

了解 Kubernetes 调度器是如何发现新的吊舱并将其分配到节点。

Kubernetes已经成为容器和容器化工作负载的标准编排引擎。它提供一个跨公有云和私有云环境的通用和开源的抽象层。
对于那些已经熟悉 Kuberbetes 及其组件的人,他们的讨论通常围绕着如何尽量发挥 Kuberbetes 的功能。但当你刚刚开始学习 Kubernetes 时,尝试在生产环境中使用前,明智的做法是从一些关于 Kubernetes 相关组件(包括Kubernetes 调度器) 开始学习,如下抽象视图中所示:
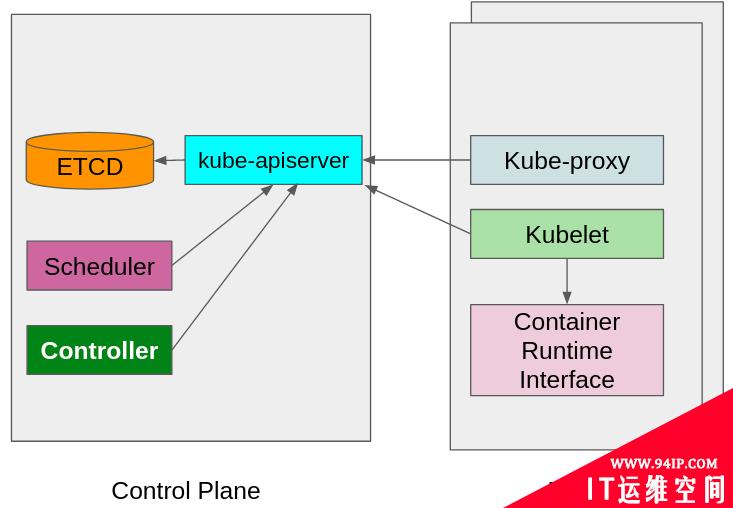
Kubernetes 也分为控制平面和工作节点:
- 控制平面:也称为主控,负责对集群做出全局决策,以及检测和响应集群事件。控制平面组件包括:
- etcd
- kube-apiserver
- kube-controller-manager
- 调度器
- 工作节点:也称节点,这些节点是工作负载所在的位置。它始终和主控联系,以获取工作负载运行所需的信息,并与集群外部进行通讯和连接。工作节点组件包括:
- kubelet
- kube-proxy
- CRI
我希望这个背景信息可以帮助你理解 Kubernetes 组件是如何关联在一起的。
Kubernetes 调度器是如何工作的
Kubernetes吊舱由一个或多个容器组成组成,共享存储和网络资源。Kubernetes 调度器的任务是确保每个吊舱分配到一个节点上运行。
(LCTT 译注:容器技术领域大量使用了航海比喻,pod 一词,意为“豆荚”,在航海领域指“吊舱” —— 均指盛装多个物品的容器。常不翻译,考虑前后文,可译做“吊舱”。)
在更高层面下,Kubernetes 调度器的工作方式是这样的:
- 每个需要被调度的吊舱都需要加入到队列
- 新的吊舱被创建后,它们也会加入到队列
- 调度器持续地从队列中取出吊舱并对其进行调度
调度器源码(
scheduler.go)很大,约 9000 行,且相当复杂,但解决了重要问题:等待/监视吊舱创建的代码
监视吊舱创建的代码始于
scheduler.go的 8970 行,它持续等待新的吊舱:// Run begins watching and scheduling. It waits for cache to be synced, then starts a goroutine and returns immediately.func (sched *Scheduler) Run() {if !sched.config.WaitForCacheSync() {return}go wait.Until(sched.scheduleOne, 0, sched.config.StopEverything)负责对吊舱进行排队的代码
负责对吊舱进行排队的功能是:
// queue for pods that need schedulingpodQueue *cache.FIFO负责对吊舱进行排队的代码始于
scheduler.go的 7360 行。当事件处理程序触发,表明新的吊舱显示可用时,这段代码将新的吊舱加入队列中:func (f *ConfigFactory) getNextPod() *v1.Pod {for {pod := cache.Pop(f.podQueue).(*v1.Pod)if f.ResponsibleForPod(pod) {glog.V(4).Infof("About to try and schedule pod %v", pod.Name)return pod}}}处理错误代码
在吊舱调度中不可避免会遇到调度错误。以下代码是处理调度程序错误的方法。它监听
podInformer然后抛出一个错误,提示此吊舱尚未调度并被终止:// scheduled pod cachepodInformer.Informer().AddEventHandler(cache.FilteringResourceEventHandler{FilterFunc: func(obj interface{}) bool {switch t := obj.(type) {case *v1.Pod:return assignedNonTerminatedPod(t)default:runtime.HandleError(fmt.Errorf("unable to handle object in %T: %T", c, obj))return false}},换句话说,Kubernetes 调度器负责如下:
- 将新创建的吊舱调度至具有足够空间的节点上,以满足吊舱的资源需求。
- 监听 kube-apiserver 和控制器是否创建新的吊舱,然后调度它至集群内一个可用的节点。
- 监听未调度的吊舱,并使用
/binding子资源 API 将吊舱绑定至节点。
例如,假设正在部署一个需要 1 GB 内存和双核 CPU 的应用。因此创建应用吊舱的节点上需有足够资源可用,然后调度器会持续运行监听是否有吊舱需要调度。
了解更多
要使 Kubernetes 集群工作,你需要使以上所有组件一起同步运行。调度器有一段复杂的的代码,但 Kubernetes 是一个很棒的软件,目前它仍是我们在讨论或采用云原生应用程序时的首选。
学习 Kubernetes 需要精力和时间,但是将其作为你的专业技能之一能为你的职业生涯带来优势和回报。有很多很好的学习资源可供使用,而且官方文档也很棒。如果你有兴趣了解更多,建议从以下内容开始:
- Kubernetes the hard way
- Kubernetes the hard way on bare metal
- Kubernetes the hard way on AWS
转载请注明:IT运维空间 » 运维技术 » Kubernetes 调度器是如何工作的
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-
oracle 常用select sql语句
-
JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/6.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值











发表评论