


ClickHouse是一个列导向数据库,是原生的向量化执行引擎。它在大数据领域没有走Hadoop生态,而是采用Local attached storage作为存储,这样整个IO可能就没有Hadoop那一套的局限。它的系统在生产环境中可以应用到比较大的规模,因为它的线性扩展能力和可靠性保障能够原生支持shard+replication这种解决方案。它还提供了一些SQL直接接口,有比较丰富的原生client。
ClickHouse数据库的特点:
- 速度快ClickHouse性能超过了市面上大部分的列式存储数据库,相比传统的数据ClickHouse要快100-1000倍,ClickHouse还是有非常大的优势。1亿数据集:ClickHouse比Vertica约快5倍,比Hive快279倍,比MySQL快801倍。10亿数据集:ClickHouse比Vertica约快5倍,MySQL和Hive已经无法完成任务了。
- 功能多1.支持类SQL查询;2.支持繁多库函数(例如IP转化,URL分析等,预估计算/HyperLoglog等);3.支持数组(Array)和嵌套数据结构(Nested Data Structure);4.支持数据库异地复制部署。
要注意,由于ClickHouse的快速查询还是基于系统资源的,因此在使用的时候要注意每个节点上的存储量,以及节点机器的系统资源要充足。因为查询时是使用内存进行聚合,所以同时并发查询的数量不能太多,否则就会造成资源崩溃。
环境配置
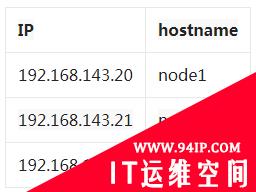
初始化环境(所有节点)
#修改机器的hostname vi/etc/hostname #配置hosts vi/etc/hosts 192.168.143.20node1 192.168.143.21node2 192.168.143.22node3
修改完后,执行hostname node1…3,不用重启机器使其生效
下载并安装ClickHouse(所有节点)
主要下载四个文件:
- Clickhouse-client
- Clickhouse-common-static
- Clickhouse-server
- clickhouse-server-common
rpm-ivh*.rpm
安装 zookeeper(任意一个节点)
#我这里选择node1 dockerrun-d--nethost--namezookeeperzookeeper
配置集群(所有节点)
修改/etc/clickhouse-server/config.xml
<!--将下面行注释去掉--> <listen_host>::</listen_host> <!--修改默认数据存储目录,比如在/home下创建目录clickhouse--> <path>/var/lib/clickhouse/</path> <!--修改为如下--> <path>/home/clickhouse/</path>
修改/etc/clickhouse-server/users.xml
<!--配置查询使用的内存,根据机器资源进行配置--> <max_memory_usage>5000000000000</max_memory_usage> <!--在</users>前面增加用户配置--> <root> <!--通过Linux命令计算出密码的sha256加密值--> <password_sha256_hex>xxxx...xxxx</password_sha256_hex> <networks> <ip>::/0</ip> </networks> <profile>default</profile> <quota>default</quota> </root>
增加配置文件/etc/metrika.xml
<yandex> <!--ck集群节点--> <clickhouse_remote_servers> <test_cluster> <shard> <internal_replication>true</internal_replication> <replica> <host>node1</host> <port>9000</port> <user>root</user> <password>123456</password> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>node2</host> <port>9000</port> <user>root</user> <password>123456</password> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>node3</host> <port>9000</port> <user>root</user> <password>123456</password> </replica> </shard> </test_cluster> <!--zookeeper相关配置--> <zookeeper-servers> <nodeindex="1"> <host>node1</host> <port>2181</port> </node> </zookeeper-servers> <networks> <ip>::/0</ip> </networks> <macros> <replica>node1</replica> </macros> <!--压缩相关配置--> <clickhouse_compression> <case> <min_part_size>10000000000</min_part_size> <min_part_size_ratio>0.01</min_part_size_ratio> <method>lz4</method> </case> </clickhouse_compression> </clickhouse_remote_servers> </yandex>
重启clickhouse服务
serviceclickhouse-serverrestart #如果不成功,则使用以下命令 nohup/usr/bin/clickhouse-server--config=/etc/clickhouse-server/config.xml$
创建数据表(所有节点)
使用可视化工具连接每个节点,在上面创建MergeTree
createdatabasetest; createtabletest.data ( countryString, provinceString, valueString ) engine=MergeTree() partitionby(country,province) orderbyvalue;
创建分布式表(node1节点)
createtabletest.moastest.dataENGINE=Distributed(test_cluster,test,data,rand());
使用Python连接clickhouse
安装clickhouse-driver
pipinstallclickhouse-driver
执行命令
fromclickhouse_driverimportClient
#在哪个节点创建了分布式表,就连接哪个节点
client=Client('192.168.143.20',user='root',password='123456',database='test')
print(client.execute('selectcount(*)frommo'))
转载请注明:IT运维空间 » 运维技术 » 一篇带给你ClickHouse集群搭建
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-
如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/6.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值











发表评论