


前言
有位朋友去阿里面试,他说面试官给了几条查询SQL,问:需要执行几次树搜索操作?我朋友当时是有点懵的,后来冷静思考,才发现就是考索引的几个基础知识点~~ 本文我们分九个索引知识点,一起来探讨一下。如果有不正确的话,欢迎指出哈,一起学习~
- 面试官考点之索引是什么?
- 面试官考点之索引类型
- 面试官考点之为什么选择B+树作索引结构
- 面试官考点之一次索引搜索过程
- 面试官考点之覆盖索引
- 面试官考点之索引失效场景
- 面试官考点之最左前缀
- 面试官考点之索引下推
- 面试官考点之大表添加索引
一、面试官考点之索引是什么?
索引是一种能提高数据库查询效率的数据结构。它可以比作一本字典的目录,可以帮你快速找到对应的记录。
索引一般存储在磁盘的文件中,它是占用物理空间的。
正所谓水能载舟,也能覆舟。适当的索引能提高查询效率,过多的索引会影响数据库表的插入和更新功能。
二、索引有哪些类型类型
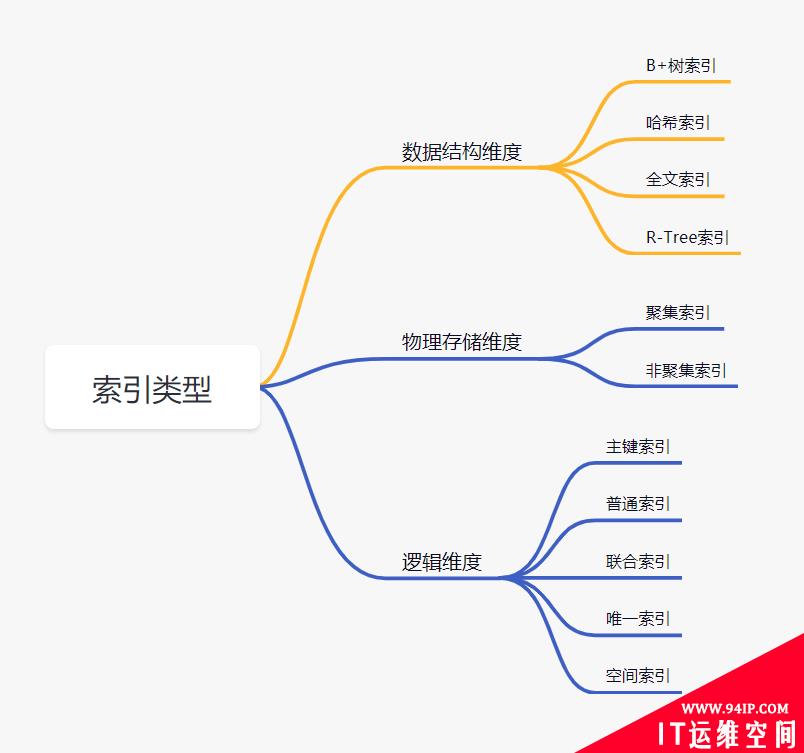
数据结构维度
- B+树索引:所有数据存储在叶子节点,复杂度为O(logn),适合范围查询。
- 哈希索引: 适合等值查询,检索效率高,一次到位。
- 全文索引:MyISAM和InnoDB中都支持使用全文索引,一般在文本类型char,text,varchar类型上创建。
- R-Tree索引: 用来对GIS数据类型创建SPATIAL索引
物理存储维度
- 聚集索引:聚集索引就是以主键创建的索引,在叶子节点存储的是表中的数据。
- 非聚集索引:非聚集索引就是以非主键创建的索引,在叶子节点存储的是主键和索引列。
逻辑维度
- 主键索引:一种特殊的唯一索引,不允许有空值。
- 普通索引:MySQL中基本索引类型,允许空值和重复值。
- 联合索引:多个字段创建的索引,使用时遵循最左前缀原则。
- 唯一索引:索引列中的值必须是唯一的,但是允许为空值。
- 空间索引:MySQL5.7之后支持空间索引,在空间索引这方面遵循OpenGIS几何数据模型规则。
三、面试官考点之为什么选择B+树作为索引结构
可以从这几个维度去看这个问题,查询是否够快,效率是否稳定,存储数据多少,以及查找磁盘次数等等。为什么不是哈希结构?为什么不是二叉树,为什么不是平衡二叉树,为什么不是B树,而偏偏是B+树呢?
我们写业务SQL查询时,大多数情况下,都是范围查询的,如下SQL
select*fromemployeewhereagebetween18and28;
为什么不使用哈希结构?
我们知道哈希结构,类似k-v结构,也就是,key和value是一对一关系。它用于「等值查询」还可以,但是范围查询它是无能为力的哦。
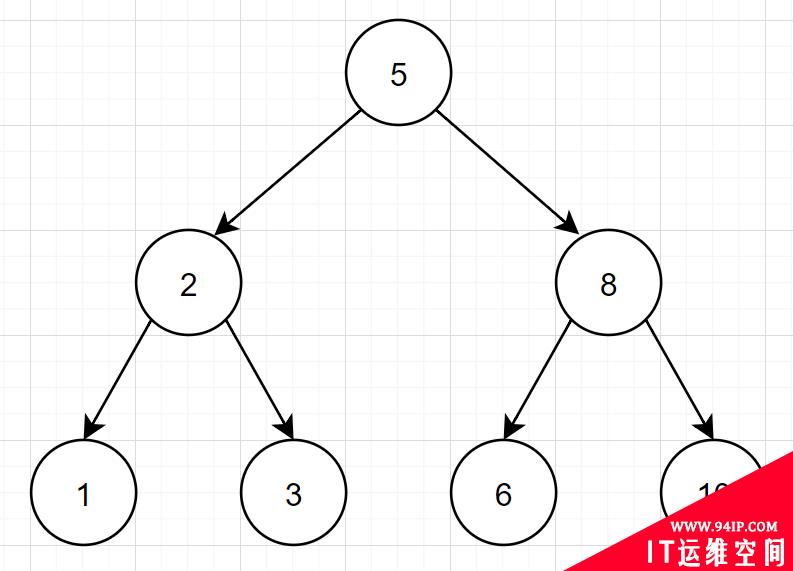
为什么不使用二叉树呢?
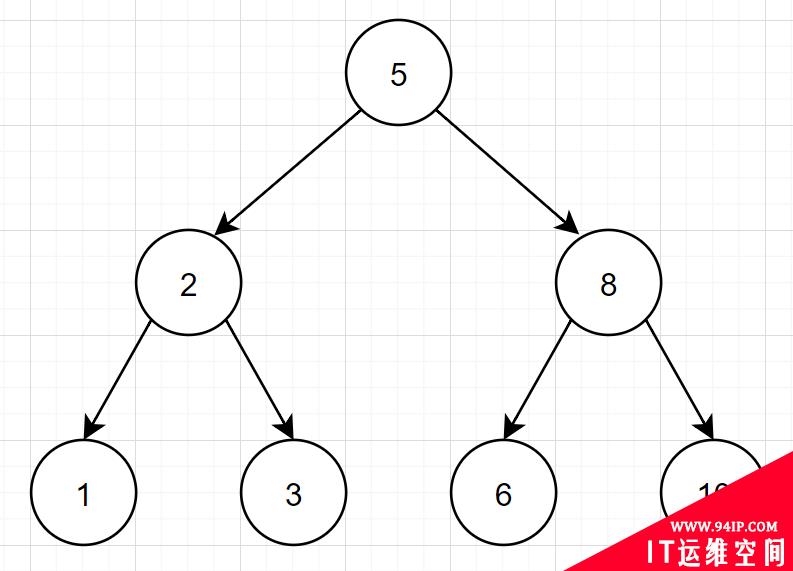
先回忆下二叉树相关知识啦~ 所谓「二叉树,特点如下:」
- 每个结点最多两个子树,分别称为左子树和右子树。
- 左子节点的值小于当前节点的值,当前节点值小于右子节点值
- 顶端的节点称为根节点,没有子节点的节点值称为叶子节点。
我们脑海中,很容易就浮现出这种二叉树结构图:
但是呢,有些特殊二叉树,它可能这样的哦:
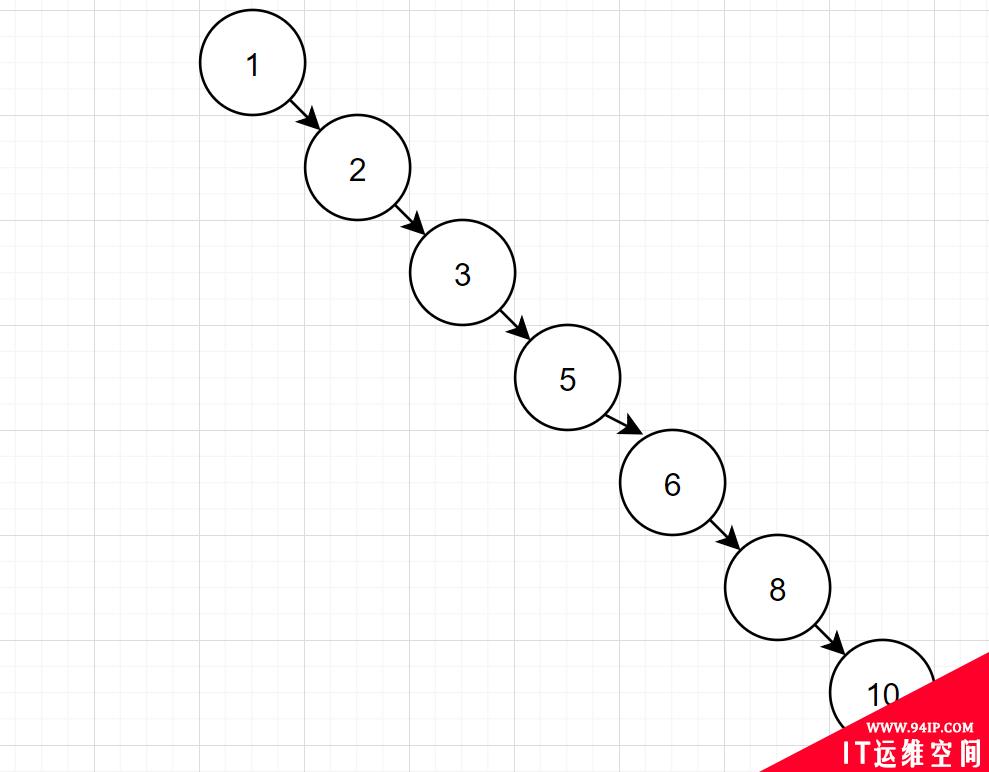
如果二叉树特殊化为一个链表,相当于全表扫描。那么还要索引干嘛呀?因此,一般二叉树不适合作为索引结构。
为什么不使用平衡二叉树呢?
平衡二叉树特点:它也是一颗二叉查找树,任何节点的两个子树高度最大差为1。所以就不会出现特殊化一个链表的情况啦。
但是呢:
- 平衡二叉树插入或者更新时,需要左旋右旋维持平衡,维护代价大
- 如果数量多的话,树的高度会很高。因为数据是存在磁盘的,以它作为索引结构,每次从磁盘读取一个节点,操作IO的次数就多啦。
为什么不使用B树呢?
数据量大的话,平衡二叉树的高度会很高,会增加IO嘛。那为什么不选择同样数据量,「高度更矮的B树」呢?
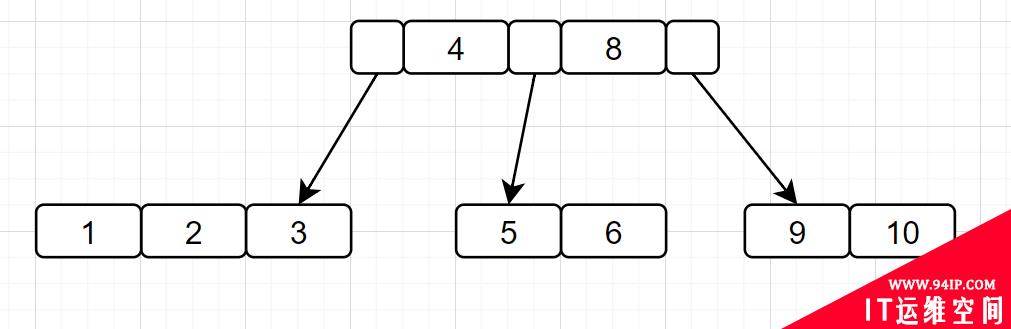
B树相对于平衡二叉树,就可以存储更多的数据,高度更低。但是最后为甚选择B+树呢?因为B+树是B树的升级版:
B+树非叶子节点上是不存储数据的,仅存储键值,而B树节点中不仅存储键值,也会存储数据。innodb中页的默认大小是16KB,如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的IO次数有会再次减少,数据查询的效率也会更快。
B+树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的,链表连着的。那么B+树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。
四、面试官考点之一次B+树索引搜索过程
「面试官:」 假设有以下表结构,并且有这几条数据
CREATETABLE`employee`( `id`int(11)NOTNULL, `name`varchar(255)DEFAULTNULL, `age`int(11)DEFAULTNULL, `date`datetimeDEFAULTNULL, `sex`int(1)DEFAULTNULL, PRIMARYKEY(`id`), KEY`idx_age`(`age`)USINGBTREE )ENGINE=InnoDBDEFAULTCHARSET=utf8; insertintoemployeevalues(100,'小伦',43,'2021-01-20','0'); insertintoemployeevalues(200,'俊杰',48,'2021-01-21','0'); insertintoemployeevalues(300,'紫琪',36,'2020-01-21','1'); insertintoemployeevalues(400,'立红',32,'2020-01-21','0'); insertintoemployeevalues(500,'易迅',37,'2020-01-21','1'); insertintoemployeevalues(600,'小军',49,'2021-01-21','0'); insertintoemployeevalues(700,'小燕',28,'2021-01-21','1');
「面试官:」 如果执行以下的查询SQL,需要执行几次的树搜索操作?可以画下对应的索引结构图~
select*fromTemployeewhereage=32;
「解析:」 其实这个,面试官就是考察候选人是否熟悉B+树索引结构图。可以像酱紫回答~
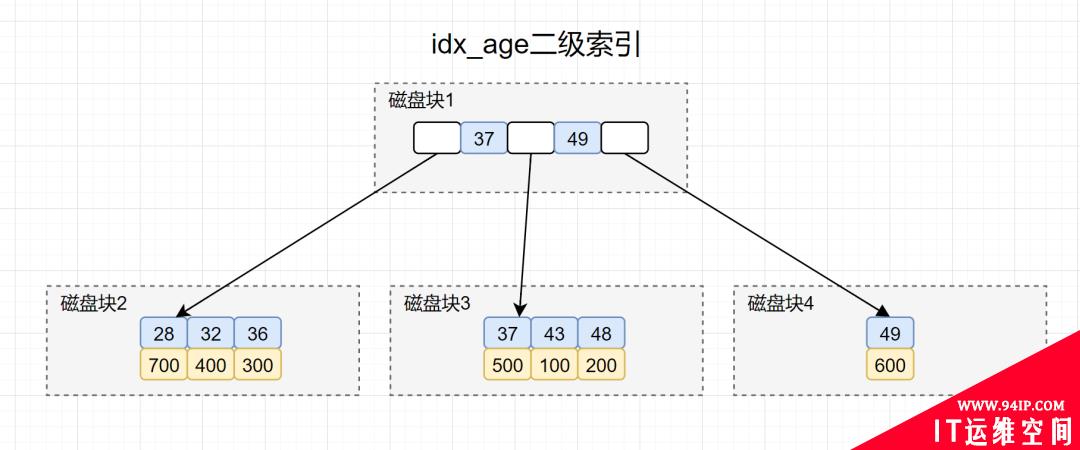
先画出idx_age索引的索引结构图,大概如下:
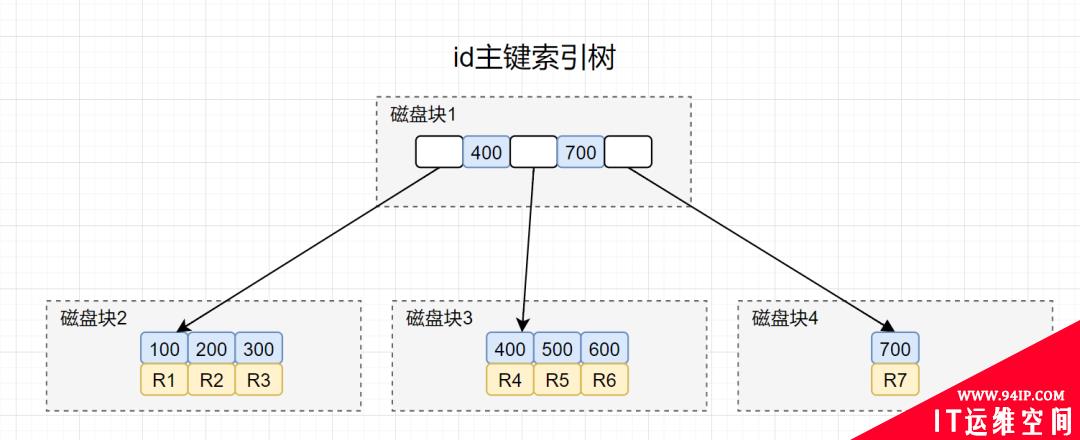
再画出id主键索引,我们先画出聚族索引结构图,如下:
因此,这条 SQL 查询语句执行大概流程就是酱紫:
- 搜索idx_age索引树,将磁盘块1加载到内存,由于32<37,搜索左路分支,到磁盘寻址磁盘块2。
- 将磁盘块2加载到内存中,在内存继续遍历,找到age=32的记录,取得id = 400.
- 拿到id=400后,回到id主键索引树。
- 搜索id主键索引树,将磁盘块1加载内存,在内存遍历,找到了400,但是B+树索引非叶子节点是不保存数据的。索引会继续搜索400的右分支,到磁盘寻址磁盘块3.
- 将磁盘块3加载内存,在内存遍历,找到id=400的记录,拿到R4这一行的数据,好的,大功告成。
因此,这个SQL查询,执行了几次树的搜索操作,是不是一步了然了呀。「特别的」,在idx_age二级索引树找到主键id后,回到id主键索引搜索的过程,就称为回表。
什么是回表?拿到主键再回到主键索引查询的过程,就叫做「回表」
五、面试官考点之覆盖索引
「面试官:」 如果不用select *, 而是使用select id,age,以上的题目执行了几次树搜索操作呢?
「解析:」 这个问题,主要考察候选人的覆盖索引知识点。回到idx_age索引树,你可以发现查询选项id和age都在叶子节点上了。因此,可以直接提供查询结果啦,根本就不需要再回表了~
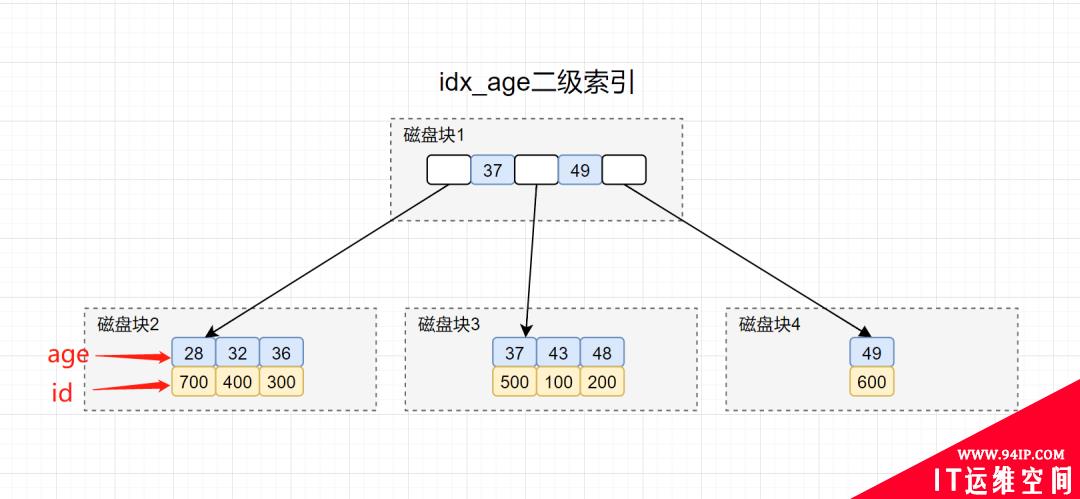
覆盖索引:在查询的数据列里面,不需要回表去查,直接从索引列就能取到想要的结果。换句话说,你SQL用到的索引列数据,覆盖了查询结果的列,就算上覆盖索引了。
所以,相对于上个问题,就是省去了回表的树搜索操作。
六、面试官考点之索引失效
「面试官:」 如果我现在给name字段加上普通索引,然后用个like模糊搜索,那会执行多少次查询呢?SQL如下:
select * from employee where name like ‘%杰伦%’;
「解析:」 这里考察的知识点就是,like是否会导致不走索引,看先该SQL的explain执行计划吧。其实like 模糊搜索,会导致不走索引的,如下:
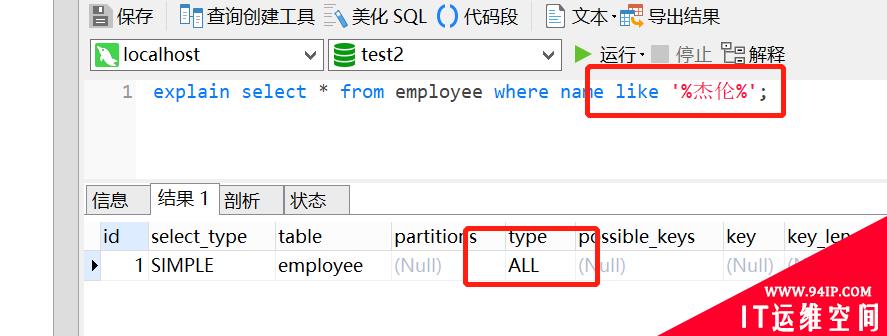
因此,这条SQL最后就全表扫描啦~日常开发中,这几种骚操作都可能会导致索引失效,如下:
- 查询条件包含or,可能导致索引失效
- 如何字段类型是字符串,where时一定用引号括起来,否则索引失效
- like通配符可能导致索引失效。
- 联合索引,查询时的条件列不是联合索引中的第一个列,索引失效。
- 在索引列上使用mysql的内置函数,索引失效。
- 对索引列运算(如,+、-、*、/),索引失效。
- 索引字段上使用(!= 或者 < >,not in)时,可能会导致索引失效。
- 索引字段上使用is null, is not null,可能导致索引失效。
- 左连接查询或者右连接查询查询关联的字段编码格式不一样,可能导致索引失效。
- mysql估计使用全表扫描要比使用索引快,则不使用索引。
七、面试官考点联合索引之最左前缀原则
「面试官:」 如果我现在给name,age字段加上联合索引索引,以下SQL执行多少次树搜索呢?先画下索引树?
select*fromemployeewherenamelike'小%'orderbyagedesc;
「解析:」 这里考察联合索引的最左前缀原则以及like是否中索引的知识点。组合索引树示意图大概如下:
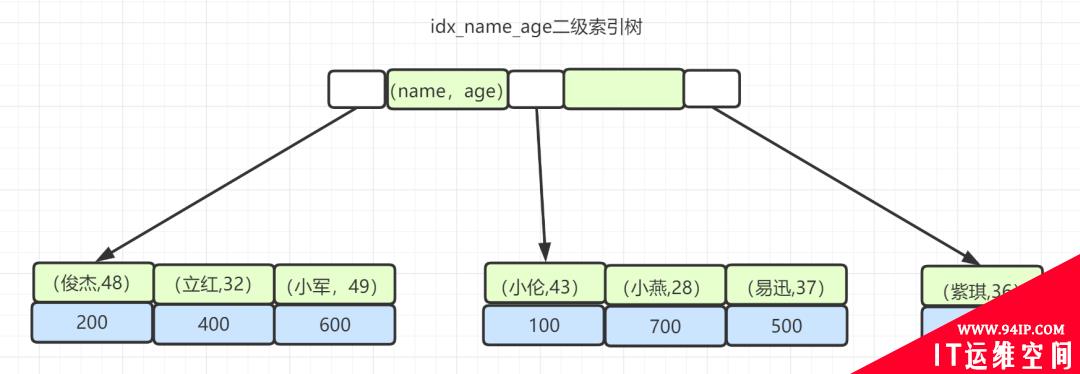
联合索引项是先按姓名name从小到大排序,如果名字name相同,则按年龄age从小到大排序。面试官要求查所有名字第一个字是“小”的人,SQL的like ‘小%’是可以用上idx_name_age联合索引的。
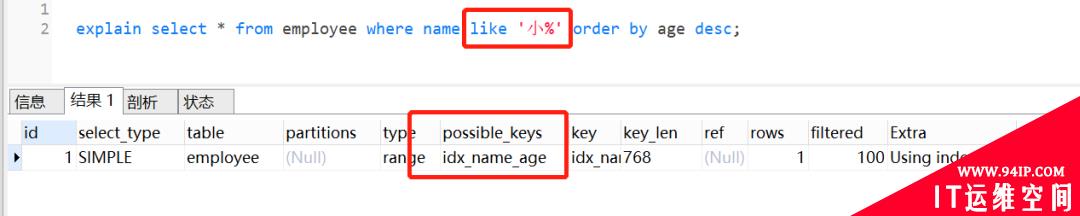
该查询会沿着idx_name_age索引树,找到第一个字是小的索引值,因此依次找到小军、小伦、小燕、,分别拿到Id=600、100、700,然后回三次表,去找对应的记录。这里面的最左前缀小,就是字符串索引的最左M个字符。实际上,
这个最左前缀可以是联合索引的最左N个字段。比如组合索引(a,b,c)可以相当于建了(a),(a,b),(a,b,c)三个索引,大大提高了索引复用能力。
最左前缀也可以是字符串索引的最左M个字符。
八、面试官考点之索引下推
「面试官:」 我们还是居于组合索引 idx_name_age,以下这个SQL执行几次树搜索呢?
select * from employee where name like ‘小%’ and age=28 and sex=’0′;
「解析:」 这里考察索引下推的知识点,如果是「Mysql5.6之前」,在idx_name_age索引树,找出所有名字第一个字是“小”的人,拿到它们的主键id,然后回表找出数据行,再去对比年龄和性别等其他字段。如图:
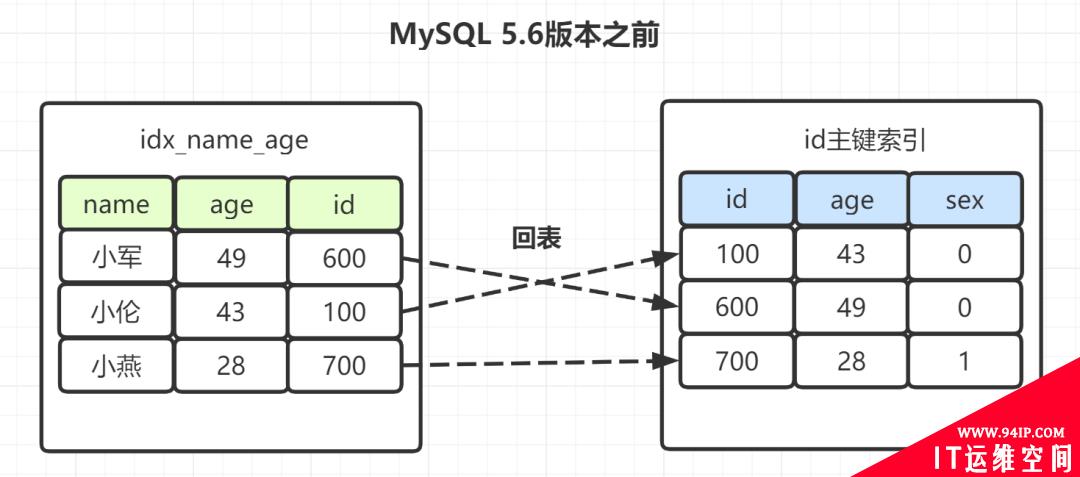
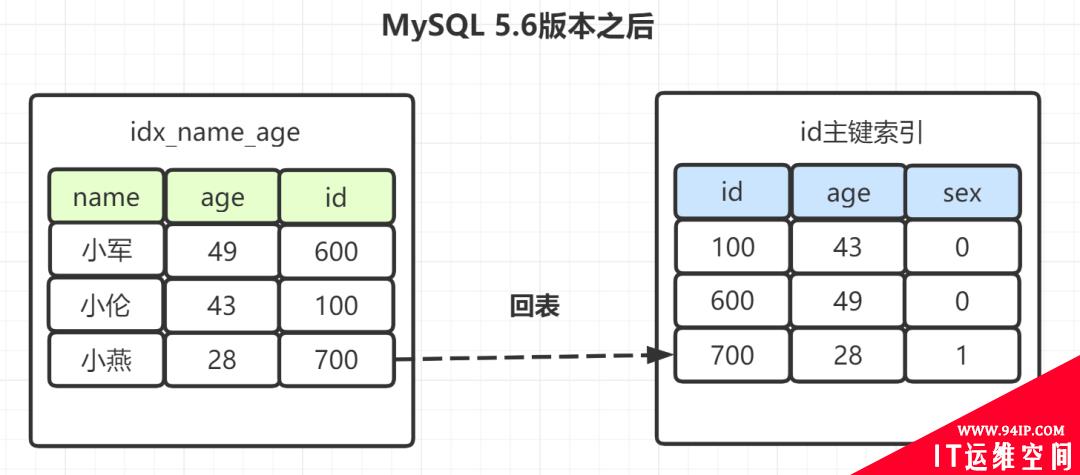
有些朋友可能觉得奇怪,(name,age)不是联合索引嘛?为什么选出包含“小”字后,不再顺便看下年龄age再回表呢,不是更高效嘛?所以呀,MySQL 5.6 就引入了「索引下推优化」,可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
因此,MySQL5.6版本之后,选出包含“小”字后,顺表过滤age=28,,所以就只需一次回表。
九、 面试官考点之大表添加索引
「面试官:」 如果一张表数据量级是千万级别以上的,那么,给这张表添加索引,你需要怎么做呢?
「解析:」 我们需要知道一点,给表添加索引的时候,是会对表加锁的。如果不谨慎操作,有可能出现生产事故的。可以参考以下方法:
1.先创建一张跟原表A数据结构相同的新表B。
2.在新表B添加需要加上的新索引。
3.把原表A数据导到新表B
4.rename新表B为原表的表名A,原表A换别的表名;
总结与练习
本文主要讲解了索引的9大关键面试考点,希望对大家有帮助。接下来呢,给大家出一道,有关于我最近业务开发遇到的加索引SQL,看下大家是怎么回答的,有兴趣可以联系我,一起讨论哈~题目如下:
select*fromAwheretype='1'andstatus='s'orderbycreate_timedesc;
假设type有9种类型,区分度还算可以,status的区分度不高(有3种类型),那么你是如何加索引呢?
- 是给type加单索引
- 还是(type,status,create_time)联合索引
- 还是(type,create_time)联合索引呢?
参看与感谢
MySQL有哪些索引类型 ?[1]
大表加索引方案[2]
MySQL实战45讲[3]
[1]MySQL有哪些索引类型 ?:
https://segmentfault.com/q/1010000003832312
[2]大表加索引方案:
https://zhuanlan.zhihu.com/p/151460679
[3]MySQL实战45讲:
https://time.geekbang.org/column/article/69636
转载请注明:IT运维空间 » 运维技术 » 阿里一面,给了几条SQL,问需要执行几次树搜索操作?
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-
oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/1.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值







发表评论