


今天和同事聊起了一个问题,主要背景是有2个数据库需要数据流转至数仓系统,虽然数据库的存储容量很大,但是需要流转的数据量不大,举个例子,比如源数据库有100张表占用800G,但是数据流转只需要10张表,占用30G, 所以在构建数据源集市的时候,我们就选择了多源复制的模式,把两个数据库合在一起对外交付,本质上还是基于主从复制的模式,只是更加灵活而已。
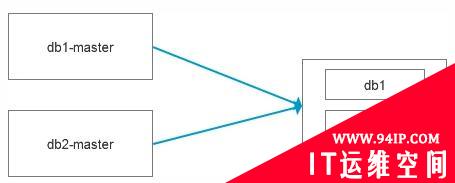
近期有个新需求,打破了这种平静,现在需要新增几张数据表流转至数仓系统,尴尬的是这几张表因为历史原因没有分表,单表的数据量在几亿,如果采用逻辑导出导入的方式,需要差不多5个小时左右,而且最关键的是,还带来了一系列问题:
1)这种数据导出导入的模式,数据导入完成后的数据补齐工作很难,因为数据是从主库复制,所以这个中间节点上面始终是一种动态的数据处理过程,从理论上来说,是没有办法追齐数据的
2)数据复制基于GTID,什么时候该做取舍也是个难题,比如其他的10张表在实时复制,而新增的表会产生新的GTID,在数据没有应用过来之前,会有一系列的GTID无法自动修复。
如果把这个图画的更全面一些,其实是这样的结构,默认是有数据的容灾节点的,中间节点是直接从主库进行数据复制的。
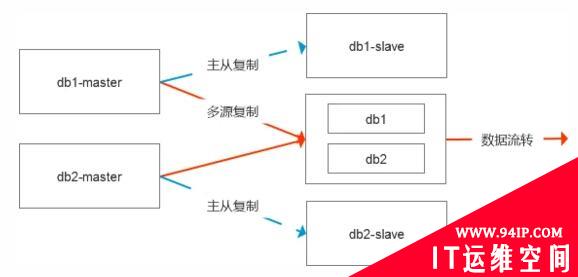
要解决现在的这个问题,导出导入5个小时显然是不合理的,而相对来说理想的方式便是基于物理数据的处理模式。
一种是传输表空间,直接把ibd文件拷贝到中间节点,然后修复数据的差异,这个时候有两种修复差值的模式,一种是基于表中的增量时间来处理,相对不够通用,第二种则是更严谨的模式,则是修改数据的复制链路,基于从库级联复制即可。
这里的关键便是在开启传输表空间前就停止slave复制,让整个系统处于静止状态,这样能够保证数据的完整性,这个过程如果是复制ibd文件,30G左右的文件大概30分钟就能搞定。
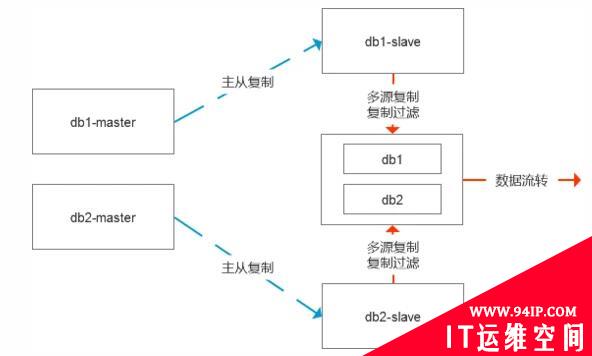
复制完成后,可以根据需求是继续保留基于从库复制还是重新调整GTID绑定到主库端去。
最终的变更状态和原来基本保持一致。
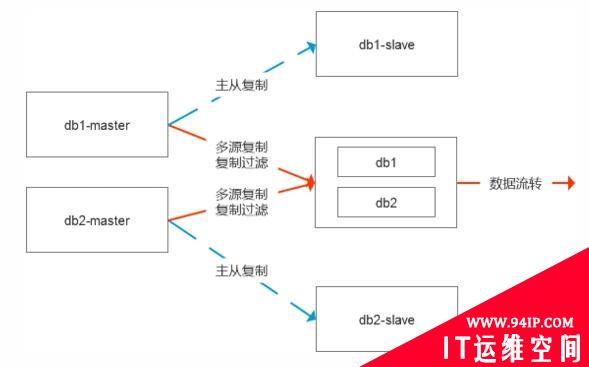
第二种处理模式简单直接,即需要寻找数据问题的根因,比如源库有100张表占用800G,但是需要流转10张表占用30G,那么我们是不是可以直接基于数据库级,实例级进行数据复制,等数据复制状态正常后我们把那90张表都清理掉,在处理过程中,对于一些可能出现的复制异常编码进行统一的过滤处理。这样我们的数据始终是实时更新的状态,无论是状态性数据实时更新还是日志型数据实时更新都可以灵活的适配。
同时在这个时候我们对于多源复制也可以做一些取舍,在这种场景下我觉得使用的意义就不是很大了。
综上,数据复制是一个很好的数据开关,能够灵活的适配和处理很多偏向于业务需求的数据逻辑,在这个过程中,基于系统层,物理的处理模式要远比逻辑处理要高效的多。
转载请注明:IT运维空间 » 运维技术 » 基于MySQL复制的业务需求分析和改进
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-
如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/1.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值










发表评论