

 大家好,我是年年!提起CORS,大部分的文章都在写什么是简单请求、什么是复杂请求,复杂请求预检的流程又是怎样。
但如果问你:
大家好,我是年年!提起CORS,大部分的文章都在写什么是简单请求、什么是复杂请求,复杂请求预检的流程又是怎样。
但如果问你:
这篇文章会围绕CORS是如何保障安全的的,讲清这几个问题。读完可以对CORS知其然,并知其所以然。
什么是CORS
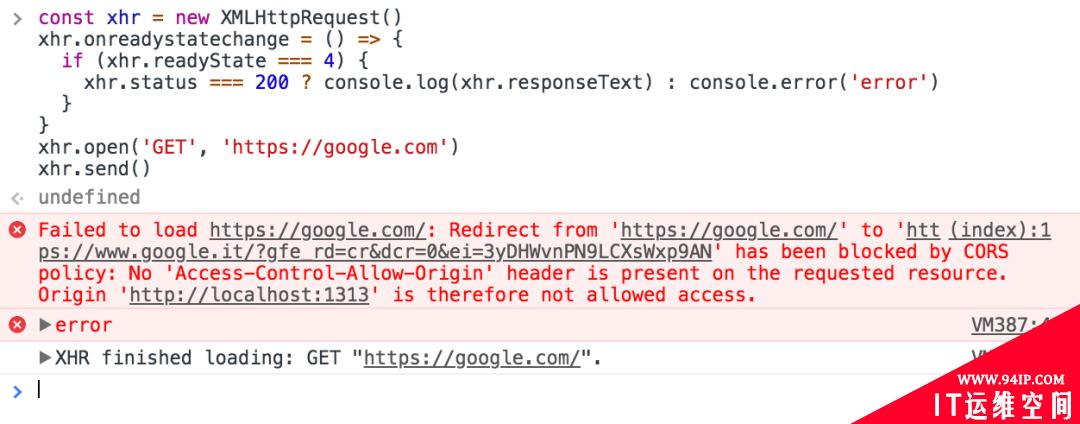
相信每个前端的控制台都中都被打印过这样一段话,告诉你:你的跨域请求策略拦截啦!
 首先要明确的一点,CORS的目的不是拦截请求,反倒是为了让其能正常请求。
首先要明确的一点,CORS的目的不是拦截请求,反倒是为了让其能正常请求。
CORS诞生的背景是「同源策略」。这是一个相当严苛的规定,它禁止了跨域的AJAX请求。但实际的开发中又有这样的需求,于是开一个口子——只要配置了CORS的对应规则,跨域请求就能正常进行。这也正和CORS的名字对应起来了——「跨域资源共享」,就是为了能让跨域请求在「同源策略」的大背景下进行。 回到上面提到控制台报错,这不是阻止你做跨域请求,而是提示你:因为没有按照CORS要求做配置,不得不暂时拦截。
怎样配置CORS
上文讲清了,只要按照CORS要求做配置,就能突破同源策略的限制,下面将会讲述如何配置。 这部分不需要前端操心,完全后端来做:在响应头里面加一个字段Access-Control-Allow-Origin(允许请求的来源),这个值要把前端的源包含进去。 举个例子:请求的后端接口是http://fe_nian,你本地正在开发前端工程跑在8080端口。那么后端会在响应头里加上Access-Control-Allow-Origin:*来允许http://localhost:8080这个源去做跨域请求,因为*是所有的意思。
跨域请求的流程
CORS把请求分成简单请求和复杂请求,划分的依据是“是否会产生副作用”。 简单贴一下定义,同时满足下面这两个条件的是简单请求
请求方法是HEAD/GET/POST。 请求体的文件类型只能是form-urlencoded、form-data、text/plain(这类文章很多,不再赘述,可以看阮一峰-跨域资源共享)。对于简单请求,流程如下:

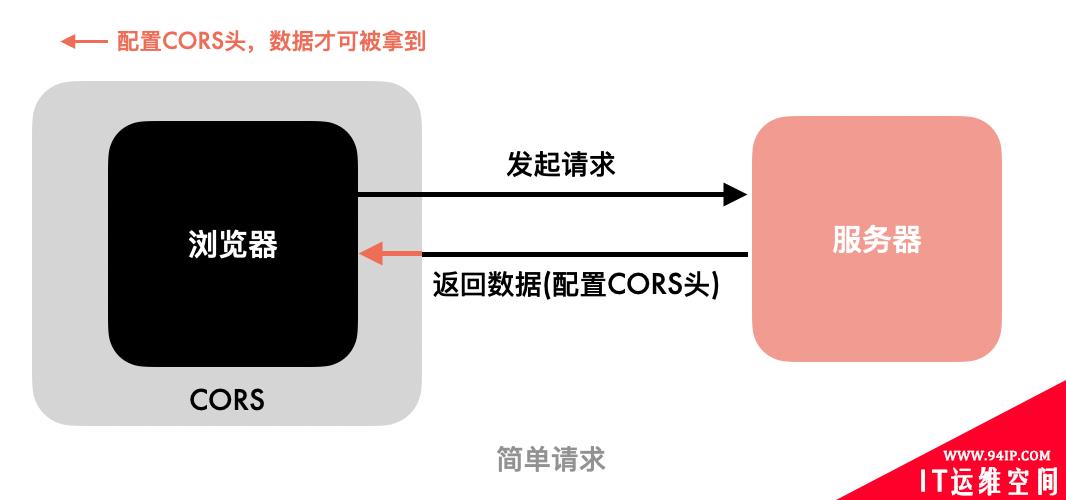
这里需要注意,浏览器是拦截响应,而不是拦截请求,跨域请求是发出去的,并且服务端做了响应,只是浏览器拦截了下来。
对于复杂请求,整个流程如下:
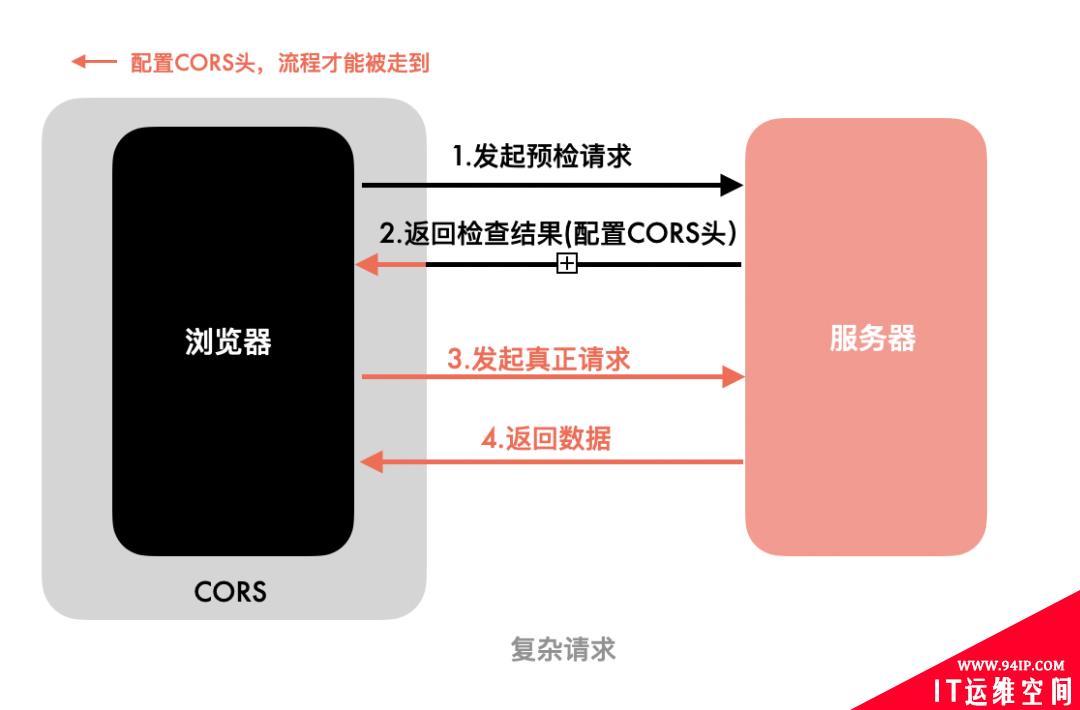
浏览器会检查第2步中拿到的CORS头,如果没有包含当前的源,后续的第3、4步都不会进行,也就是不会发起真正请求。
为什么要带上源
CORS给开发带来了便利,同时也带来了安全隐患——CSRF攻击。
它的基本流程如下:
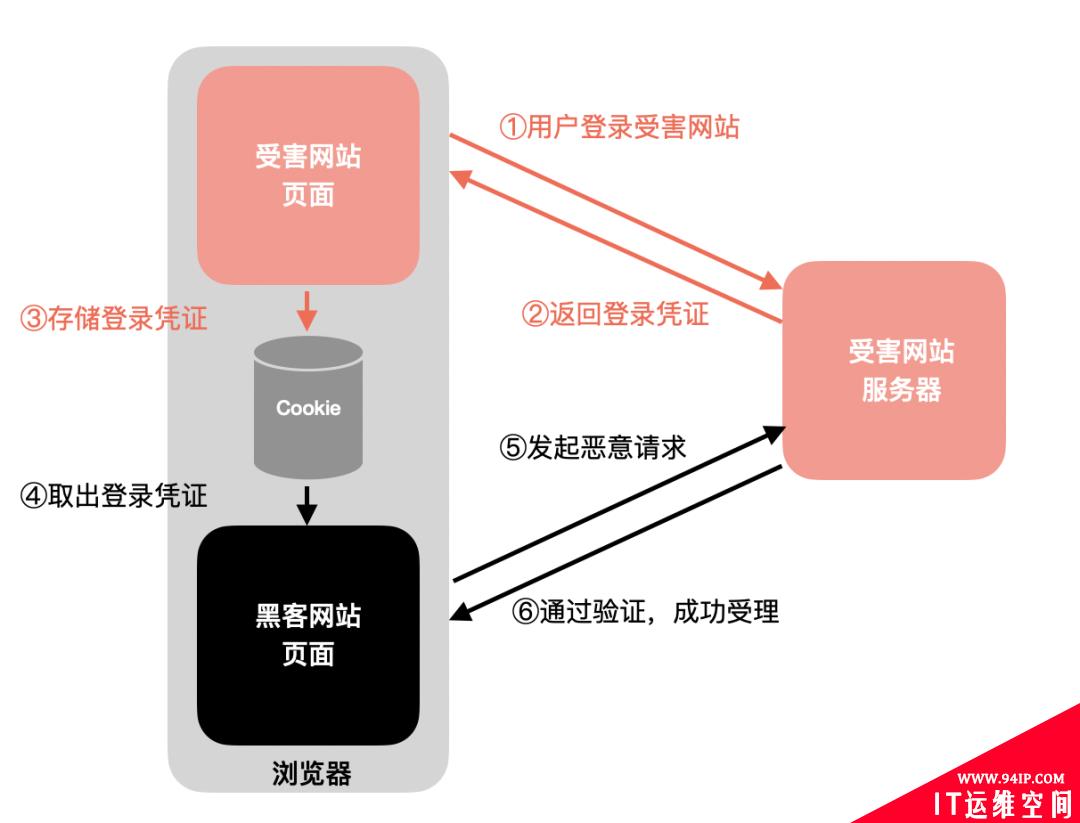
如果严格按照同源政策,第2步的跨域请求不能进行的,也就不会造成危害。所以CORS策略的心智模型是:所有跨域请求都是不安全的,浏览器要带上来源给服务器检验。 如果做过服务端开发,应该知道,服务端不存在跨域一说,去获取另一个服务器的资源是再顺畅不过的事情。因为服务端不像浏览器一样,作为“容器”存贮着用户身份凭证——也就是上面的第1步发生的事情,它去做跨域请求没有这样的风险。
为什么只对复杂请求做预检
上文提到,划分简单请求和复杂请求的依据是“是否产生副作用”。这里的副作用指对数据库做出修改:使用GET请求获取新闻列表,数据库中的记录不会做出改变,而使用PUT请求去修改一条记录,数据库中的记录就发生了改变。 对于简单请求,浏览器只会在请求头加上一个origin字段标识请求来源;对于非简单请求,浏览器会先发出一个预检请求,获得肯定回答后才会发送真正的请求,下面会讲清楚为什么这么做。 可以假设网站被CSRF攻击了——黑客网站向银行的服务器发起跨域请求,并且这个银行的安全意识很弱,只要有登录凭证cookie就可以成功响应: 黑客网站发起一个GET请求,目的是查看受害用户本月的账单。银行的服务器会返回正确的数据,不过影响并不大,而且由于浏览器的拦截,最后黑客也没有拿到这份数据; 黑客网站发起一个PUT请求,目的是把受害用户的账户余额清零。浏览器会首先做一次预检,发现收到的响应并没有带上CORS响应头,于是真正的PUT请求不会发出; 幸好有预检机制,否则PUT请求一旦发出,黑客的攻击就成功了。
结语
回到开头的两个问题,不难得出答案:
对于跨域请求带上请求来源,是为了防止CSRF攻击;浏览器的心智模型是:跨域请求都是不安全的,CORS的机制是为了保障请求目的服务器的安全。 依据是否对服务器有副作用,划分了简单请求和复杂请求(但由于历史原因,表单POST请求也被划分成了简单请求),预检机制会把不安全的复杂请求拦截下来,避免对服务器造成危害,而简单请求通常不会对服务器的资源作出修改,即使发出危害不大。
转载请注明:IT运维空间 » 安全防护 » CORS为什么能保障安全?为什么只对复杂请求做预检?
你可能喜欢:
-

解决MySql版本问题sql_mode=only_full_group_by
-

Python操作mysql数据库出现pymysql.err.ProgrammingError: (1064, “You have an error in your SQL syntax; check
-

Oracle PL/SQL如何动态调用存储过程 收藏
-

Mysql 不存在则插入,存在则更新 mysql 存在该记录则更新,不存在则插入记录的sql
-
MySQL与Oracle之间互相拷贝数据的Java程序
-

MySQL导入sql文件的三种方法小结
-

MS sql server和mysql中update多条数据的例子
-
mysql防SQL注入搜集
-
Oracle:SQL语句–给用户赋权限
-

如何在MySql中记录SQL日志(例如Sql Server Profiler)








发表评论