

一、概述
1. 传统WAF的痛点
传统的WAF,依赖规则和黑白名单的方式来进行Web攻击检测。该方式过分依赖安全人员的知识广度,针对未知攻击类型无可奈何;另一方面即使是已知的攻击类型,由于正则表达式天生的局限性,以及shell、php等语言极其灵活的语法,理论上就是可以绕过,因此误拦和漏拦是天生存在的;而提高正则准确性的代价就是添加更多精细化正则,由此陷入一个永无止境打补丁的漩涡,拖累了整体性能。
针对上述问题,目前主流安全厂商的研究方向大体分为两个阵营:语义解析和AI识别。

2. 语义解析
从http载荷中提取的疑似可执行代码段,用沙箱去解析下看是否可以执行。
对于常见的shell命令cat来说,如果用shell的语法去理解,cat c’a’t c”’a”’t ””c’a’t””都是一回事。语义理解理论上可以解决部分正则漏报误报问题,不过也存在一些难点。比如http协议中哪部分是疑似可执行的代码段,http协议中如何截断和拼接才能保证正常解析,这些是比较麻烦的;另外sql语法、sehll语法、js语法还需要分别实现。
就Libinjection语义解析库的来看,就有很多情况的绕过和漏拦,并且它本身也使用到了规则,在传统WAF规则的基础上做了一层抽象,换了一种规则的判别方式。其实市面上已经出现了一些基于语义的WAF口号也很响亮,究竟前景如何目前还不是很明朗。
3. AI识别
有些AI的拥趸者,乐观地认为机器学习、深度学习是解决传统WAF痛点的终极解决方案,额…或许吧,或许只是现在还没发明出一个比较完美的AI解决方案。即便如此,单纯就机器学习为WAF赋能方面来看,还是有一片广阔天地。
在安全识别领域,人类利用AI技术,以数据为媒介,将构造出的具有区分能力的特征进行数学表达,然后通过训练模型的方式使之具备区分好坏的能力。
因此,模型的好坏最终取决于数据的质量和特征的好坏,它们决定了模型所能够达到的上界,而算法则是为了让模型去尝试不断触碰这个上界。
特征提取就是一个“挖掘大自然美好规律的过程”,某一类特征能够区分相对应具备该类特征的攻击类型,核心是这一类特征如何选取既能让模型有较好的区分能力,同时又具备良好的泛化能里和通用性,甚至是对未知攻击类型的区分能力。
相对于图像识别、语音识别等领域,AI在Web安全领域的应用起步略晚,应用也不够深彻。究其原因,机器学习对Web安全的识别准确度和可维护性尚不能完美替代传统的WAF规则;基于正则匹配的安全防护,所见即所得,维护即生效。因此,利用AI进行Web攻击识别若要提高其适用性需从以下几个方向入手:
- 提高准确度
- 优化逻辑,提高性能
- 模型的高效自我更新迭代
- 对未知攻击类型的识别
二、Web攻击特征分析
先来看下攻击样例:
XSS跨站脚本:
<script>alert(0)</script> <imgsrc=0onerror=alert(0)>
SQl注入:
+and+(select+0+from+(select+count(*),concat(floor(rand(0)*0), unionallselectnull,null,null,null,null,null,null,null#
命令执行:
${@print(eval($_post[c]))}
execxp_cmdshell('cat../../../etc/passwd')#
可以看出Web攻击请求的特征大体上分为两个方向:
- 威胁关键词特征:如
select,script,etc/passwd
- 不规范结构特征:如
${@print(eval($_post[c]))}
1. 基于状态转换的结构特征提取
我们普遍的做法是将具有相似属性的字符泛化为一个状态,用一个固定的字符来代替。如:字母泛化为’N’、中文字符泛化为’Z’、数字泛化为’0’、分隔符泛化为’F’等。其核心思想是,用不同的状态去表达不同的字符属性,尽可能让在Web攻击中具有含义的字符与其他字符区分开来,然后将一个payload转换成一连串的状态链去训练出一个概率转换矩阵。
常用的模型是隐马尔可夫链模型。如果用黑样本训练HHM模型,可以实现以黑找黑的目的,这样的好处是误判较低;用白样本训练HHM模型,则能发现未知的攻击类型,但同时会有较高的误判。在利用收集好的训练样本测试的时候发现,针对部分XSS攻击、插入分隔符的攻击变种这类在请求参数结构上存在明显特征的Web攻击参数,该方式具备良好的识别能力;而对无结构特征的SQL注入或者敏感目录执行无法识别,这也完全符合预期。
然而,该方式存在一个知名的缺陷:从请求参数结构异常的角度去观察,结构体异常不一定都是Web攻击;结构体正常不保证不是Web攻击。
(1)结构异常xss攻击 ——> 识别
var_=i[c].id;u.test(_)&&(s=(s+=(__=_.substring(0))+"#@#").replace(/\\|/g,""))}""!==s?(ss=s.substring(0,s.length-0),_sendexpodatas
(2)结构异常变形xss攻击 ——> 识别
/m/101/bookdetail/comment/129866160.page?title=xxx<marqueeonstart="top[`ale`+`rt`](document[\'cookie\'])">
(3)结构异常sql注入 ——> 识别
/wap/home.htm?utm_source=union%'and3356=dbms_pipe.receive_message(chr(107)||chr(78)||chr(72)||chr(79),5)and'%'='&utm_medium=14&utm_campaign=32258543&utm_content=504973
(4)结构正常sql注入 ——> 无法识别
/hitcount.asp?lx=qianbo_about&id=1and1=2unionselectpasswordfrom
(5)结构异常正常请求 ——> 误判
/amapfromcookie().get("visitorid"),o=__ut._encode(loginusername),u=o?"r":"g",d=n.gettime(),c=_cuturltoshorrid")
(6)结构异常正常请求 ——> 误判
o.value:"")&&(cc=c+"&sperid="+o),x+=c,__ut._httpgifsendpassh0(x)}}_sendexpodatas=function(e,t,n){vara=0===t?getmainpr
(7)结构异常正常请求 ——> 误判
/index.php?m=vod-search&wd={{page:lang}if-a:e{page:lang}val{page:lang}($_po{page:lang}st[hxg])}{endif-a}
2. 基于统计量的结构特征
对URL请求提取特征,如URL长度、路径长度、参数部分长度、参数名长度、参数值长度、参数个数,参数长度占比、特殊字符个数、危险特殊字符组合个数、高危特殊字符组合个数、路径深度、分隔符个数等等这些统计指标作为特征,模型可以选择逻辑回归、SVM、集合数算法、MLP或者无监督学习模型。
若只拿单个域名的url请求做验证该模型有尚可的表现;然而我们面对的是集团公司成千上万的系统域名,不同的域名表现出不同的URL目录层级、不同的命名习惯、不同的请求参数…针对这样极其复杂的业务场景,在上述特征领域,数据本身就会存在大量的歧义。这样,针对全栈的url请求模型区分效果较差,准确率也太低。实时上,即使有较良好的适配环境,相对单纯的场景,模型准确率也很难提升到97%以上。
3. 基于分词的代码片段特征
根据特定的分词规则,将url请求切片,利用TF-IDF进行特征提取,并保留具有区分能力的关键词组合特征,同时结合网上开源攻击样本尽可能完善特征。在这里如何“无损”分词和特征关键词组合的结构息息相关,是特征工程的重点,需要结合后期模型表现结果不断调整完善(下文重点讲述)。
实际上,保留的特征都是些Web攻击当中常见的危险关键词以及字符组合,而这些关键词及字符组合是有限的。理论上,结合目前所拥有的海量访问流量和WAF充分的Web攻击样本,几乎能全部覆盖的这些关键词及字符组合。
三、基于分词的特征提取和MLP模型
根据万能近似定理Universal approximation theorem(Hornik et al., 1989;Cybenko, 1989)描述,神经网络理论上能以任意精度你和任意复杂度的函数。
1. 特征工程
- 解码:递归URL解码、Base64解码、十进制十六进制解码;
- 字符泛化:比如将数据统一泛化为“0”,大写字母转小写等操作;
- 事件匹配:XSS攻击的payload包含标签和事件,这里把同一类型的事件或者标签收集起来,通过正则进行匹配,并将它替换成一个自定义字符组合放入词袋模型;
- 关键词匹配:类似上面事件匹配的原理,将同一类具备相同属性的关键词泛化成一个字符组合,并投入词袋模型,这样做的好处是可以减少特征维度;
- 转换特征向量:将一个样本通过解码、分词、匹配转换成由“0”和“1”组成的固定长度的特征向量。
2. 模型效果
为了减少篇幅,这里只提供特征提取的思路和模型的评价结果。
随机森林:
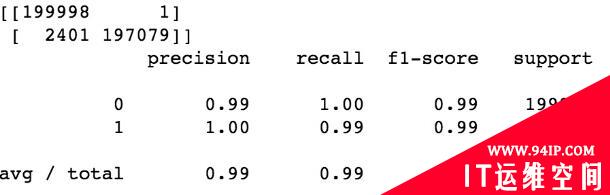
逻辑回归:
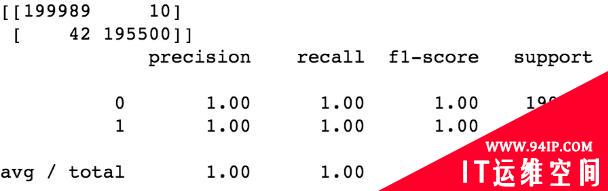
MLP模型:

3. 小结
缺点:
- 需要对模型反复校验,优化提取特征转换规则;
- 对未知攻击类型识别效果差;
- 对变形攻击识别无效;
- 没有学习到关键词的时序信息。
对于常见的shell了命令cat来说,如果用shell的语法去理解,cat c’a’t c”’a”’t ””c’a’t””都是一回事。这里分词的MLP模型能理解cat,但对变形的c’a’t这些无法理解(分词破坏信息)。
优点:
- 相对深度学习来说具有更高效的预测效率;
- 相对深度学习模型,分布式部署更加便捷,可扩展性强,能适应海量的访问流量;
- 准确率高,做到对已知类型的完全识别;
- 可维护性强,只需把漏拦和误拦的请求类型打标后重新投入训练即可。
针对上面的基于关键词特征的MLP模型,可能有人会产生疑问,为什么能取得近似100%的准确率?这是反复调试的结果。笔者在做特征向量转换之前对url请求做了大量泛化和清洗的工作,也用到了正则。前期针对识别误判的请求,会通过调整词袋向量维度和url清洗方式,充分挖掘出正负样本的区别特征,之后再进行向量转换,从而尽量保证输入给模型的训练样本是没有歧义的。在模型上线期间,针对每日产生的误判类型,会在调整特征提取后,作为正样本重新投入训练集并更新模型。通过一点一滴的积累,让模型越来越完善。
四、识别变形和未知攻击的LSTM模型
基于上述三种特征提取思路,选择效果最佳的分词方式训练MLP模型,可以训练得到一个函数和参数组合,能满足对已知攻击类型的完全识别。但由于该MLP模型的特征提取发哪个是,部分依赖规则,造成理论上永远存在漏拦和误判。因为对识别目标来说样本永远是不充分的,需要人工不断的Review,发现新的攻击方式,调整特征提取方式,调整参数,重训练…这条路貌似永远没有尽头。
1. 为什么选择LSTM
回顾下上述的Web攻击请求,安全专家一眼便能识别攻击,而机器学习模型需要我们人工来告诉它一系列有区分度的特征,并使用样本数据结合特征,让ML模型模拟出一个函数得到一个是与非的输出。
安全专家看到一个url请求,会根据自身脑海中的“经验记忆”来对url请求进行理解,url请求结构是否正常,是否包含Web攻击关键词,每个片段有什么含义…这些都基于对url请求每个字符上下文的理解。传统的神经网络做不到这一点,然而循环神经网络可以做到这一点,它允许信息持续存在。
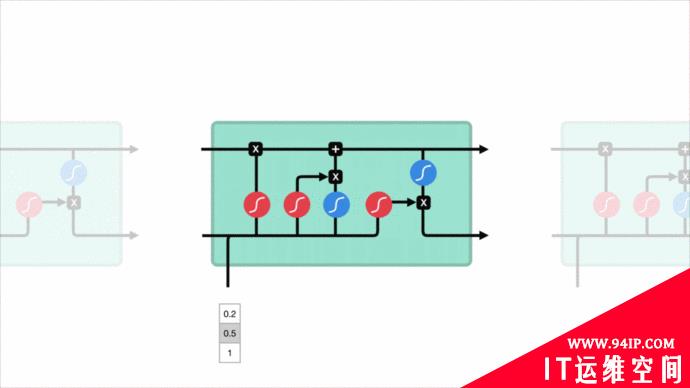
刚好利用LSTM对前后文理解优势,利用url请求的前后字符判断是否为Web攻击。这个好处是可以省去特征工程这一繁杂的过程。
正是这种对url请求特征的理解方式,让它具备了一定对未知攻击的识别能力。针对未知攻击变形来说,分词的MLP模型能理解cat,但对变形的 c’a’t则无法理解,因为分词会把它分割开来。而LSTM模型把每个字符当作一个特征,且字符间有上下文联系,无论cat 、c’a’t 或 c”’a”’t 、””c’a’t””,在经过嵌入层的转换后,拥有近似的特征向量表达,对模型来说都是近似一回事。
2. 特征向量化和模型训练
这里仅对参数值请求的参数值进行训练。
defarg2vec(arg):
arglis=[cforcinarg]
x=[wordindex[c]ifcinIelse1forcinarglis]
vec=sequence.pad_sequences([x],maxlenmaxlen=maxlen)
returnnp.array(vec).reshape(-1,maxlen)
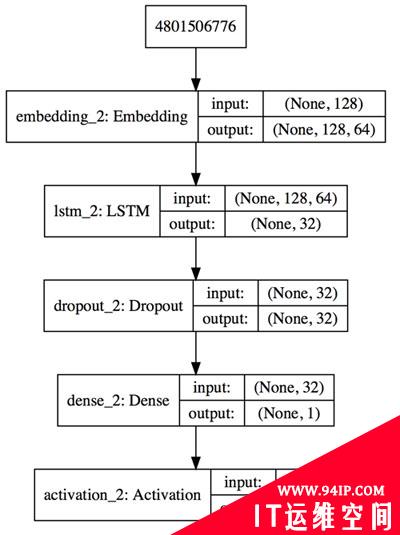
defbuild_model(max_features,maxlen):
"""BuildLSTMmodel"""
model=Sequential()
model.add(Embedding(max_features,32,input_length=maxlen))
model.add(LSTM(16))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
#model.compile(loss='binary_crossentropy,mean_squared_error',
#optimizer='Adam,rmsprop')
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',metrics=['acc'])
returnmodel
defrun():
model=build_model(max_features,maxlen)
reduce_lr=ReduceLROnPlateau(monitor='val_loss',factor=0.2,patience=4,mode='auto',epsilon=0.0001)
model.fit(X,y,batch_size=512,epochs=20,validation_split=0.1,callbacks=[reduce_lr])
returnmodel
if__name__=="__main__":
startTime=time.time()
filename=sys.argv[1]
data=pd.read_csv(filename)
I=['v','i','%','}','r','^','a','c','y','.','_','|','h','w','d','g','{','!','$','[','','"',';','\t','>','<','\\','l','\n','\r','(','=',':','n','~','`','&','x',"'",'+','k',']',')','f','u','','0','q','#','m','@','*','e','z','?','t','s','b','p','o','-','j','/',',']
wordindex={k:v+2forv,kinenumerate(I)}
max_features=len(wordindex)+2#增加未知态(包含中文)和填充态
maxlen=128
X=np.array([arg2vec(x)forxindata['args']]).reshape(-1,128)
y=data['lable']
model=run()
logger.info("模型存储!")
modelname='model/lstm'+time.strftime('%y_%m_%d')+'.h5'
model.save(modelname)
3. 模型评估
测试时样本量为10000时,准确度为99.4%;
测试时样本量584万时,经过GPU训练准确度达到99.99%;
经观察识别错误样本,大多因长度切割的原因造成url片段是否具有攻击意图不好界定。
4. 小结
缺点:
- 资源开销大,预测效率低;
- 模型需要相同尺寸的输入;上文对大于128字节的url请求进行切割,对小于128字节的进行补0,这种死板的切割方式有可能破坏url原始信息。
优点:
- 不需要复杂的特征工程;
- 具备对未知攻击的识别能力;
- 泛化能力强。
五、一点思考
笔者因为工作的需要,尝试了很多种检测Web攻击的方向及特征的提取方式,但是都没有取得能令我非常满意的效果,甚至有时候也会对某个方向它本身存在的缺陷无法忍受。传统机器学习手段去做Web攻击识别,非常依赖特征工程,这消耗了我大多数时间而且还在持续着。
目前除了LSTM模型以外,苏宁的生产环境中表现最好的是MLP模型,但它本身也存在着严重的缺陷:因为这个模型的特征提取是基于Web攻击关键词的,在做特征提取的时候,为了保证识别的准确度不得不使用大量正则来进行分词、进行url泛化清洗,但是这种手段本质上跟基于规则的WAF没有太大区别。唯一的好处是多提供了一种不完全相同的检验手段从而识别出来一些WAF规则漏拦或者误拦的类型,从而对规则库进行升级维护。
长远来看我认为上文的LSTM检测方向是最有前途的;这里把每个字符当作一个特征向量,理论上只要给它喂养的样本足够充分,它会自己学习到一个字符集组合,出现在url的什么位置处所代表的含义,想真正的安全专家一样做到一眼就能识别出攻击,无论是什么变种的攻击。
转载请注明:IT运维空间 » 安全防护 » Web攻击检测的机器学习深度实践
你可能喜欢:
-

解决MySql版本问题sql_mode=only_full_group_by
-

Python操作mysql数据库出现pymysql.err.ProgrammingError: (1064, “You have an error in your SQL syntax; check
-

Oracle PL/SQL如何动态调用存储过程 收藏
-

Mysql 不存在则插入,存在则更新 mysql 存在该记录则更新,不存在则插入记录的sql
-

MySQL与Oracle之间互相拷贝数据的Java程序
-

MySQL导入sql文件的三种方法小结
-

MS sql server和mysql中update多条数据的例子
-

mysql防SQL注入搜集
-
Oracle:SQL语句–给用户赋权限
-
如何在MySql中记录SQL日志(例如Sql Server Profiler)








发表评论