


一、 Doris 简介
什么是Doris
Apache Doris是一个现代化的MPP(大规模并行处理)分析型数据库产品。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Apache Doris的分布式架构非常简洁,易于运维,并且可以支持10PB以上的超大数据集。Apache Doris可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。
Doris 由百度大数据部研发 ( 百度 Palo),在百度内部,有超过200个产品线在使用,部署机器超过1000台,单一业务最大可达到上百 TB。百度将 Doris 贡献给 Apache 社区之后,许多外部用户也成为了 Doris 的使用者,例如新浪微博,美团,小米等著名企业。
关键字:MPP,分布式,数据分析,PB级
优点
兼容MySQL协议。
聚合表技术+预聚合技术。
动态水平拓展和自动负载均衡。
缺点
网络上相关经验少。
二、 Doris定位
在数据分析处理框架中,Doris 主要做的是 Online 层面的数据服务,主要处理的是数据分析方面的服务。
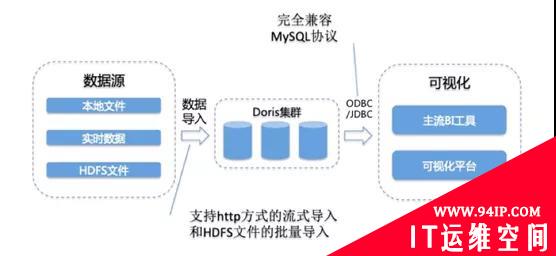
Doris适用场景有以下:
1、报表
报表类数据分析,数据分析以及查询的模式相对比较固定,而且后台 SQL 的模式往往都是确定的。针对此类应用场景,选择使用 MySQL 存结果数据,用户可从界面选择执行批处理以及发送邮件。在 Doris 平台中,报表类查询时延一般在秒级以下。
2、多维分析
这里提到的多维分析,同样要求数据是结构化的,适用于查询相对灵活的场景,例如数据分析条件以及聚合维度等方面不是很确定,一般将此类数据分析定义为多维分析。相对于报表类分析,多维分析的查询时延会稍慢,大约在会在 10s 的级别。
三、 Doris 架构
Doris 架构图如下:
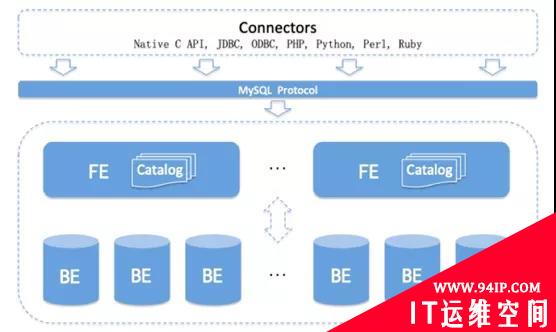
Doris 的整体架构和 TiDB 类似,借助 MySQL 协议,用户使用任意 MySQL 的 ODBC/JDBC以及MySQL 的客户端,都可以直接访问 Doris。Doris 中的模块包括 FE 和 BE 两类:FE 主要负责元数据的管理、存储,以及查询的解析等;一个用户请求经过 FE 解析、规划后,具体的执行计划会发送给 BE,BE 则会完成查询的具体执行。BE 节点主要负责数据的存储、以及查询计划的执行。目前平台的 FE 部分主要使用 Java,BE 部分主要使用 C++。
四、 Doris 数据结构
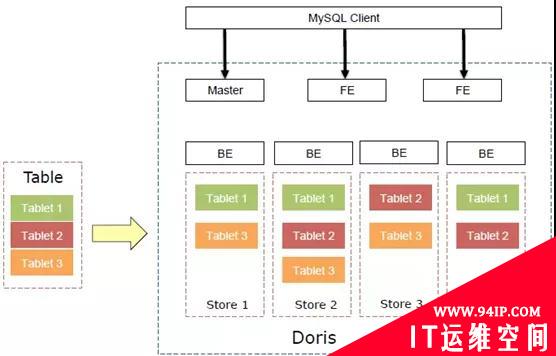
如果从表的角度来看数据结构,用户的一张 Table 会拆成多个 Tablet,Tablet 会存成多副本,存储在不同的 BE 中,从而保证数据的高可用和高可靠。
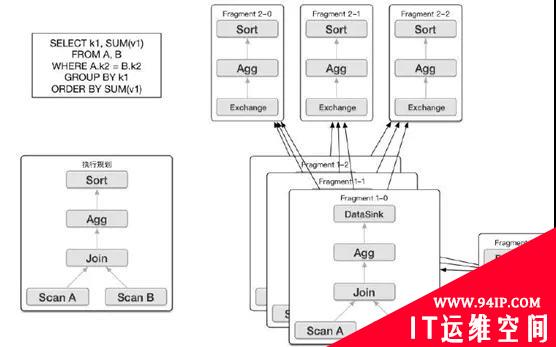
五、 MPP(Massively Parallel Processing)
MPP 将SQL拆分成多份,分布到每台机器执行,最后再将结果汇总。假如有10台机器,在大数据量下,这种查询执行方式可以使得查询性能达到10倍的提升。
六、 表设计
列式存储
Doris的表和关系型数据相同,由行和列构成。每行数据对应用户一条记录,每列数据有相同数据类型。所有数据的列数相同,可以动态增删列。Doris中,张表的列可以分为维度列(也成为key列)和指标列(value列),维度列用于分组和排序,指标列可通过聚合函数SUM,COUNT,MIM,MAX,REPLACE,HLL_UNION,BITMAP_UNION等累加起来。因此,DorisDB的表也可以认为是多维的key到多维指标的映射。
稀疏索引
Doris对数据进行有序存储,在数据有序的基础上为其建立稀疏索引,索引粒度为block(1024行)。这其中有一个特殊的地方,就是 varchar 类型的字段。varchar 类型字段只能作为稀疏索引的最后一个字段。索引会在 varchar 处截断,因此 varchar 如果出现在前面,可能索引的长度可能不足 36 个字节。具体可以参阅 数据模型、ROLLUP 及前缀索引。
除稀疏索引之外,Doris还提供bloomfilter索引,bloomfilter索引对区分度比较大的列过滤效果明显。如果考虑到varchar不能放在稀疏索引中,可以建立bloomfilter索引。
七、 数据模型
明细模型
Doris建表的默认模型是明细模型。
一般用明细模型来处理的场景有如下特点:
1. 需要保留原始的数据(例如原始日志,原始操作记录等)来进行分析;
2. 查询方式灵活,不局限于预先定义的分析式,传统的预聚合方式难以命中;
3. 数据更新不频繁。导入数据的来源一般为日志数据或者是时序数据,以追加写为主要特点,数据产生后就不会发生太多变化。
聚合模型
适合采用聚合模型来分析的场景具有如下特点:
1. 业务方进行的查询为汇总类查询,比如sum、count、 max等类型的查询;
2. 不需要召回原始的明细数据;
3. 老数据不会被频繁更新,只会追加新数据。
Doris会将指标列按照相同维度列进行聚合。当多条数据具有相同的维度时,Doris会把指标进行聚合。从而能够减少查询时所需要的处理的数据量,进而提升查询的效率。
更新模型
适合采用更新模型来分析的场景具有如下特点:
1. 已经写入的数据有存量的更新需求;
2. 需要进行实时数据分析。
更新模型中,排序键满足唯一性约束,成为主键。
Doris存储内部会给每一个批次导入数据分配一个版本号,同一主键的数据可能有多个版本,查询时,最大(最新)版本的数据胜出。
八、 物化视图
物化视图是提取某些维度的组合建立对用户透明的却有真实数据的视图表格。Doris 的物化视图可以保证用户在更新时,直接更新原始表,Doris 会保证原表、物化视图原子生效。在查询的时候用户也只需指定原始表,Doris 会根据查询的具体条件,选择适合的物化视图完成查询。
通常用户可以通过物化视图功能完成以下两种功能。
1、更换索引列进行重排列。
2、针对指定列做聚合查询。
转载请注明:IT运维空间 » 运维技术 » 这么火的数仓确定不学习一下?
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值











发表评论