是加了这样一层。
CRI shim server 接口图示
**CRI 接口包括 RuntimeService 和 ImageService 两个服务,这两个服务可以在一个 gRPC server 中实现,也可以分开成两个独立服务。**目前社区的很多运行时都是将其在一个 gRPC server 里面实现。
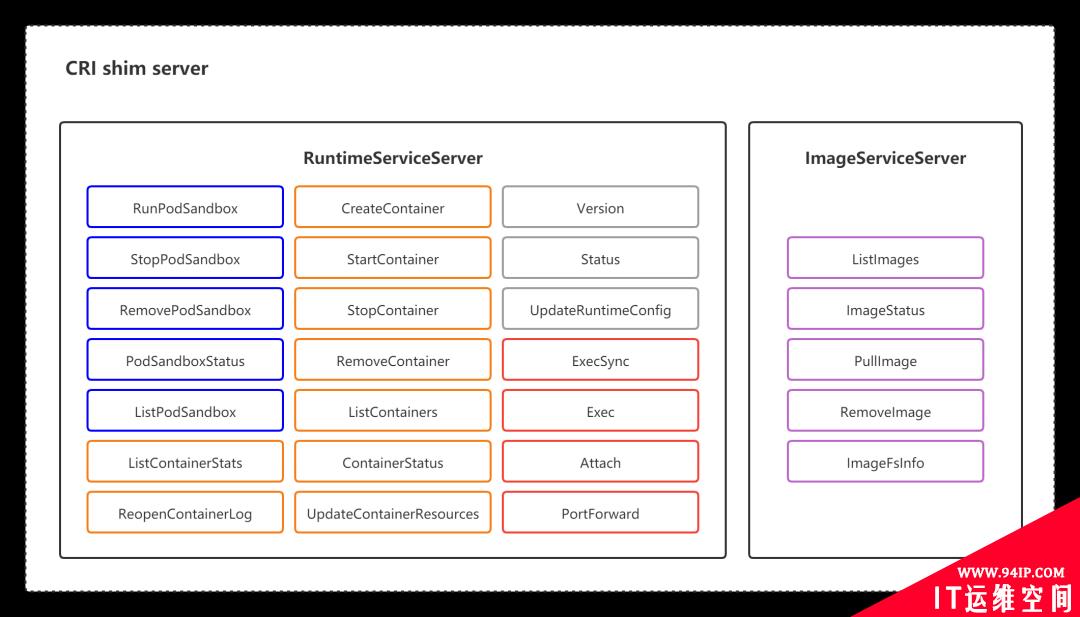
ImageServiceServer 提供了 5 个接口,用于管理容器镜像。管理镜像的 ImageService 提供了 5 个接口:
- 查询镜像列表;
- 拉取镜像到本地;
- 查询镜像状态;
- 删除本地镜像;
- 查询镜像占用空间等。
关于容器镜像的操作比较简单,所以我们就暂且略过。接下来,我主要为你讲解一下 RuntimeService 部分。RuntimeService 则提供了更多的接口,按照功能可以划分为四组:
- PodSandbox 的管理接口:CRI 设计的一个重要原则,就是确保这个接口本身,只关注容器,不关注 Pod。
- PodSandbox 是对 Kubernete Pod 的抽象,用来给容器提供一个隔离的环境(比如挂载到相同的 CGroup 下面),并提供网络等共享的命名空间。PodSandbox 通常对应到一个 Pause 容器或者一台虚拟机;
- Container 的管理接口:在指定的 PodSandbox 中创建、启动、停止和删除容器;
- Streaming API 接口:包括 Exec、Attach 和 PortForward 等三个和容器进行数据交互的接口,这三个接口返回的是运行时 Streaming Server 的 URL,而不是直接跟容器交互。kubelet 需要跟容器项目维护一个长连接来传输数据。这种 API,我们就称之为 Streaming API。
- 状态接口:包括查询 API 版本和查询运行时状态。
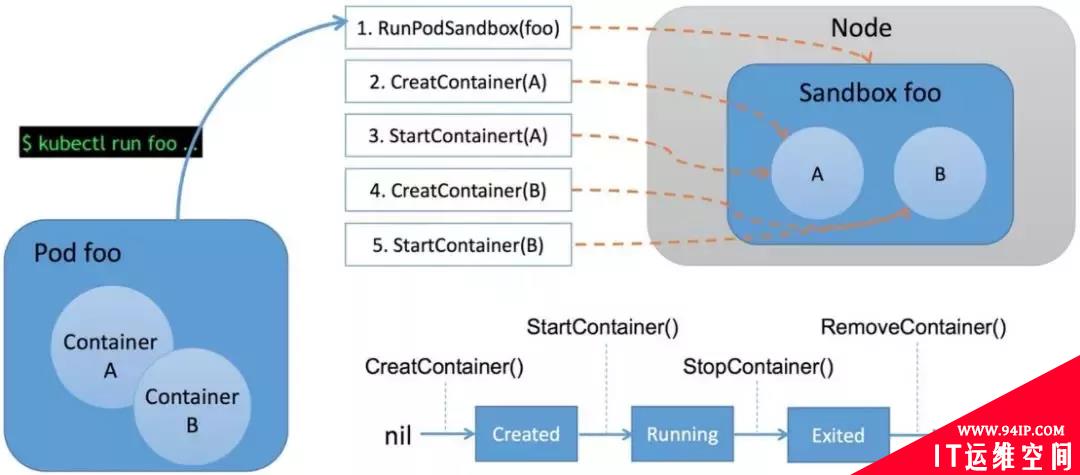
我们通过 kubectl 命令来运行一个 Pod,那么 Kubelet 就会通过 CRI 执行以下操作:
- 首先调用 RunPodSandbox 接口来创建一个 Pod 容器,Pod 容器是用来持有容器的相关资源的,比如说网络空间、PID空间、进程空间等资源;
- 然后调用 CreatContainer 接口在 Pod 容器的空间创建业务容器;
- 再调用 StartContainer 接口启动运行容器
- 最后调用停止,销毁容器的接口为 StopContainer 与 RemoveContainer。
就完成了整个Container的生命周期。
Streaming API
CRI shim 对 Streaming API 的实现,依赖于一套独立的 Streaming Server 机制。Streaming API 用于客户端与容器进行交互,包括 Exec、PortForward 和 Attach 等三个接口。kubelet 内置的 Docker 通过 nsenter、socat 等方法来支持这些特性,但它们不一定适用于其他的运行时,也不支持 Linux 之外的其他平台。因而,CRI 也显式定义了这些 API,并且要求容器运行时返回一个 Streaming Server 的 URL 以便 kubelet 重定向 API Server 发送过来的流式请求。
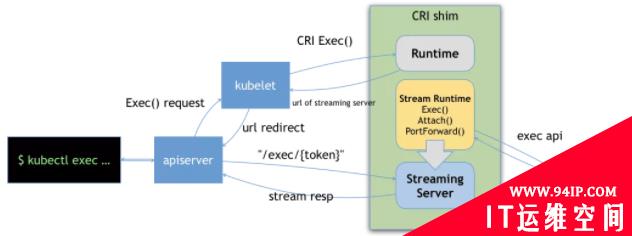
因为所有容器的流式请求都会经过 kubelet,这可能会给节点的网络流量带来瓶颈,因而 CRI 要求容器运行时启动一个对应请求的单独的流服务器,将地址返回给 kubelet。kubelet 将这个信息再返回给 Kubernetes API Server,会直接打开与运行时提供的服务器相连的流连接,并通过它与客户端连通。
这样一个完整的 Exec 流程就如上图所示,分为多个阶段:
- 客户端 kubectl exec -i -t …;
- kube-apiserver 向 kubelet 发送流式请求 /exec/;
- kubelet 通过 CRI 接口向 CRI Shim 请求 Exec 的 URL;
- CRI Shim 向 kubelet 返回 Exec URL;
- kubelet 向 kube-apiserver 返回重定向的响应;
- kube-apiserver 重定向流式请求到 Exec URL,然后将 CRI Shim 内部的 Streaming Server 跟 kube-apiserver 进行数据交互,完成 Exec 的请求和响应。
也就是说 apiserver 其实实际上是跟 streaming server 交互来获取我们的流式数据的。这样一来让我们的整个 CRI Server 接口更轻量、更可靠。
注意:当然,这个 Streaming Server 本身,是需要通过使用 SIG-Node 为你维护的 Streaming API 库来实现的。并且,Streaming Server 会在 CRI shim 启动时就一起启动。此外,Stream Server 这一部分具体怎么实现,完全可以由 CRI shim 的维护者自行决定。比如,对于 Docker 项目来说,dockershim 就是直接调用 Docker 的 Exec API 来作为实现的。
CRI-containerd架构解析与主要接口解析
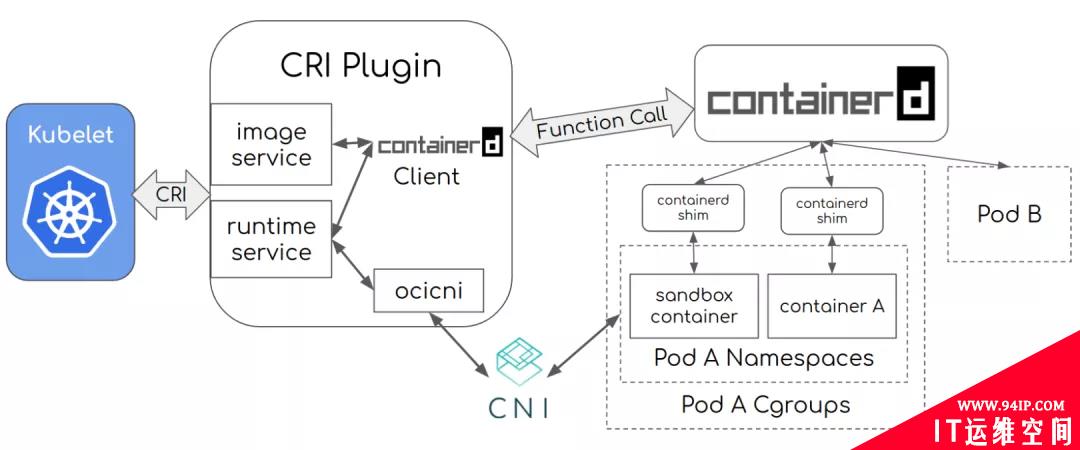
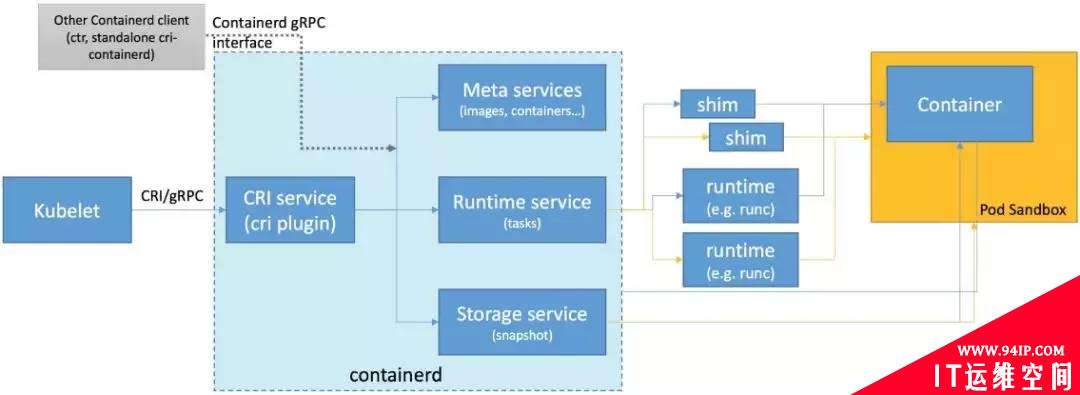
整个架构看起来非常直观。这里的 Meta services、Runtime service 与 Storage service 都是 containerd 提供的接口。它们是通用的容器相关的接口,包括镜像管理、容器运行时管理等。CRI 在这之上包装了一个 gRPC 的服务。右侧就是具体的容器的实现。比如说,创建容器时就要创建具体的 runtime 和它的containerd-shim。Container 和 Pod Sandbox组成了一个Pod。
CRI-containerd 的一个好处是,containerd 还额外实现了更丰富的容器接口,所以它可以用 containerd 提供的 ctr 工具来调用这些丰富的容器运行时接口,而不只是 CRI 接口
CRI实现了两个GRPC协议的API,提供两种服务ImageService和RuntimeService。
//grpcServicesareallthegrpcservicesprovidedbycricontainerd.
typegrpcServicesinterface{
runtime.RuntimeServiceServer
runtime.ImageServiceServer
}
//CRIServiceistheinterfaceimplementCRIremoteserviceserver.
typeCRIServiceinterface{
Run()error
//io.Closerisusedbycontainerdtogracefullystopcriservice.
io.Closer
plugin.Service
grpcServices
}
CRI的实现CRIService中包含了很多重要的组件:其中最重要的是cni.CNI,用于配置容器网络。还有containerd.Client,用于连接containerd来创建容器。
//criServiceimplementsCRIService.
typecriServicestruct{
//configcontainsallconfigurations.
configcriconfig.Config
//imageFSPathisthepathtoimagefilesystem.
imageFSPathstring
//osisaninterfaceforallrequiredosoperations.
ososinterface.OS
//sandboxStorestoresallresourcesassociatedwithsandboxes.
sandboxStore*sandboxstore.Store
//sandboxNameIndexstoresallsandboxnamesandmakesureeachname
//isunique.
sandboxNameIndex*registrar.Registrar
//containerStorestoresallresourcesassociatedwithcontainers.
containerStore*containerstore.Store
//containerNameIndexstoresallcontainernamesandmakesureeach
//nameisunique.
containerNameIndex*registrar.Registrar
//imageStorestoresallresourcesassociatedwithimages.
imageStore*imagestore.Store
//snapshotStorestoresinformationofallsnapshots.
snapshotStore*snapshotstore.Store
//netPluginisusedtosetupandteardownnetworkwhenrun/stoppodsandbox.
netPlugincni.CNI
//clientisaninstanceofthecontainerdclient
client*containerd.Client
//streamServeristhestreamingserverservescontainerstreamingrequest.
streamServerstreaming.Server
//eventMonitoristhemonitormonitorscontainerdevents.
eventMonitor*eventMonitor
//initializedindicateswhethertheserverisinitialized.AllGRPCservices
//shouldreturnerrorbeforetheserverisinitialized.
initializedatomic.Bool
//cniNetConfMonitorisusedtoreloadcninetworkconfifthereis
//anyvalidfschangeeventsfromcninetworkconfdir.
cniNetConfMonitor*cniNetConfSyncer
//baseOCISpecscontainscachedOCIspecsloadedvia`Runtime.BaseRuntimeSpec`
baseOCISpecsmap[string]*oci.Spec
}
我们知道 Kubernetes 的一个运作的机制是面向终态的,在每一次调协的循环中,Kubelet 会向 apiserver 获取调度到本 Node 的 Pod 的数据,再做一个面向终态的处理,以达到我们预期的状态。
循环的第一步,首先通过 List 接口拿到容器的状态。确保有镜像,如果没有镜像则 pull 镜像再通过 Sandbox 和 Container 接口来创建容器。需要注意的是,我们的 CNI(容器网络接口)也是在 CRI 进行操作的,因为我们在创建 Pod 的时候需要同时创建网络资源然后注入到 Pod 中(PS:CNI包含在创建Pod 这个动作里)。接下来就是我们的容器和镜像。我们通过具体的容器创建引擎来创建一个具体的容器。
执行流程为:
- Kubelet 通过 CRI runtime service API 调用 CRI plugin 创建 pod
- CRI 通过 CNI 创建 pod 的网络配置和 namespace
- CRI使用 containerd 创建并启动 pause container (sandbox container) 并且把这个 container 置于 pod 的 cgroups/namespace
- Kubelet 接着通过 CRI image service API 调用 CRI plugin, 获取容器镜像
- CRI 通过 containerd 获取容器镜像
- Kubelet 通过 CRI runtime service API 调用 CRI, 在 pod 的空间使用拉取的镜像启动容器
- CRI 通过 containerd 创建/启动 应用容器, 并且把 container 置于 pod 的 cgroups/namespace. Pod 完成启动。
总结
发现 CRI 只是服务于 Kubernetes 的,而且它呈现向上汇报的状态。它是帮助 Kubernetes 的,它不帮助OCI的。所以说当你去做这个集成时候,你会发现尤其对于 VM gVisor\KataContainer 来说,它与 CRI 的很多假设或者是 API 的写法上是不对应的。所以你的集成工作会比较费劲,这是一个不 match 的状态。

最后一个就是我们维护起来非常困难,因为由于有了 CRI 之后,比如 RedHat 拥有自己的 CRI 实现叫 cri-o,他们和 containerd 在本质上没有任何区别,跑到最后都是靠 runC 起容器,为什么还需要cri-o这种东西?
我们不知道,如果我想使用Kata container与containerd多运行时的话,我需要给他们两个分别写两部分的一体化把 Kata 集成进去。这就很麻烦,就意味着我有 100 种这样的 CRI ,我就要写 100 个shim去集成,而且他们的功能全部都是重复的。
所以这就产生了Containerd ShimV2的这样的shim来解决这个问题。我们下回分解。
reference
https://time.geekbang.org/column/article/71499?utm_campaign=guanwang&utm_source=baidu-ad&utm_medium=ppzq-pc&utm_content=title&utm_term=baidu-ad-ppzq-title
https://blog.frognew.com/2021/04/relearning-container-02.html
https://github.com/kubernetes-sigs/cri-tools/blob/master/docs/crictl.md
https://developer.aliyun.com/article/679993
转载请注明:IT运维空间 » 运维技术 » CRI shim:kubelet怎么与runtime交互(一)
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-
oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-
如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/2.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值












发表评论