

1.为什么需要磁盘阵列
如何增加磁盘的存取(access)速度,如何防止数据因磁盘的故障而失落及如何有效的利用磁盘空间,一直是电脑专业人员和用户的困扰;而大容量磁盘的价格非常昂贵,对用户形成很大的负担。磁盘阵列技术的产生一举解决了这些问题。
过去十年来,CPU的处理速度增加了五十倍有多,内存(memory)的存取速度亦大幅增,而数据储存装置–主要是磁盘(hard disk)–的存取速度只增加了三、四倍,形成电脑系统的瓶颈,拉低了电脑系统的整体性能(throughput),若不能有效的提升磁盘的存取速度,CPU、内存及磁盘间的不平衡将使CPU及内存的改进形成浪费。
目前改进磁盘存取速度的的方式主要有两种。一是磁盘快取控制(disk cache controller),它将从磁盘读取的数据存在快取内存(cache memory)中以减少磁盘存取的次数,数据的读写都在快取内存中进行,大幅增加存取的速度,如要读取的数据不在快取内存中,或要写数据到磁盘时,才做磁盘的存取动作。这种方式在单工环境(single-tasking environment)如DOS之下,对大量数据的存取有很好的性能(量小且频繁的存取则不然),但在多工(multi-tasking)环境之下(因为要不停地作数据交换(swapping)的动作)或数据库(database)的存取(因为每一记录都很小)就不能显示其性能。这种方式没有任何安全保障。其二是使用磁盘阵列的技术。磁盘阵列是把多个磁盘组成一个阵列,当作单一磁盘使用,它将数据以分段(striping)的方式储存在不同的磁盘中,存取数据时,阵列中的相关磁盘一起动作,大幅减低数据的存取时间,同时有更佳的空间利用率。磁盘阵列所利用的不同的技术,称为RAID level,不同的level针对不同的系统及应用,以解决数据安全的问题。
一般高性能的磁盘阵列都是以硬件的形式来达成,进一步的把磁盘快取控制及磁盘阵列结合在一个控制器(RAID controller)或控制卡上,针对不同的用户解决人们对磁盘输出入系统的四大要求: (1)增加存取速度, (2)容错(fault tolerance),即安全性 (3)有效的利用磁盘空间; (4)尽量的平衡CPU,内存及磁盘的性能差异,提高电脑的整体工作性能。
2.磁盘阵列原理
磁盘阵列中针对不同的应用使用的不同技术,称为RAID level, RAID是Redundant Array of Inexpensive Disks的缩写,而每一level代表一种技术,目前业界公认的标准是RAID 0~RAID 5。这个level并不代表技术的高低,level 5并不高于level 3,level 1也不低过level 4,至于要选择那一种RAID level的产品,纯视用户的操作环境(operating environment)及应用(application)而定,与level的高低没有必然的关系。RAID 0及RAID 1适用于PC及PC相关的系统如小型的网络服务器(network server)及需要高磁盘容量与快速磁盘存取的工作站等,因为比较便宜,但因一般人对磁盘阵列不了解,没有看到磁盘阵列对他们价值,市场尚未打开;RAID 2及RAID 3适用于大型电脑及影像、CAD/CAM等处理;RAID 5多用于OLTP,因有金融机构及大型数据处理中心的迫切需要,故使用较多而较有名气,但也因此形成很多人对磁盘阵列的误解,以为磁盘阵列非要RAID 5不可;RAID 4较少使用,因为两者有其共同之处,而RAID 4有其先天的限制。其他如RAID 6,RAID 7,乃至RAID 10等,都是厂商各做各的,并无一致的标准,在此不作说明。介绍各个RAID level之前,先看看形成磁盘阵列的两个基本技术:磁盘延伸(Disk Spanning):译为磁盘延伸,能确切的表示disk spanning这种技术的含义。如下图所示,DFTraid 磁盘阵列控制器,联接了四个磁盘:
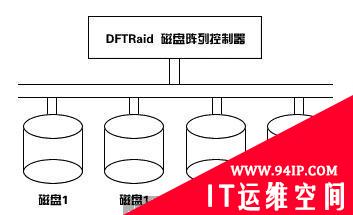
这四个磁盘形成一个阵列(array),而磁盘阵列的控制器(RAID controller)是将此四个磁盘视为单一的磁盘,如DOS环境下的C:盘。这是disk spanning的意义,因为把小容量的磁盘延伸为大容量的单一磁盘,用户不必规划数据在各磁盘的分布,而且提高了磁盘空间的使用率。DFTraid的SCSI磁盘阵列更可连接几十个磁盘,形成数十GB到数百GB的阵列,使磁盘容量几乎可作无限的延伸;而各个磁盘一起作取存的动作,比单一磁盘更为快捷。很明显的,有此阵列的形成而产生RAID的各种技术。我们也可从上图看出inexpensive(便宜)的意义,因为四个250MBbytes的磁盘比一个1GBytes的磁盘要便宜,尤其以前大磁盘的价格非常昴贵,但在磁盘越来越便宜的今天,inexpensive已非磁盘阵列的重点,虽然对于需要大磁盘容量的系统,仍是考虑的要点。磁盘或数据分段(Disk Striping or Data Striping):
因为磁盘阵列是将同一阵列的多个磁盘视为单一的虚拟磁盘(virtual disk),所以其数据是以分段(block or segment)的方式顺序存放在磁盘阵列中,如下图:
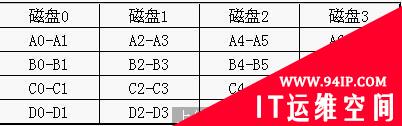
数据按需要分段,从第一个磁盘开始放,放到最後一个磁盘再回到第一个磁盘放起,直到数据分布完毕。至于分段的大小视系统而定,有的系统或以1KB最有效率,或以4KB,或以6KB,甚至是4MB或8MB的,但除非数据小于一个扇区(sector,即521bytes),否则其分段应是512byte的倍数。因为磁盘的读写是以一个扇区为单位,若数据小于512bytes,系统读取该扇区后,还要做组合或分组(视读或写而定)的动作,浪费时间。从上图我们可以看出,数据以分段于在不同的磁盘,整个阵列的各个磁盘可同时作读写,故数据分段使数据的存取有最好的效率,理论上本来读一个包含四个分段的数据所需要的时间约=(磁盘的access time +数据的transfer time)X4次,现在只要一次就可以完成。
若以N表示磁盘的数目,R表示读取,W表示写入,S表示可使用空间,则数据分段的性能为: R:N(可同时读取所有磁盘) W:N(可同时写入所有磁盘) S:N(可利用所有的磁盘,并有最佳的使用率)
Disk striping也称为RAID 0,很多人以为RAID 0没有甚么,其实这是非常错误的观念,因为RAID 0使磁盘的输出入有最高的效率。而磁盘阵列有更好效率的原因除数据分段外,它可以同时执行多个输出入的要求,因为阵列中的每一个磁盘都能独立动作,分段放在不同的磁盘,不同的磁盘可同时作读写,而且能在快取内存及磁盘作并行存取(parallel access)的动作,但只有硬件的磁盘阵列才有此性能表现。
从上面两点我们可以看出,disk spanning定义了RAID的基本形式,提供了一个便宜、灵活、高性能的系统结构,而disk striping解决了数据的存取效率和磁盘的利用率问题,RAID 1至RAID 5是在此基础上提供磁盘安全的方案。
RAID 1
RAID 1是使用磁盘镜像(disk mirroring)的技术。磁盘镜像应用在RAID 1之前就在很多系统中使用,它的方式是在工作磁盘(working disk)之外再加一额外的备份磁盘(backup disk),两个磁盘所储存的数据完全一样,数据写入工作磁盘的同时亦写入备份磁盘。磁盘镜像不见得就是RAID 1,如Novell NetWare亦有提供磁盘镜像的功能,但并不表示NetWare有了RAID 1的功能。一般磁盘镜像和RAID 1有二点最大的不同:
RAID 1无工作磁盘和备份磁盘之分,多个磁盘可同时动作而有重叠(overlapping)读取的功能,甚至不同的镜像磁盘可同时作写入的动作,这是一种最佳化的方式,称为负载平衡(load-balance)。例如有多个用户在同一时间要读取数据,系统能同时驱动互相镜像的磁盘,同时读取数据,以减轻系统的负载,增加I/O的性能。
RAID 1的磁盘是以磁盘延伸的方式形成阵列,而数据是以数据分段的方式作储存,因而在读取时,它几乎和RAID 0有同样的性能。从RAID的结构就可以很清楚的看出RAID 1和一般磁盘镜像的不同。
下图为RAID 1,每一笔数据都储存两份
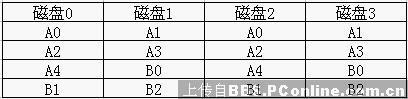
从上图可以看出: R:N(可同时读取所有磁盘) W:N/2(同时写入磁盘数) S:N/2(利用率)
读取数据时可用到所有的磁盘,充分发挥数据分段的优点;写入数据时,因为有备份,所以要写入两个磁盘,其效率是N/2,磁盘空间的使用率也只有全部磁盘的一半。
很多人以为RAID 1要加一个额外的磁盘,形成浪费而不看好RAID 1,事实上磁盘越来越便宜,并不见得造成负担,况且RAID 1有最好的容错(fault tolerance)能力,其效率也是除RAID 0之外最好的。我们可视应用的不同,在同一磁盘阵列中使用不同的RAID level,如华艺科技公司的DFTraid系列都可同一磁盘阵列中定义八个逻辑磁盘(logic disk),分别使用不同的RAID level,分为C:,D:及E:三个逻辑磁盘(或LUN0,LUN1,LUN2).
RAID 1完全做到了容错包括不停机(non-stop),当某一磁盘发生故障,可将此磁盘拆下来而不影向其他磁盘的操作;待新的磁盘换上去之后,系统即时做镜像,将数据重新复上去,RAID 1在容错及存取的性能上是所有RAID level之冠。
在磁盘阵列的技术上,从RAID 1到RAID 5,不停机的意思表示在工作时如发生磁盘故障,系统能持续工作而不停顿,仍然可作磁盘的存取,正常的读写数据;而容错则表示即使磁盘故障,数据仍能保持完整,可让系统存取到正确的数据,而SCSI的磁盘阵列更可在工作中抽换磁盘,并可自动重建故障磁盘的数据。磁盘阵列之所以能做到容错及不停机,是因为它有冗余的磁盘空间可资利用,这也就是Redundant的意义。
#p#
RAID 2
RAID 2是把数据分散为位元(bit)或块(block),加入海明码Hamming Code,在磁盘阵列中作间隔写入(interleaving)到每个磁盘中,而且地址(address)都一样,也就是在各个磁盘中,其数据都在相同的磁道(cylinder or track)及扇区中。RAID 2的设计是使用共轴同步(spindle synchronize)的技术,存取数据时,整个磁盘阵列一起动作,在各作磁盘的相同位置作平行存取,所以有最好的存取时间(access time),其总线(bus)是特别的设计,以大带宽(band wide)并行传输所存取的数据,所以有最好的传输时间(transfer time)。在大型档案的存取应用,RAID 2有最好的性能,但如果档案太小,会将其性能拉下来,因为磁盘的存取是以扇区为单位,而RAID 2的存取是所有磁盘平行动作,而且是作单位元的存取,故小于一个扇区的数据量会使其性能大打折扣。RAID 2是设计给需要连续且大量数据的电脑使用的,如大型电脑(mainframe to supercomputer)、作影像处理或CAD/CAM的工作站(workstation)等,并不适用于一般的多用户环境、网络服务器(network server),小型机或PC。
RAID 2的安全采用内存阵列(memory array)的技术,使用多个额外的磁盘作单位错误校正(single-bit correction)及双位错误检测(double-bit detection);至于需要多少个额外的磁盘,则视其所采用的方法及结构而定,例如八个数据磁盘的阵列可能需要三个额外的磁盘,有三十二个数据磁盘的高档阵列可能需要七个额外的磁盘。
RAID 3
RAID 3的数据储存及存取方式都和RAID 2一样,但在安全方面以奇偶校验(parity check)取代海明码做错误校正及检测,所以只需要一个额外的校检磁盘(parity disk)。奇偶校验值的计算是以各个磁盘的相对应位作XOR的逻辑运算,然后将结果写入奇偶校验磁盘,任何数据的修改都要做奇偶校验计算,如下图:

如某一磁盘故障,换上新的磁盘后,整个磁盘阵列(包括奇偶校验磁盘)需重新计算一次,将故障磁盘的数据恢复并写入新磁盘中;如奇偶校验磁盘故障,则重新计算奇偶校验值,以达容错的要求.
较之RAID 1及RAID 2,RAID 3有85%的磁盘空间利用率,其性能比RAID 2稍差,因为要做奇偶校验计算;共轴同步的平行存取在读档案时有很好的性能,但在写入时较慢,需要重新计算及修改奇偶校验磁盘的内容。RAID 3和RAID 2有同样的应用方式,适用大档案及大量数据输出入的应用,并不适用于PC及网络服务器。
RAID 4
RAID 4也使用一个校验磁盘,但和RAID 3不一样,如下图:

RAID 4是以扇区作数据分段,各磁盘相同位置的分段形成一个校验磁盘分段(parity block),放在校验磁盘。这种方式可在不同的磁盘平行执行不同的读取命今,大幅提高磁盘阵列的读取性能;但写入数据时,因受限于校验磁盘,同一时间只能作一次,启动所有磁盘读取数据形成同一校验分段的所有数据分段,与要写入的数据做好校验计算再写入。即使如此,小型档案的写入仍然比RAID 3要快,因其校验计算较简单而非作位(bit level)的计算;但校验磁盘形成RAID 4的瓶颈,降低了性能,因有RAID 5而使得RAID 4较少使用。
RAID 5
RAID5避免了RAID 4的瓶颈,方法是不用校验磁盘而将校验数据以循环的方式放在每一个磁盘中,如下图

磁盘阵列的第一个磁盘分段是校验值,第二个磁盘至后一个磁盘再折回第一个磁盘的分段是数据,然后第二个磁盘的分段是校验值,从第三个磁盘再折回第二个磁盘的分段是数据,以此类推,直到放完为止。图中的第一个parity block是由A0,A1…,B1,B2计算出来,第二个parity block是由B3,B4,…,C4,D0计算出来,也就是校验值是由各磁盘同一位置的分段的数据所计算出来。这种方式能大幅增加小档案的存取性能,不但可同时读取,甚至有可能同时执行多个写入的动作,如可写入数据到磁盘1而其parity block在磁盘2,同时写入数据到磁盘4而其parity block在磁盘1,这对联机交易处理(OLTP, on-line Transaction Processing)如银行系统、金融、股市等或大型数据库的处理提供了最佳的解决方案(solution),因为这些应用的每一笔数据量小,磁盘输出入频繁而且必须容错。
事实上RAID 5的性能并无如此理想,因为任何数据的修改,都要把同一parity block的所有数据读出来修改后,做完校验计算再写回去,也就是RMW cycle(Read-Modify-Write cycle,这个cycle没有包括校验计算);正因为牵一而动全身,所以: R:N(可同时读取所有磁盘) W:1(可同时写入磁盘数) S:N-1(利用率)
RAID 5的控制比较复杂,尤其是利用硬件对磁盘阵列的控制,因为这种方式的应用比其他的RAID level要掌握更多的事情,有更多的输出入需求,既要速度快,又要处理数据,计算校验值,做错误校正等,所以价格较高;其应用最好是OLTP,至于用于PC等,不见得有最佳的性能。
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-
JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-
如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/9.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值














发表评论