


介绍
大家好,我是Leo,目前在常州从事Java后端工程师。上篇文章我们介绍了读写分离那些问题,主要从概念,目的,单到多的演变,安全性演变以及六个解决方案为叙述。今天我们聊聊一主多从,如果挂了你会如何快速定位。赠送算法,MySQL书籍,剑指offer
思路
根据读者和用户的反馈,画了一个写作思路图。通过此图可以更好的分析出当前文章的写作知识点。可以更快的帮助读者在最短时间内判断是否为有效文章!
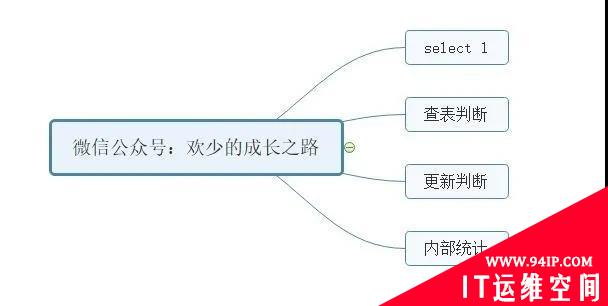
外部统计
select 1
正常情况
这里先来聊一下select 1的用法,这个用法我想大家应该都是知道的,因为判断一个库是否还活着,只需要执行一条SQL语句不就好了嘛
- 如果库正常没有问题,那么就会返回1,因为输出1肯定是要返回1的呀
- 如果库挂掉了,输出1肯定是没有反应的,因为MySQL已经无法提供服务了
mysql在执行select1的时候,往往是用于单机服务,我们举一个很简单的例子,在一个cmd控制台上进入mysql,并且执行SQL语句,只能得知当前库是否正常。无法得知整个数据库的集群是否都正常。所以在单机状态下这种方案是比较常用的,一旦上了一些集群规模一般不会采用这种方案!
意外情况
首先我们介绍一下配置并发线程上限的参数 innodb_thread_concurrency 。如果把他设置 3 一旦并发线程数达到这个值,InnoDB 在接收到新请求的时候,就会进入等待状态,直到有线程退出。
这里我们可以模拟一下最坏的情况,如果这时有三个线程正常访问数据库执行一个大数据量的查询操作。如果这时来一个select 1 是否能执行成功呢?
会执行成功的 ! 但是如果测验完之后这个用户再发送一条查询表请求,就会被堵住,因为另外三个线程的用户也在查询表操作,那么这几个线程就会处于等待情况。
问题来了 select 1执行成功了,真实的查询语句出问题了,那么这个方案可行吗,肯定是不行的。
innodb_thread_concurrency 这个参数默认是0。代表着不限制上限并发线程。这个肯定是不行,考虑到整体性能的考虑,如果并发线程过于会影响MySQL的整体性能。所以我们一般建议64~128。
扩展 这里的64~128是指并发查询的线程,可能有些人会和并发连接会弄混。
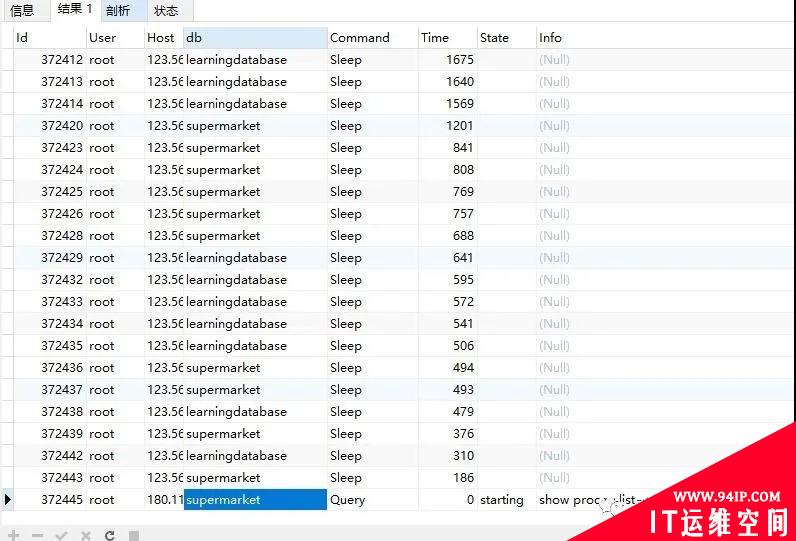
showprocesslist
执行上述SQL,以下是Command列中的Query是属于并发查询,并发连接是属于与数据库发起连接,但是挂在那个界面不做任何操作。并发连接只是浪费一些内存而已,而并发查询是浪费MySQL限制的并发线程数的。
我们介绍一下热点更新和死锁检测的时候吧。如果把 innodb_thread_concurrency设置为 128 的话,那么出现同一行热点更新的问题时,是不是很快就把 128 消耗完了,这样整个系统是不是就挂了呢?
不是的, MySQL肯定不会允许这样的事情发生的。所以当锁等待的时候,并发线程会进行减一。也就说锁等待不会算在线程128中。
特殊情况
一些锁等待肯定是不算在并发线程中的,那么如果像我们上述那种消耗时间比较大的查询,如何处置呢?
如果真的干到了128,再使用select 1 岂不是会出问题吗,所以下一个方案就诞生了
查表判断
select 1 的弊端出来了,逐渐演变成查表判断
- 那么表放在什么地方呢?
- 肯定不能随便放在一个数据库中吧!
表的位置是在如下图的那个数据库中建立的,我们可以建立一个health_check,里面只放一行数据,然后定期执行。
select*frommysql.health_check;
这样的确可以从innodb这边解决当前的数据库的状态,那么问题来了,innodb是要写日志的,也就是写binlog,所以当磁盘空间占用率达到100%。所有的更新语句和事务提交的 commit 语句就都会被堵住。但是,系统这时候还是可以正常读数据的。
上面的查询判断,显然是不行的。
更新数据也就是记入一个事务。记入事务是要写binlog日志的,磁盘满了咋写?
所以执行不成功,但是还能提供读取的数据。显然两头不对应肯定不可以的。
更新判断
又pass了一个
既然要更新,就要放个有意义的字段,常见做法是放一个 timestamp 字段,用来表示最后一次执行检测的时间。这条更新语句类似于:
updatemysql.health_checksett_modified=now();
所有主从库涉及到更新操作的话,肯定是要处理同步问题的
节点可用性的检测都应该包含主库和备库。如果用更新来检测主库的话,那么备库也要进行更新检测。备库的检测也是要写 binlog 的。由于我们一般会把数据库 A 和 B 的主备关系设计为双 M 结构,所以在备库 B 上执行的检测命令,也要发回给主库 A。
主库 A 和备库 B 都用相同的更新命令,就可能出现行冲突,也就是可能会导致主备同步停止。所以,现在看来 mysql.health_check 这个表就不能只有一行数据了。
如果存放多行的话,在一主多从中就要考虑server_id的问题啦
MySQL 规定了主库和备库的 server_id 必须不同(否则创建主备关系的时候就会报错),这样就可以保证主、备库各自的检测命令不会发生冲突。
更新判断是一个相对比较常用的方案了,不过依然存在一些问题。比如 “判定慢”
根据我们前几篇文章的介绍,当更新操作出现慢操作或者失败。就可以主从切换了,为什么还会有判定慢的问题呢?
IO资源分配
首先,所有的检测逻辑都需要一个超时时间 N。执行一条 update 语句,超过 N 秒后还不返回,就认为系统不可用。
判定慢是因为IO资源分配的问题,日志盘的 IO 利用率已经是 100% 的场景。这时候,整个系统响应非常慢,已经需要做主备切换了。
IO 利用率 100% 表示系统的 IO 是在工作的,每个请求都有机会获得 IO 资源,执行自己的任务。而我们的检测使用的 update 命令,需要的资源很少,所以可能在拿到 IO 资源的时候就可以提交成功,并且在超时时间 N 秒未到达之前就返回给了检测系统。
检测系统一看,update 命令没有超时,于是就得到了 系统正常 的结论。
IO问题,SQL执行很慢,但是这个时候系统是正常的肯定是不行的
内部统计
外部统计无法判断满足真实需求。我们转战内部统计方案。
上一种方案的更细判断,会有写入binlog IO磁盘的问题,那么方案优化,如果MySQL可以提供这类数据岂不是可靠多了嘛!
从performance_schema 库,就在 file_summary_by_event_name 表里统计了每次 IO 请求的时间。
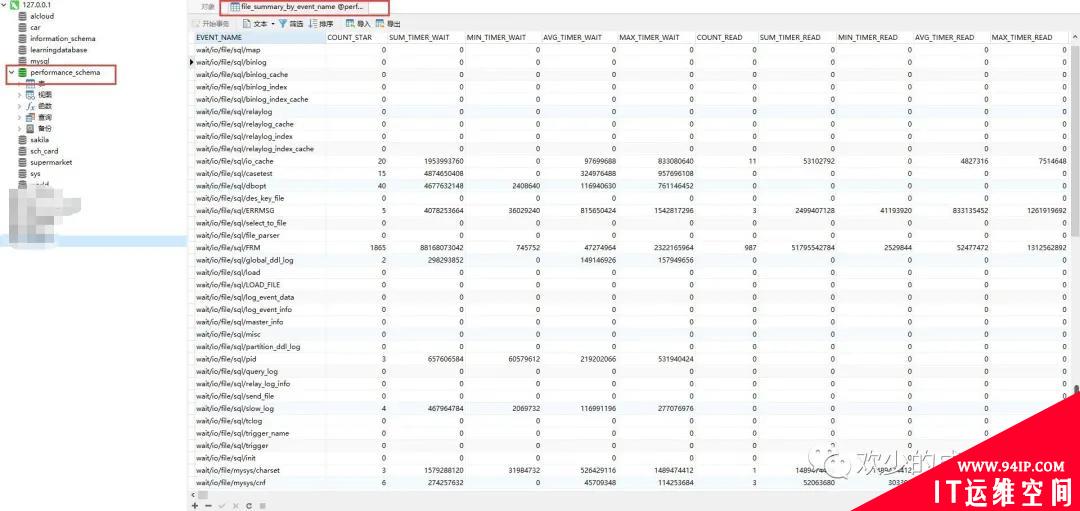
COUNT_STAR:所有 IO 的总次数
SUM_NUMBER_OF_BYTES_READ :总共从 redo log 里读了多少个字节。
对上述表中的字段介绍简单普及一下最常用的。剩下的用的时候自行搜索。
排查思路
找到这个表之后,我们只需要event_name = "wait/io/file/sql/binlog"这一行就OK了。
我们每一次操作数据库,performance_schema 都需要额外地统计这些信息,所以我们打开这个统计功能是有性能损耗的。
如果要打开 redo log 的时间监控,你可以执行这个语句:
updatesetup_instrumentssetENABLED='YES',Timed='YES'wherenamelike'%wait/io/file/innodb/innodb_log_file%';
开启之后,用于实战呢
可以通过 MAX_TIMER 的值来判断数据库是否出问题了。比如,你可以设定阈值,单次 IO 请求时间超过 200 毫秒属于异常,然后使用类似下面这条语句作为检测逻辑。
selectevent_name,MAX_TIMER_WAITFROMperformance_schema.file_summary_by_event_namewhereevent_namein('wait/io/file/innodb/innodb_log_file','wait/io/file/sql/binlog')andMAX_TIMER_WAIT>200*1000000000;
发现异常后,取到你需要的信息,再通过下面这条语句:
truncatetableperformance_schema.file_summary_by_event_name;
把之前的统计信息清空。这样如果后面的监控中,再次出现这个异常,就可以加入监控累积值了。
总结
大概介绍了从最基础的 select 1 方法开始,这种方法应用与单机MySQL是再好不过了,但是一主多从集群之后就不行了。
于是到了查表判断,查表判断涉及到 innodb写事务日志的时候,如果磁盘满了的话,写事务写不了但是可以读,导致不一致。
再到更新判断。IO 利用率 100% 表示系统的 IO 是在工作的,每个请求都有机会获得 IO 资源。所以update不会超时,系统认为是正常情况。所以一边响应不了服务,一边又判断正常,导致不一致。
最后到了内部统计。采用系统库的方案。通过 event_name 和 MAX_TIMER 字段进行判断是否出问题
转载请注明:IT运维空间 » 运维技术 » 线上数据库挂了,你该如何排查?
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值












发表评论