


LSM tree (log-structured merge-tree) 是一种对频繁写操作非常友好的数据结构,同时兼顾了查询效率。LSM tree 是许多 key-value 型或日志型数据库所依赖的核心数据结构,例如 BigTable、HBase、Cassandra、LevelDB、SQLite、Scylla、RocksDB 等。
LSM tree 之所以有效是基于以下事实:磁盘或内存的连续读写性能远高于随机读写性能,有时候这种差距可以达到三个数量级之高。这种现象不仅对传统的机械硬盘成立,对 SSD 硬盘也同样成立。如下图:

LSM tree 在工作过程中尽可能避免随机读写,充分发挥了磁盘连续读写的性能优势。
SSTable
LSM tree 持久化到硬盘上之后的结构称为 Sorted Strings Table (SSTable)。顾名思义,SSTable 保存了排序后的数据(实际上是按照 key 排序的 key-value 对)。每个 SSTable 可以包含多个存储数据的文件,称为 segment,每个 segment 内部都是有序的,但不同 segment 之间没有顺序关系。一个 segment 一旦生成便不再修改(immutable)。一个 SSTable 的示例如下:
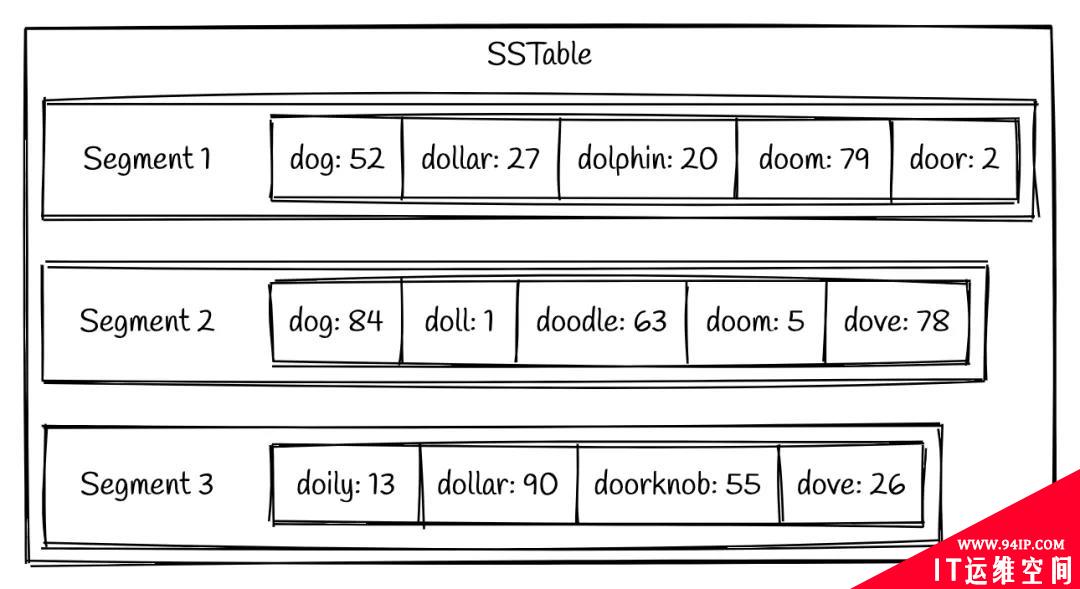
可以看到,每个 segment 内部的数据都是按照 key 排序的。下面我们来介绍每个 segment 是如何生成的。
写入数据
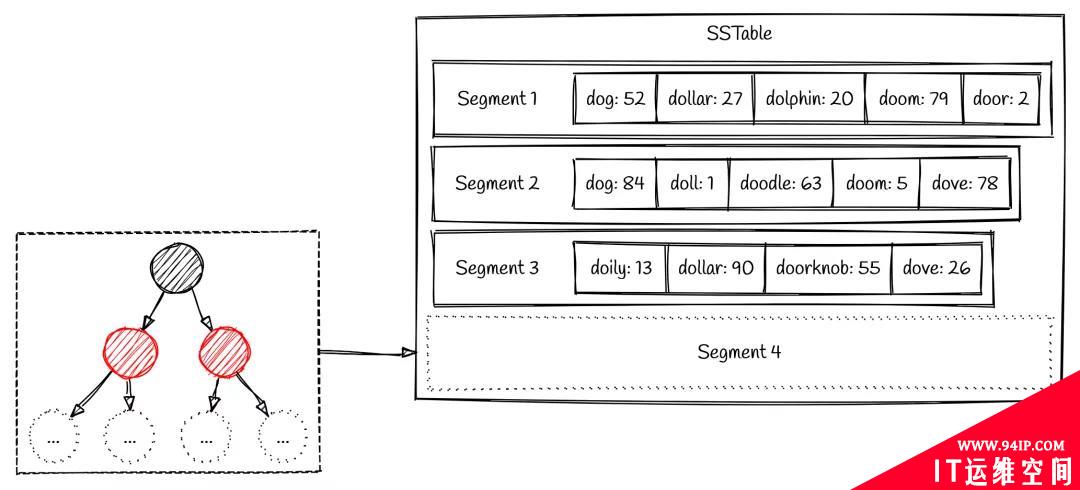
LSM tree 的所有写操作均为连续写,因此效率非常高。但由于外部数据是无序到来的,如果无脑连续写入到 segment,显然是不能保证顺序的。对此,LSM tree 会在内存中构造一个有序数据结构(称为 memtable),例如红黑树。每条新到达的数据都插入到该红黑树中,从而始终保持数据有序。当写入的数据量达到一定阈值时,将触发红黑树的 flush 操作,把所有排好序的数据一次性写入到硬盘中(该过程为连续写),生成一个新的 segment。而之后红黑树便从零开始下一轮积攒数据的过程。
读取/查询数据
如何从 SSTable 中查询一条特定的数据呢?一个最简单直接的办法是扫描所有的 segment,直到找到所查询的 key 为止。通常应该从最新的 segment 扫描,依次到最老的 segment,这是因为越是最近的数据越可能被用户查询,把最近的数据优先扫描能够提高平均查询速度。
当扫描某个特定的 segment 时,由于该 segment 内部的数据是有序的,因此可以使用二分查找的方式,在O(logn)的时间内得到查询结果。但对于二分查找来说,要么一次性把数据全部读入内存,要么在每次二分时都消耗一次磁盘 IO,当 segment 非常大时(这种情况在大数据场景下司空见惯),这两种情况的代价都非常高。一个简单的优化策略是,在内存中维护一个稀疏索引(sparse index),其结构如下图:
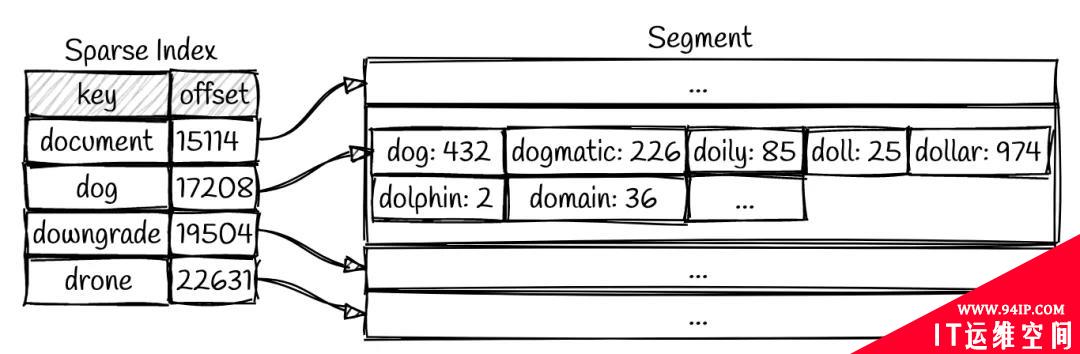
稀疏索引是指将有序数据切分成(固定大小的)块,仅对各个块开头的一条数据做索引。与之相对的是全量索引(dense index),即对全部数据编制索引,其中的任意一条数据发生增删均需要更新索引。两者相比,全量索引的查询效率更高,达到了理论极限值O(logn),但写入和删除效率更低,因为每次数据增删时均需要因为更新索引而消耗一次 IO 操作。通常的关系型数据库,例如 MySQL 等,其内部采用 B tree 作为索引结构,这便是一种全量索引。
有了稀疏索引之后,可以先在索引表中使用二分查找快速定位某个 key 位于哪一小块数据中,然后仅从磁盘中读取这一块数据即可获得最终查询结果,此时加载的数据量仅仅是整个 segment 的一小部分,因此 IO 代价较小。以上图为例,假设我们要查询 dollar 所对应的 value。首先在稀疏索引表中进行二分查找,定位到 dollar 应该位于 dog 和 downgrade 之间,对应的 offset 为 17208~19504。之后去磁盘中读取该范围内的全部数据,然后再次进行二分查找即可找到结果,或确定结果不存在。
稀疏索引极大地提高了查询性能,然而有一种极端情况却会造成查询性能骤降:当要查询的结果在 SSTable 中不存在时,我们将不得不依次扫描完所有的 segment,这是最差的一种情况。有一种称为**布隆过滤器(bloom filter)**的数据结构天然适合解决该问题。布隆过滤器是一种空间效率极高的算法,能够快速地检测一条数据是否在数据集中存在。我们只需要在写入每条数据之前先在布隆过滤器中登记一下,在查询时即可断定某条数据是否缺失。
布隆过滤器的内部依赖于哈希算法,当检测某一条数据是否见过时,有一定概率出现假阳性(False Positive),但一定不会出现假阴性(False Negative)。也就是说,当布隆过滤器认为一条数据出现过,那么该条数据很可能出现过;但如果布隆过滤器认为一条数据没出现过,那么该条数据一定没出现过。这种特性刚好与此处的需求相契合,即检验某条数据是否缺失。
文件合并(Compaction)
随着数据的不断积累,SSTable 将会产生越来越多的 segment,导致查询时扫描文件的 IO 次数增多,效率降低,因此需要有一种机制来控制 segment 的数量。对此,LSM tree 会定期执行文件合并(compaction)操作,将多个 segment 合并成一个较大的 segment,随后将旧的 segment 清理掉。由于每个 segment 内部的数据都是有序的,合并过程类似于归并排序,效率很高,只需要O(n)的时间复杂度。
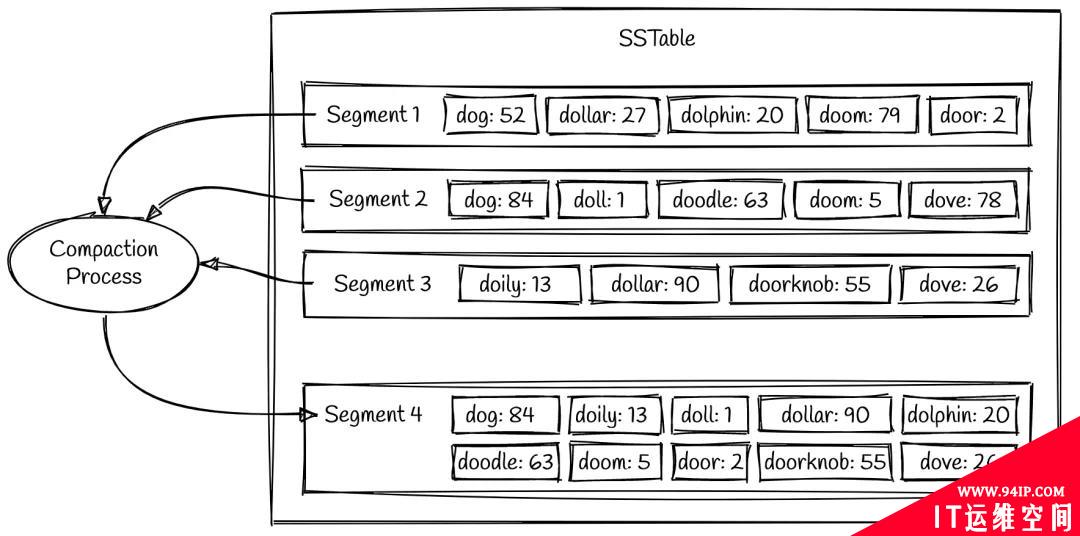
在上图的示例中,segment 1 和 2 中都存在 key 为 dog 的数据,这时应该以最新的 segment 为准,因此合并后的值取 84 而不是 52,这实现了类似于字典/HashMap 中“覆盖写”的语义。
删除数据
现在你已经了解了 LSM tree 读写数据的方式,那么如何删除数据呢?如果是在内存中,删除某块数据通常是将它的引用指向 NULL,那么这块内存就会被回收。但现在的情况是,数据已经存储在硬盘中,要从一个 segment 文件中间抹除一段数据必须要覆写其之后的所有内容,这个成本非常高。LSM tree 所采用的做法是设计一个特殊的标志位,称为 tombstone(墓碑),删除一条数据就是把它的 value 置为墓碑,如下图所示:
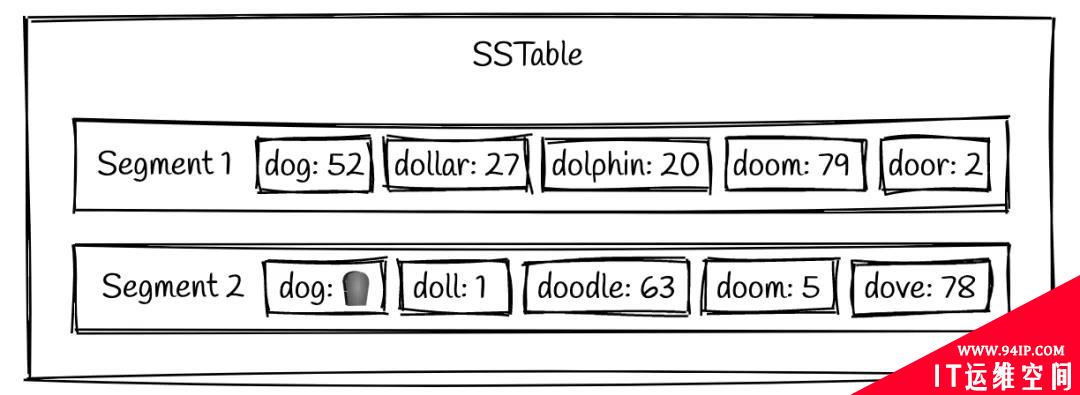
这个例子展示了删除 segment 2 中的 dog 之后的效果。注意,此时 segment 1 中仍然保留着 dog 的旧数据,如果我们查询 dog,那么应该返回空,而不是 52。因此,删除操作的本质是覆盖写,而不是清除一条数据,这一点初看起来不太符合常识。墓碑会在 compact 操作中被清理掉,于是置为墓碑的数据在新的 segment 中将不复存在。
LSM tree 与 B tree 的对比
主流的关系型数据库均以 B/B+ tree 作为其构建索引的数据结构,这是因为 B tree 提供了理论上最高的查询效率 O(log n)。但对查询性能的追求也造成了 B tree 的相应缺点,即每次插入或删除一条数据时,均需要更新索引,从而造成一次磁盘 IO。这种特性决定了 B tree 只适用于频繁读、较少写的场景。如果在频繁写的场景下,将造成大量的磁盘 IO,从而导致性能骤降。这种应用场景在传统的关系型数据库中比较常见。
而 LSM tree 则避免了频繁写场景下的磁盘 IO 开销,尽管其查询效率无法达到理想的 O(log n),但依然非常快,可以接受。所以从本质上来说,LSM tree 相当于牺牲了一部分查询性能,换取了可观的写入性能。这对于 key-value 型或日志型数据库是非常重要的。
总结
LSM tree 存储引擎的工作原理包含以下几个要点:
写数据时,首先将数据缓存到内存中的一个有序树结构中(称为 memtable)。同时触发相关结构的更新,例如布隆过滤器、稀疏索引。
当 memtable 积累到足够大时,会一次性写入磁盘中,生成一个内部有序的 segment 文件。该过程为连续写,因此效率极高。
进行查询时,首先检查布隆过滤器。如果布隆过滤器报告数据不存在,则直接返回不存在。否则,按照从新到老的顺序依次查询每个 segment。
在查询每个 segment 时,首先使用二分搜索检索对应的稀疏索引,找到数据所在的 offset 范围。然后读取磁盘上该范围内的数据,再次进行二分查找并获得结果。
对于大量的 segment 文件,定期在后台执行 compaction 操作,将多个文件合并为更大的文件,以保证查询效率不衰减。
转载请注明:IT运维空间 » 运维技术 » 一篇关于Lsm核心实现的讲解
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/4.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值














发表评论