

数据库查询性能优化一直是程序员绕不开的话题,当我们遇到业务刷新报表缓慢或者查询获取结果延迟太大,可以采用提问法来思考如何进行优化。

1. 什么样的环境
硬件环境
query执行的速度和我们的硬件息息相关,当前用的什么样的CPU,有多少核多少线程, 内存有多大都直接影响了运算速度, 磁盘是SSD还是HDD,网卡什么速率都直接影响了我们数据读取的时延
软件环境
软件环境虽然不像硬件一样,各种参数看的见摸得着,但仍然影响着我们的查询性能。没一套系统实际上都在特定的场景有着各自的优势。我们的查询系统是什么样的架构,适合什么样的query,在线还是离线, 计算多还是数据读取多,这些在我们做优化的时候都应该了然于心。
下面我们根据这种思路来看看如何做性能优化
2. 什么样的query
首先我们优化查询的时候,需要看看query 究竟是哪种类型。写入还是查询(这里鉴于篇幅只谈查询), CPU密集还是IO密集。如果我们的系统是适合OLTP低延时点查的场景, 想要在这种系统上做OLAP大规模分析很显然就不太适合, OLTP一般专注于数据一致性较高的点查,而OLAP由于数据量庞大,一般都需要采用向量并发查询。OLAP不专注于毫秒级的低延迟, 而OLTP不专注于上亿级的数据统计。
3. 如何寻找性能瓶颈
3.1 vmstat查看系统情况
整体系统不知道当前的瓶颈在哪里时, 我们可以先用vmstat工具来简单的看一下系统的大致情况。如下图所示,2表示每个两秒采集一次服务器状态。

procs : 查看进程状态
r : 运行队列,即当前可运行(正在运行或者等待运行)的进程数量。目前CPU比较空闲,这个数量很小,当这个值超过了CPU数目,就会出现CPU瓶颈了。
b : 阻塞的进程,即处在不可中断sleep状态下的进程数量。
memory : 查看内存状态
swpd : 已使用的虚拟内存大小,如果大于0,表示机器开始使用虚拟内存了,虚拟内存运行会很慢。这里数值为0表示我们关闭了虚拟内存功能。
free : 空闲的物理内存的大小。
buff : 内存做为系统buffers的大小。
cache : 内存做为系统cache的大小。
swap : 磁盘和内存做数据交换的状态
nesi : 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够。
so : 每秒虚拟内存写入磁盘的大小。
io:磁盘的io信息
bi : 每秒从块设备接收的块数量。
bo : 每秒发送给块设备的块数量。
如果这两个值较大,表示IO比较频繁,可以考虑IO优化。
system : 系统状态信息
in : 每秒CPU的中断次数(包括时钟中断)
cs : 每秒上下文切换次数,我们调用系统函数、线程的切换,就需要上下文切换,这个值要太大就可以考虑 减少系统的上下文切换,比如协程替代多线程等方式。
CPU : CPU信息
us : 包括用户时间和nice时间,跑非内核的代码(或者用户代码)的时间。
sy : 系统占用时间,跑内核代码(比如系统调用)占用的时间。
id : 花费在idle上的 CPU时间。
wa : 等待IO CPU时间。如果这个值太大,表示IO系统瓶颈在IO上。
如果CPU占用高表示系统在CPU上, 如果系统的swap比较频繁,很可能是系统内存泄露或者内存不够用,需要扩展内存, 如果是IO等待较多则系统瓶颈出现在IO上,如果上下文切换,或者系统调用占比太大,则我们需要思考下我们程序的设计,减少系统调用或者上下文切换。
3.2 CPU占用过高
我们可以通过uptime、top、mpstat或者sar等一些工具来查看当前CPU占用过高的情况.
我们可以通过uptime看看当前系统的整体情况, 当前的系统时间和运行时间, 登陆的用户数量,还有最近5、10和15分钟的系统平均负载。

top则可以显示较详细的信息。head部分有CPU占用的详细信息, 下面的列表也有记录每个进程占用的CPU情况。
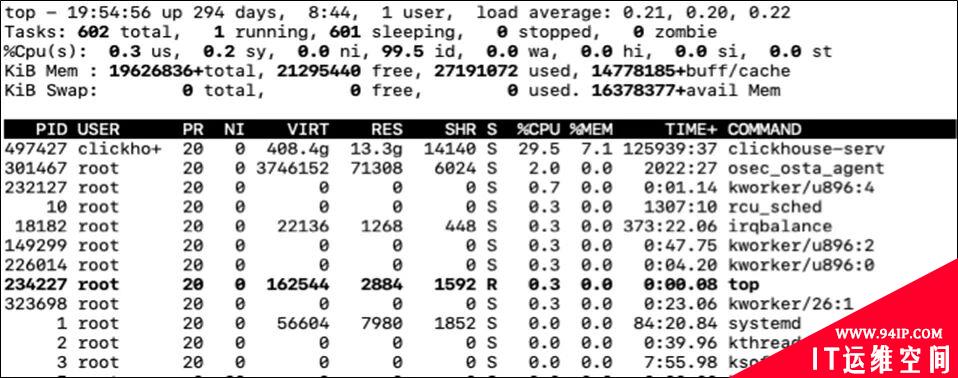
如果是多线程, 我们还可以通过top -H -p pid来查看进程的每个线程的CPU占用情况
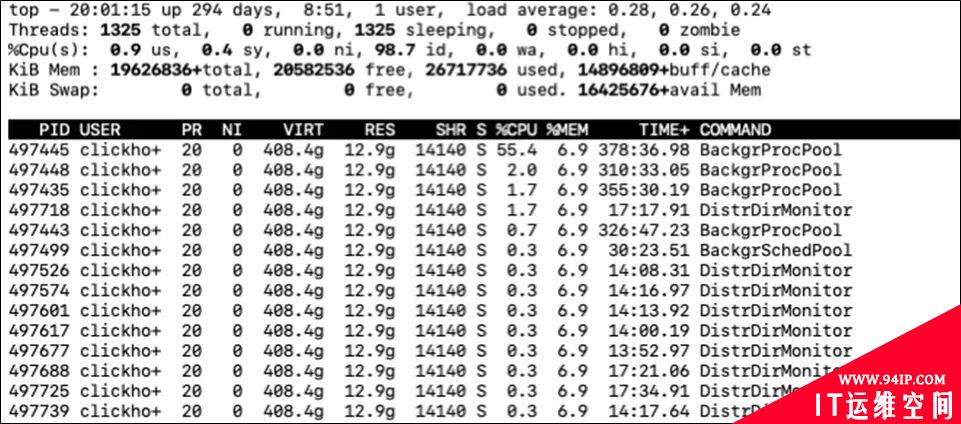
我们找到哪个线程占用的比例多之后, 可以根据这个线程的线程名查看该线程是用来做什么处理的。大致了解下是什么样的处理让CPU比较高。
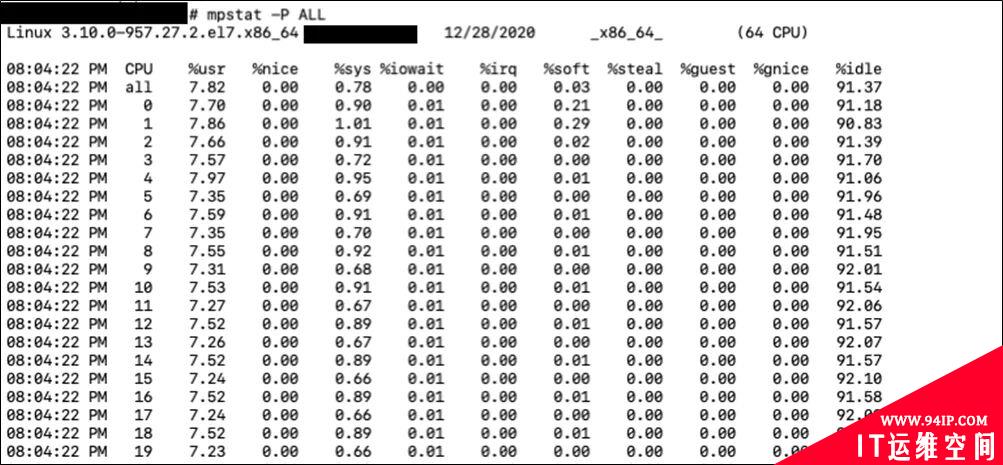
mpstat则可以查看系统每个核的运行状态。
sar的功能比较全,这里不再做科普。
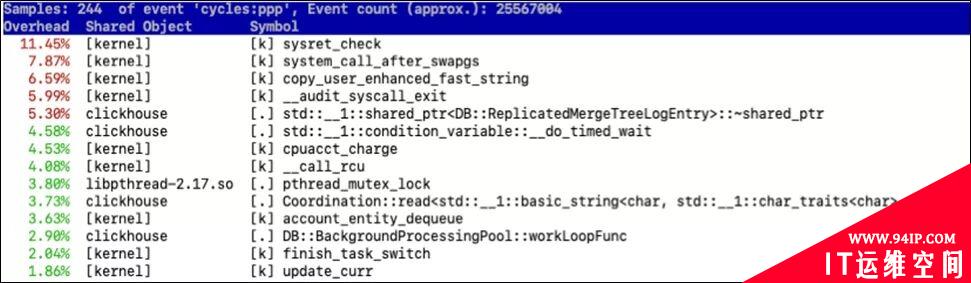
CPU用户态的占用比较高,一般就是我们的程序编写的效率太低,具体哪里低,我们可以通过perf工具或者Intel的vtunes来查看性能瓶颈。perf top的执行结果如下图所示, 我们拿到对应的堆栈信息之后, 就可以针对性的消除CPU瓶颈了。(vtune的用法可以自行谷歌)。
鉴于上述工具检查出来的情况, 如果CPU确实水位很高,则CPU基本就是性能瓶颈。如果不高则,需要进行下一步来判断性能瓶颈。
3.3 IO占用过高的情况
IO定位的工具多种多样, 一般查看IO问题我们可以使用iostat、pidstat和iotop工具。当然我们也可以使用其他的工具,大家可以自己搜索相关的工具使用, 这里主要介绍常用的几种工具。
pidstat
pidstat是sysstat工具的一个命令,用于监控全部或指定进程的cpu、内存、线程、设备IO等系统资源的占用情况。用户可以通过指定统计的次数和时间来获得所需的统计信息。
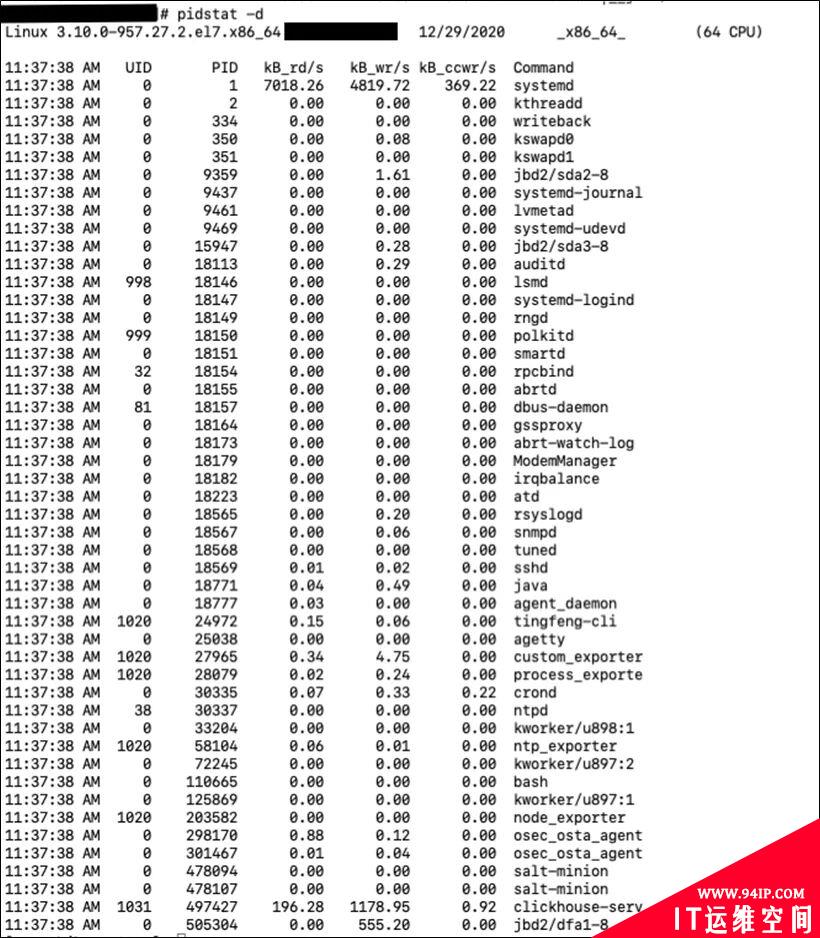
我们通过这个命令可以知道哪个进程占用的IO比较多。然后我们可以通过指定进程号的方式查看更详细的信息。
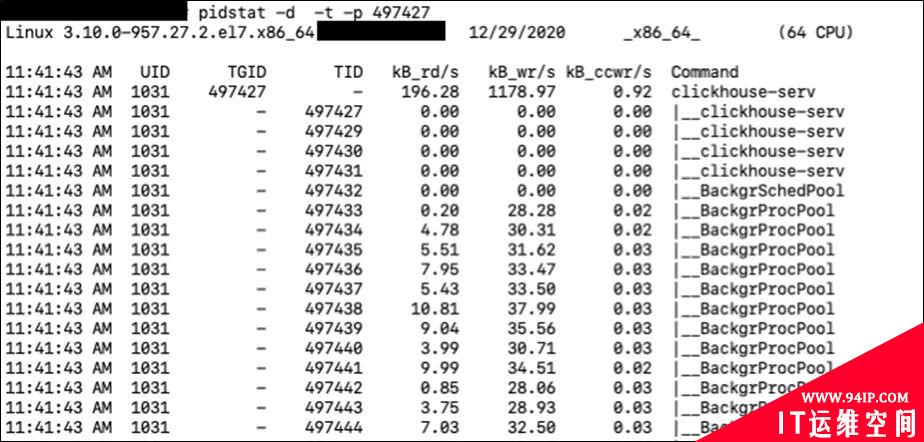
这样我们就可以知道是哪个进程中的哪个线程占用了较多的IO资源,然后我们可以通过对应的TID,找到对应的执行代码进行分析。
iostat
iostat是I/O statistics(输入/输出统计)的缩写,它可以对系统的磁盘操作活动进行监控,汇报磁盘活动统计情况。但是iostat仅对系统的整体情况进行统计,不能对某个进程进行深入分析,单独的进程分析我们可以用iotop工具,使用方法和top类似。
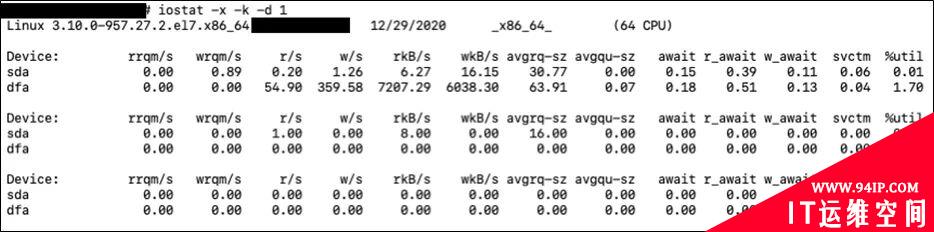
1 表示每秒打印一次当前磁盘的统计信息。我们需要注意的是后面几个指标。

avgrq-sz直接反应了当前io的种类,比如大块数据读取还是小数据量的读取。
avgqu-sz反应了当前IO的繁忙情况, 如果队列长度太长,说明IO现在很忙很多任务处理不过来,换句话说 I,IO成为了瓶颈。
await 也是一样, 如果等待比较高,说明IO成了累赘。
svctm则和avgrq-sz一样,反应了IO操作的处理规模,如果是大块数据读写, 这个时间就会拉长。
iotop
iotop 可以用于查看哪些进程执行占用了的 I/O,使用方式和top类似,这里不再做过多描述。

3.4 其他情况
如果TOP占用不高, IO也不是瓶颈,则可能处在程序架构上, 比如并发控制的不够好有较多的线程在sleep状态。这种情况可以通过pstack看看当前所有线程的堆栈。
4. 优化性能瓶颈
CPU瓶颈型
面对这种类型,一般我们需要通过perf配合对应的代码去进行优化,核心思想就是减少计算的量。具体方法以下仅供
转载请注明:IT运维空间 » 运维技术 » 数据库查询性能优化指南
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-
oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值









发表评论