


多年以前,那时我正年轻,做技术如鱼得水,甚至一度希望自己能当一辈子的一线程序员。
但是我又有两个小愿望想要达成:一个是想多挣点钱;另一个就是对项目的技术栈和架构选型能多有点主动权。
多挣点钱是因为当时我刚结婚不久,有自己的家庭规划,所以挣钱的欲望也蛮强。
而想有多点技术主动权的原因则是当时领导很赏识我,有些东西逐渐的放权让我做,我尝到了甜头,所以,也有了自己的一些小野心。
而正巧就在那时候,领导给我了一个现在看来职业生涯中还挺重要的机会。
当时,广告联盟正是发展的如火如荼的时候,公司也想参与进去分杯羹,于是决定从零开始搞一套广告平台。
而我正好也有些类似的开发经验,且做事还算靠谱,于是,领导便想着让我去当这套系统的技术负责人。
如果我能把系统做好,对我来说绝对是个证明自己的机会,对以后达成我的两个小愿望有好处。对我诱惑很大。
只是,老天给你开了一扇门,就总要给你关一扇窗。这个机会不仅仅是我领导看上了,当时,还有另外一个部门的老大也瞄上了。
不得已,上了高层会议讨论。讨论来讨论去的结果就是学习当时别的公司的做法,内部竞争。
两个部门做各做一套平台,然后各放到线上运营一阵子,谁做得好谁就能得到公司全力投入的机会。
好吧,机会变成了冒险。只是到此时,我也并不能退缩。一旦我退缩会连累赏识我的领导,而且将来在公司的发展也会严重受阻,只能冲了。
为了赢得这场竞争,我和这套系统的产品负责人也沟通了许久。最后定下来了两个必须实现的目标:
1. 这套系统功能一定要尽量多,尤其是提供给相关业务人员的功能要多。
之所以要这样,是因为现在是内部竞争。而对于内部竞争,使用我们这套系统的业务人员话语权其实非常大,他们的满意度很可能是最终评估的胜负手。
同时,我们也计划为投放在我们这套系统的广告主们多准备一些体验度非常好的数据追踪和分析功能,这样能最大的增加我们产品的吸引力。
2. 这套系统的稳定性和可靠性要求非常高,有时候哪怕为此做一些过度设计和实现也是值得的。
这里要解释下稳定性和可靠性在我们当时那个场景里的含义。稳定性就是要保证性能是稳定的,也就是说我们的系统响应时间应该尽全力保证在一个很短的时间内响应。
而可靠性则是我们的系统应该尽全力保证不出错,因为出错很可能就会造成用户流失,导致我们的产品失败。
定完目标以及产品给完需求后,我就和团队进入了异常艰苦的开发工作。那时候,我真的是付出了我全身心的心血。
其实,我本来是个享受生活胜过埋头苦干的人。虽然此前工作也很忙碌,但是空闲日子也是过得很惬意的。听听歌,看看电影,有时和老婆找家餐厅享用美食,时不时的也会踢一场酣畅淋漓的足球。
可是,自从开始投入了这套广告系统的开发以后,悠闲的日子就一去不复返了。
我记得那时候我下班是踉踉跄跄的走,上班又是踉踉跄跄的来。当时最大的心愿就是有张床,躺下去永远别有人叫醒我。
可是即使这样辛苦,我依然遇到了数不清的难题,这些横亘在开发路上的硬骨头,导致我的开发目标一再被调整。
其中最麻烦的,就是高并发的性能问题。
当时我的经验尚浅,Java 说实话周边的生态也并不完善。能用来承载访问的也就是缓存和数据库。同时,由于版权等问题,我还只能选择 MySQL 数据库。
为了解决这些性能问题,我还特意把官方的 MySQL 手册打印了出来,天天钻研。
开始的时候,为了抗住预想中的超高并发量,我采用的是当时很流行的读写分离模式。
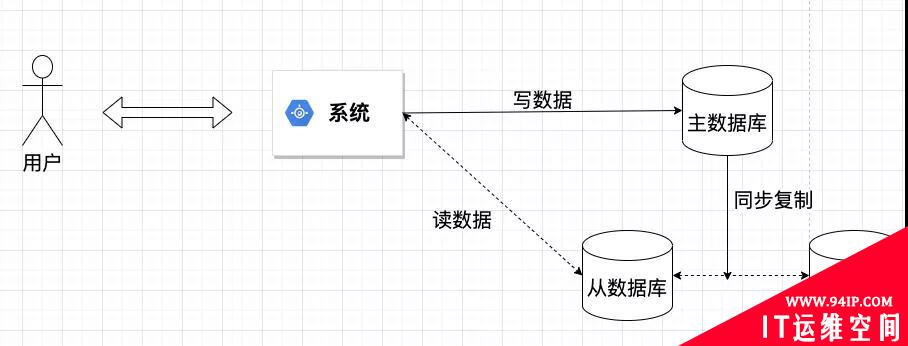
但是,实际测试下来,总是有各种不满意的地方。其中最麻烦的就是各种复杂查询的性能。
我说过为了获得内部竞争的胜利,这套系统我们尽可能想去往高并发、多功能这两个目标上靠。所以,为了这两个目标,这套系统其实多了很多方便业务人员使用的功能,并且这个功能设想的目标是:
在高并发下,也依然保持稳定和流畅。
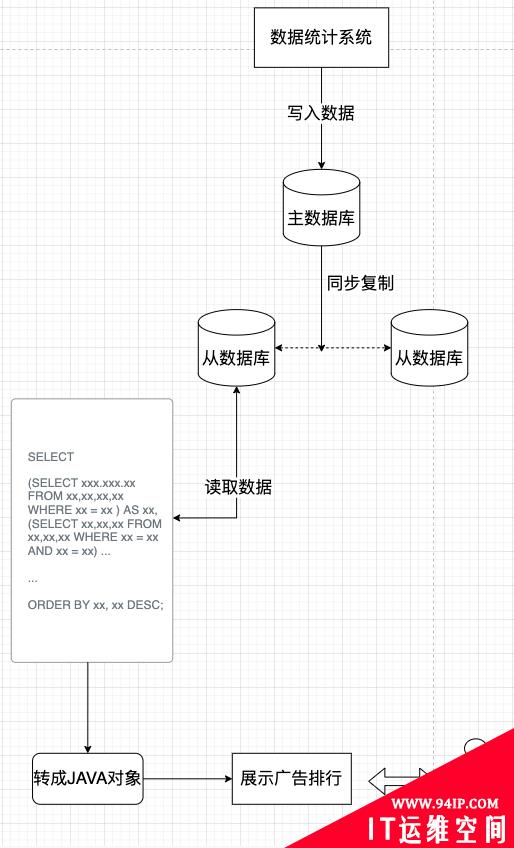
其中,最典型的一个业务就是可以实时更新的广告投放排行功能。
这个广告投放排行需求是这样的:
- 首先,我们的用户要能在管理后台看到他们自己的投放广告排行,排名是根据消费的金额和点击次数等指标来排次序。
- 其次,在我们的后台,也给业务人员也搞了个这么个排名,不同的是它是个全局的,是我们所有客户投放的广告的一个总排行。
- 然后,这个排名要能实时的根据消费金额和点击次数的变化而变化。当然,这个实时可以搞成准实时,只要别延迟太过也可以。
本身呢,做排行榜由于用的指标比较多,就需要写很复杂的 SQL 去数据库中查询。再加上个需要实时变化,那就得不停的去数据库中查询。
而对于这种情况,我无论如何优化总是得不到满意的结果。如果我缓存这个排行呢,由于这个排行需要各种统计加排序,所以从数据库中查询出来后,还需要各种模型转换,如果并发量上来,查询再转换,性能真的掉的飞快。
那时候,我的压力非常大,脑子一直在想着性能问题,手上的 MySQL 手册翻得都快烂的掉了页。就连回到家睡觉时,眼睛闭上脑海里总是想着如何解决这些问题。
最终上线的时间不断地逼近,手上的项目却死死卡在这些性能难题上难以进展,竞争对手却时不时听到内部竞争对手顺利进行到某某程度的消息。
这一切的一切我快扛不住了,内心劝自己放弃的声音也越来越大。
我曾经一度认为自己是一个韧性非常强的人,但是现在看来,其实也就是个再普通不过的打工仔而已。
我要逃避了,我想去和产品商量就这样上线吧,我不想管了,是死是活看老天爷吧,赌对方也遇到我这种问题,甚至还不如我。
只是就在我准备拉上产品最终确定就这样上线的时候,我内心强烈的不甘阻止了我。我想在我放弃之前,无论如何要知道竞争对手怎么样了,对方有什么方案和思路可供我参考的。
我找遍了我所有公司的熟人,去不停的打探竞争对手的消息。但是,结果并不好,因为对方比我做的更绝,他们进行了封闭式的开发,而且警惕性非常高。
最终,我只得到了一个关键词:CQRS。对方用 CQRS 来解决性能问题!!!
我年少读书,那时还没有手机,总是能一心一意的做好读书这件事,读书效率极高。但是如今有了手机,现在我再读书,总是时不时会分心去看看手机里的信息,有时候为了好好把书读进去,还不得不把手机特意丢在远处,防止分心。
而 CQRS 就是这种思路。这个模式与其说是一种架构模式还不如说是一种思想。
CQRS 认为一套系统里的操作,总共就分为读和写两大类。如果一套系统不专门把读和写专门分开优化,那么系统就像我读书带着手机那样,会一心两用,从而因为彼此影响,导致各自的性能无法达到最优。
所以,读写应该专门的分开,并分别优化。
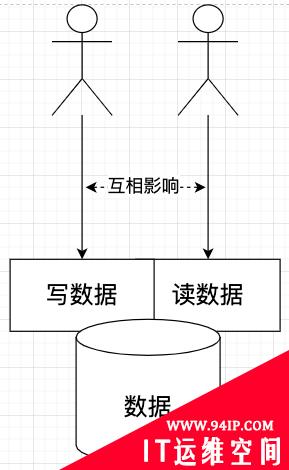
在 CQRS 里,写这种行为被称为命令,而读行为被称为查询。因为想让他们分开,所以 CQRS 模式中文翻译过来就被称为命令查询权责分离模式。
我知道这套思路之后,本来并不在意,因为乍一看,这套东西其实和我采用的数据库的读写分离是一样的,就是把读写给分开。
但是,我的技术直觉告诉我,这些并没有那么简单。
在计算机的世界里,一个名词不会无缘无故出现,也不会无缘无故的开始流行。如果真的和数据库的读写分离一样,那直接叫数据库读写分离就好了。一定有什么不一样了。
我没再满足于中文的搜索结果了,我直接去了 Martin Flower 的网站看原始版本去了。然后,我发现了这样一幅架构图。
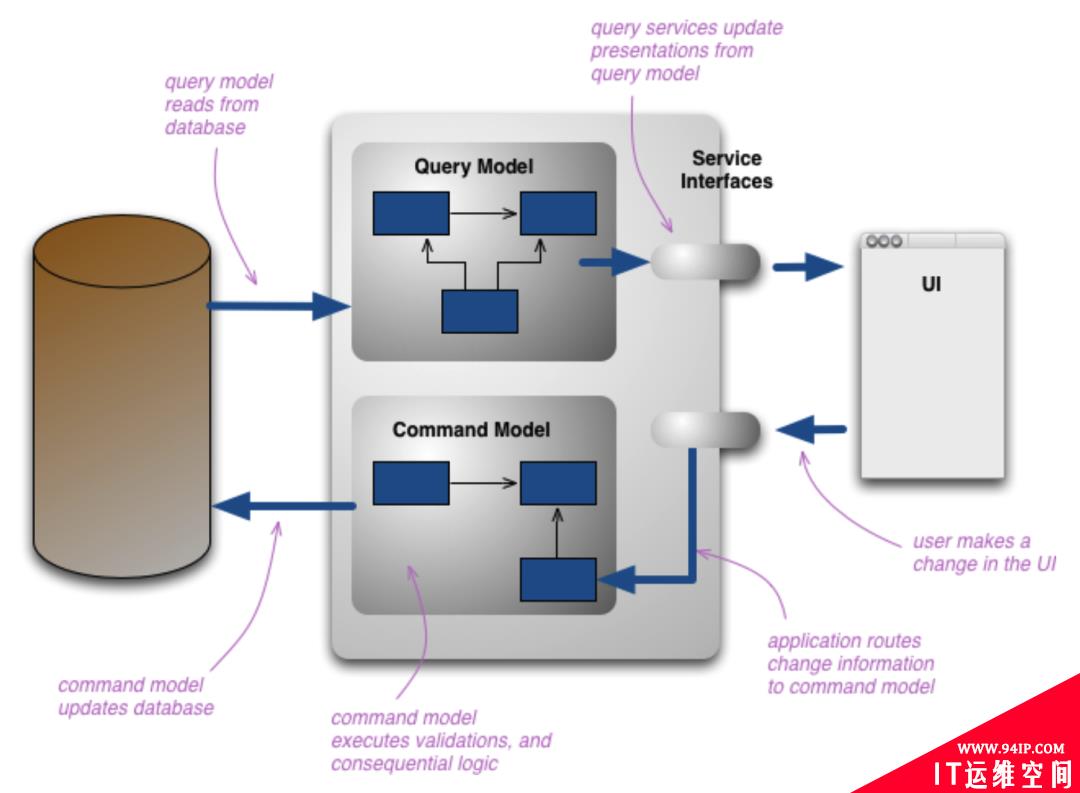
再结合他的原文我一下子明白了,是模型,模型的不同!
原来的数据库读写分离确实把读写的这两个行为分开了,但是它依然有一个重要的事情没有做,那就是职责的分开。
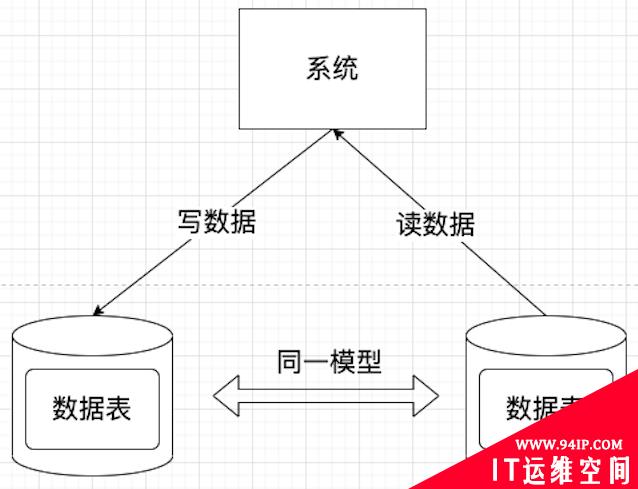
什么叫职责的分开呢?就是读写双方不要搞同一套模型。而数据库读写分离的问题就在这里,它使用了同一个模型。
使用同一个模型在这里造成的问题是,这个模型由于既要考虑读取数据不能太困难,也要考虑写入数据不能太困难。
而这个恰恰就是违背了 CQRS 中的核心思想:读写彻底自由。
如果我们使用 CQRS 思想的话,假设写入不需要关心读取的问题,读取数据也不用关心写入的问题,那么双方是不是可以彻底放飞自我了?
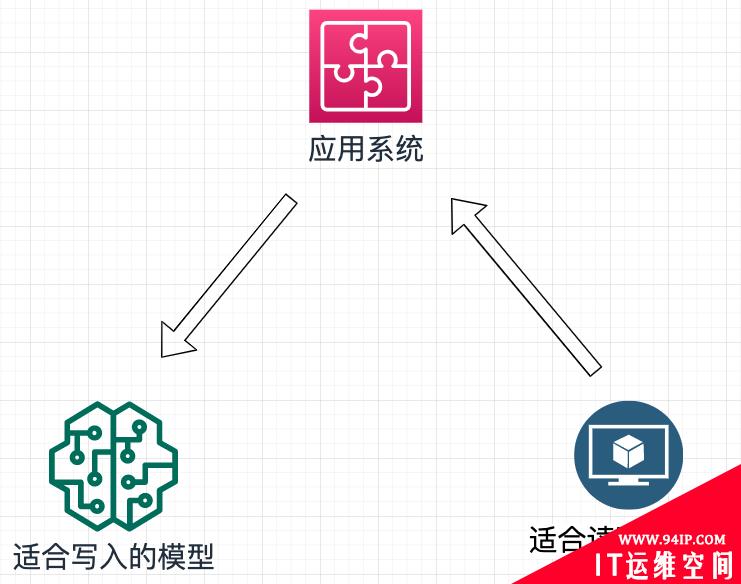
比如,写入数据由于不需要考虑读取,那我大可以使用 Json 格式,使用 XML 格式之类的非标准格式,甚至直接写个日志都可以。而读取数据则根本不需要考虑写入的问题,我甚至可以弄成一个容易搜索的索引格式来。
而 CQRS 在我看来,正是解决卡死我的性能问题的灵丹妙药。
以广告排行这个问题为例,广告排行麻烦就麻烦在,每次加载排行榜需要有很复杂的查询,去数据库中读取数据。
如果能彻底地把排行榜的读取和排行榜依赖的那些点击、消费指标的更新分开,那我苦恼的排行榜性能问题就能迎刃而解。
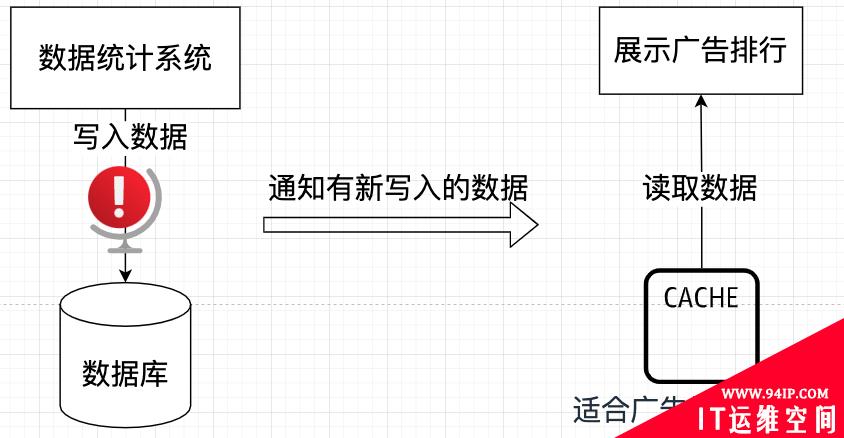
我费劲心思后,仿照 CQRS 的原版思想搞了一个这样的设计思路:
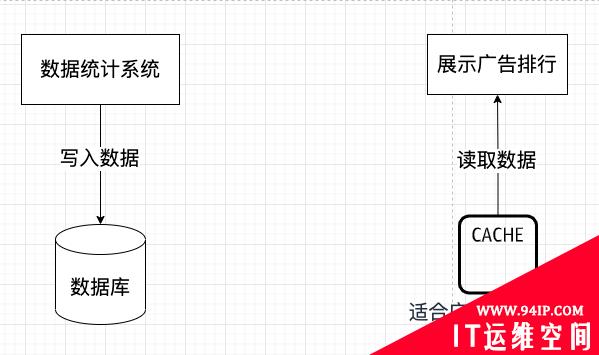
这里,数据统计就是广告排名需要的点击、消费等数据。这些数据会被放到一个单独的数据库中,这个数据库只用来写入,不考虑读。
然后,展示广告排行的功能本身又会单独从缓存中把广告排行的模型直接读取出来展示出去,而不用专门再做什么转换了。也不存在什么复杂查询的问题。
但是,我们的需求是要准实时的让广告排行根据点击、消费等数据自动更新,那么如果写入数据和读取数据模型分开了,该怎么办呢?
多年以前,当我第一次在网上买东西的时候,心里有个疑问:我下了个订单,卖我东西的商家是怎么知道的?莫非要一直盯着?
这个问题到我亲自开发电商系统的时候才知道,当我们下单的时候,需要发一个通知给对应的商家,告诉商家哪个客户购买了哪个商品。
所以,广告排行自动更新的解决方案有了,和电商下单通知商家的道理一样。当有数据写入的时候,我们把写入的数据复制一份通知给读取数据的模型就可以了。
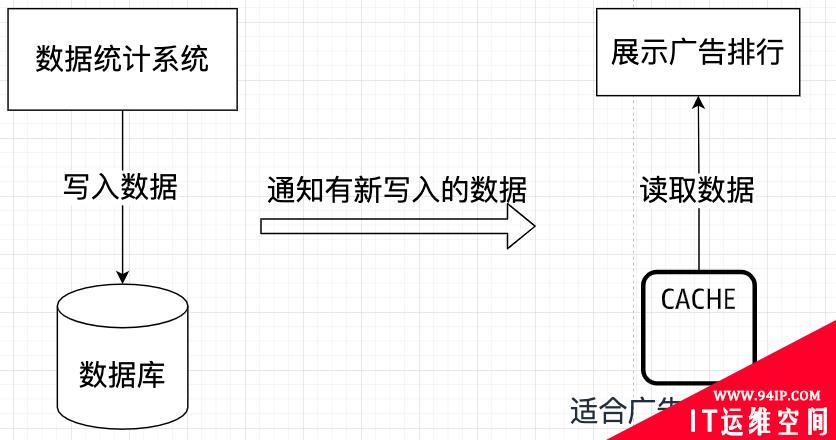
好,现在整套逻辑完整了。
但是,我并没有急于马上把 CQRS 这套模式去应用到实际的项目当中。因为,我发现我竟然不知道 CQRS 这套模式的缺点是什么。
要知道,世界上还不存在完美的解决方案,全都是既有优点又有缺点的。而 CQRS 我竟然觉得很完美的解决了我的问题,这说明我对这套模式的认知还存在问题。
当时,离约定的上线时间已经越来越近了,差不多还剩一周时间。我真的很想闭眼把方案实施下去。
但是,不行,我这个人做事向来喜欢把事情想得通透,把事物认知的十分清楚后再去做。
我决定冒险花两天去实现两个功能点,然后亲自体验一下引入 CQRS 的得与失。
两天后,我终于发现了问题:引入 CQRS 的模式后,最大的问题在于引入了过度的复杂性。
由于需要读和写分开,那么我们开发的工作量无形中被加大了一倍。又引入 CQRS,这变得更复杂了。
因为我们发现,不同的功能,只有使用不同的读取或者写入模型才能充分用上 CQRS 的优点。
比如,广告排行可能使用了缓存中间件去存取现成的排名。根据关键字搜索各种合适的广告,可能就得考虑开源的搜索引擎中间件。每引入一种都会增加开发成本、服务器成本,以及更多的复杂度。
最终,我们的广告系统按时上线了。
只不过,并没有广泛的采用 CQRS 模式,我只是把最重要的功能点用上了 CQRS,其余的有关性能的问题,我决定暂时放下。
之所以这样,是因为我觉得大部分的问题,其实是我们过度设计引发的。即使因此我失败了,我也认了。
我并不想为自己亲手打造的系统埋下巨大的隐患,更不想给团队带来无谓的工作量,我不想卷成这样。
上线后,我是如此忐忑,尤其是在上线运营的头两个月。
我不知道自己的妥协是否会诱发巨大的问题,我也不知道自己的所作所为是不是真的是对的。
两个系统的竞争在上线两个月后就有结果了。
这么快的得到结果,恰恰就是因为我的对手广泛的使用了 CQRS 模式。
他从一开始设计的时候,就想着一鸣惊人,他的系统里引入了七八种中间件。把大量的功能拆分成了读写两部分,而这引发了巨大的灾难,过度的复杂性,导致整个系统难以控制。
其中最头痛的就是,由于引入 CQRS,他们必须通过消息的传递去沟通读写两套组件。
但是,当读取组件收到消息后,却发现写入失败了。导致用户看到了对应的数据后,过一段时间,却发现数据和以前看到的对不上了。
比如,点击次数,开始看到的是 1000 次,结果两个小时后,发现变成了 999 次了。
这类问题每天都在出现,而他们因为系统太复杂了,查问题、定位问题、解决问题的时间被大大拉长。最后,客户们纷纷不干了,公司只好把客户转到了我这边的平台上。
竞争结束了,我胜利了,可是我真的无法高兴地起来。因为今天他因为错误的引入新技术失败了,那明天我又何尝不会因为误用新技术新思想而失败呢?今日的他又何尝不是明日的我?
愿天下程序员凡事深思熟悉,谨言慎行!
转载请注明:IT运维空间 » 运维技术 » 读写分离水太深,你把握不住,让叔来——命令查询权责分离模式
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/5.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值











发表评论