


图片来自 Pexels
通过日志发现,从凌晨 5:26 分开始到 5:56 任务执行了三次,三次都因为 SQL 查询超时而执行失败,而诡异的是,任务到凌晨 6:00 多就执行成功了。
每天都是凌晨五点多失败,凌晨六点执行成功。
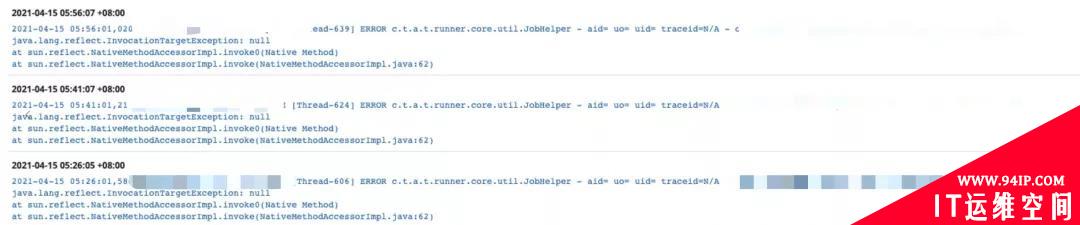
点开异常日志一看是这样的:
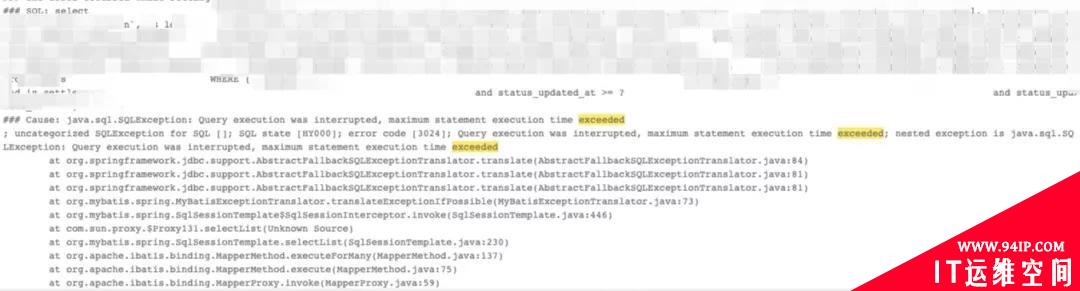
总结来说就是 MySQL 查询超时。像这种稳定复现的 Bug,我原以为只需三分钟能定位,没有想到却耗费了我半天的时间。
01排查之路
①Explain
看到超时 SQL,大多数人第一反应就是这个 SQL 没有走索引,我也不例外,我当时的第一反应就是这条 SQL 没有走索引。
于是,我将日志里面的 SQL 复制了出来,脱敏处理一下大概是这样的一条 SQL:
select * from table_a where status_updated_at >= ? and status_updated_at < ?
SQL 里面有两个日期参数,这两个起始日期是某种商品的可交易时间区间,相隔三到五天,我取了 17 天的时间间隔的保守值,Explain 了一下这条 SQL。
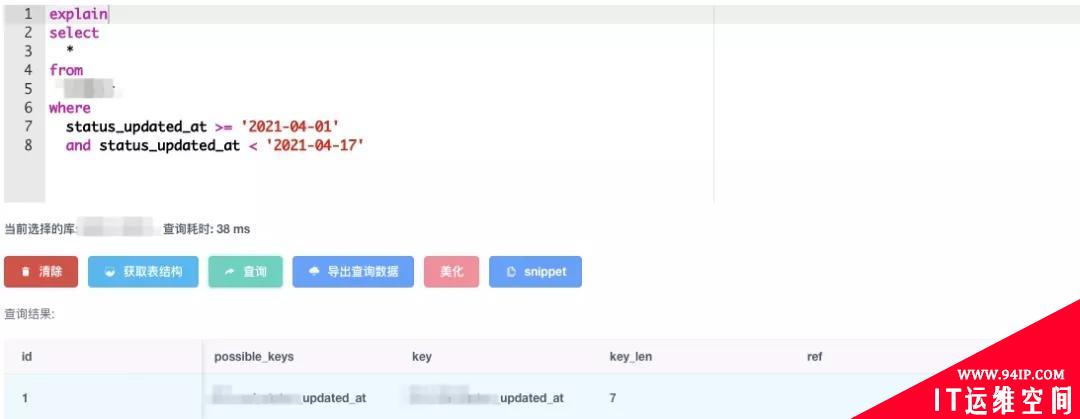
从图上可以看到这条 SQL 的执行还是走了索引的。走的是根据 status_updated_at 字段建立的索引。执行了一下也只耗时了 135 毫秒。

根据 Explain 结果,我当时的推断是:这条 SQL 肯定走了索引,如果没有走索引,那六点多钟的查询肯定也会超时,因为这个表的数据是千万级别的。
为了验证这一推断,我找 DBA 帮我导出了一下凌晨 5 点到早上 7 点关于这个表的慢 SQL,DBA 告诉我那个时间段没有关于这个表的慢 SQL。
这也进一步验证了我说推断:这条 SQL 走了索引,只是在五点多的时候因为一些神秘原因导致了超时。
接下来,需要做的就是找出这个神秘的原因。按照以往的经验,我认为有这几点因素会导致查询超时:
- MySQL 资源竞争
- 数据库备份
- 网络
②MySQL 资源竞争
首先,我通过监控系统查看了那段时间 MySQL 的运行情况,连接数和 CPU 负载等指标都非常正常。所以,因为 MySQL 负载导致超时首先就可以被排除。
那会不会是其他业务操作这个表影响的呢?首先,我们线上数据库事务隔离级别设置的是 RR(可重复读),因为 MVCC 的存在,简单的修改肯定是不会影响查询至超时的。
要想影响唯一的可能性就是别的业务在 update 这个表数据的时候,更新条件没有走索引,导致行锁升级成表锁,并且,这个操作要刚好在凌晨 5 点多执行,且持续了半个小时。
这个条件非常苛刻,我检查了相关的代码,问了相关负责人,并没有这种情况,所有的更新都是根据 Id 主键更新的。
关键是,如果更新 SQL 的更新条件没有走索引,肯定会是一个慢 SQL 的,那么,我们在慢 SQL 日志文件里面就能找到它,实际上并没有。
③备份
是不是因为凌晨 5 点多,数据库在备份的原因呢?
- 首先备份锁表不会锁这么久,这个任务是前前后后半个小时都执行失败了。
- 其次我们是备份的从库,并不是备份的主库。
- 最后,我们的备份任务都不是凌晨五点执行的。
所以,因为备份导致超时可以排除了。
④网络
是不是网络波动的原因呢?我找运维同学帮忙看了一下执行任务的那台机器那段时间的网络情况,非常平缓没有丝毫问题,机房也没有出现什么网络抖动的情况。
再者,如果是网络问题,肯定会影响其他任务和业务的,事实上,从监控系统中查看其他业务并没有什么异常。
所以,因为网络波动导致超时也可以排除了。
02转机
我先后排除了索引、网络、备份、业务竞争 MySQL 资源等因素,在脑海里模拟了 N 种情况,脑补了一条 SQL 整个执行过程,想不到会有什么其他原因了。
这个事情变得诡异了起来,DBA 劝我暂时放弃,建议我把任务执行时间延后,加一些监控日志再观察观察。毕竟,又不是不能用。
放弃是不可能放弃的,我是一个铁头娃,遇到 Bug 不解决睡不着觉。
理清思路,从头来过,我向 DBA 要了一份线上五点到六点的慢 SQL 的文件,自己重新找了一遍,还是没有找到这个表相关的慢 SQL。
在我突然要放弃的时候,我突然发现 SQL 日志记录里面的时区都是标准时区的,而我那个任务执行的时候是北京时间,要知道标准时区和北京时区是差了 8 个小时的!

好家伙!我都要想到量子力学了,结果发现时区没对上?会不会是 DBA 找慢 SQL 的时候时间找错了啊?
我将这个“重大发现”告诉了 DBA,DBA 帮我重新跑一份慢 SQL,好家伙,出现了我想要那个表的慢 SQL。
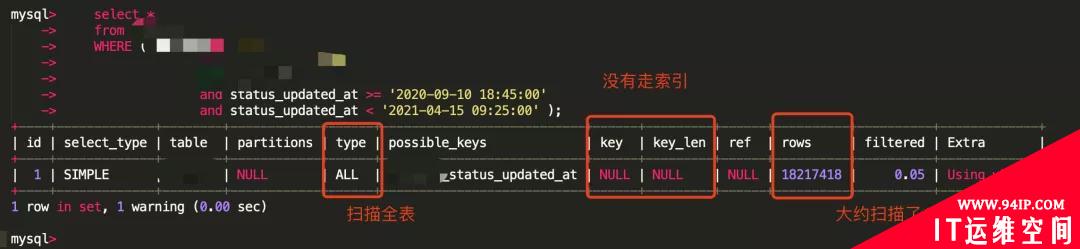
从日志上面可以看到,查询的日期区间从 2020 年 9 月到 2021 年 4 月,时间跨度 7 个月。
MySQL 成本计算的时候认为区间太大,走索引还不如直接扫描全表,最终没有走索引扫描了 1800W 条数据。
说好的时间区间最多七天呢?怎么变成了七个月?
赶紧定位代码,定位发现底层在取时间区间时,调了一个 RPC 接口,这个接口预期返回的时间区间只有几天,结果返回了七个月的时间区间。这段逻辑是 18 年上线的。
于是联系提供这个 RPC 接口的相关人员,通过查找验证确定这是底层数据的问题,应该返回几天结果返回了几个月。
最后修复了相关数据,增加了相应的校验和监控,重新发布系统,这个存在了两年的 Bug 也就得以解决了。
这个故事到这里也就结束了。再回顾一下,还有几个问题需要回答一下:
①不走索引,那为什么六点多执行就没有超时呢?
原因就是六点基本上没有业务在调用 MySQL,那个时候的 MySQL 的资源是非常充足的,加上 MySQL 的机器也配置非常的高,所以这条 SQL 硬生生跑成功了。听起来有点离谱,但确实是这样的。
②为什么这个 Bug 在线上这么久了,现在才发现?
这个时间区间底层数据用的不多,目前只发现只有这个超时 SQL 任务在调用。
原来业务量没有这么大,加上机器配置高,扫描整个表也花不了多久时间。凌晨五六点执行,没有对线上的服务造成影响。
任务失败是很正常的,因为还依赖一些其他数据,其他数据提供的时间不确定,所以任务会一直跑直到成功。
03总结
复盘一下整个过程,对于这个查询超时 SQL 问题的排查,我从索引、网络、备份、业务竞争 MySQL 资源等方面一一分析,却忽略了最重要的因素——执行的到底是哪一条 SQL。
我想当然的认为执行的 SQL 就是我想象中的那样并对此深信不疑,后面的努力也就成了徒劳。
这本是一个简单的问题,我却把他复杂化了,这是不应该的。
这是一个典型的例子,业务量不大的时候埋下的坑,业务发展迅速的时候就暴露了,万幸的是,没有影响到核心交易系统,如果是核心交易系统的话,可能就会导致一次 P0 的事故。
虽然这个代码不是我写的,但我从中得到的教训就是「对线上环境要有敬畏之心,对依赖数据要有怀疑之心,对问题排查要有客观之心」。
线上的环境极其复杂,有着各自版本迁移和业务变更遗留下来的数据,这些情况开发人员是无法全部考虑到的。
测试也很难覆盖测试,带着主观的想法去写代码很容易导致 Bug,有些 Bug 在业务量还不大的时候不容易引起重视,但随着业务的发展,这些欠下的债终究要还。
你可以保证你写的逻辑没有问题,但是你不能保证服务上游提供的数据都符合预期。
多想一下如果上游数据异常,自己写的服务会不会出问题,多加一些数据校验和报警会省去很多不必要的麻烦。
排查问题的时候,一定要客观,不要带着主观感受相当然的认为是这样。本来就是因为主观操作而导致的 Bug,你还想当然的代入去查找问题,这当然会加大排查问题的难度。
作者:CoderW
编辑:陶家龙
出处:转载自公众号CoderW(ID:MHXJ_0810)

转载请注明:IT运维空间 » 运维技术 » 一个诡异Bug,我差点背上P0事故!
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-
JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/7.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值









发表评论