

近日,一项研究显示,L4自动驾驶使用的多传感器融合感知(Multi-Sensor Fusion based Perception)技术存在一个安全漏洞:攻击者可以在道路中间放置一个3D打印的恶意障碍物,使自动驾驶车辆的camera和LiDAR机器学习检测模型都识别不到,并直接撞上去。
此项研究题为《对摄像头和激光雷达都不可见:物理世界攻击下的基于多传感器融合的自动驾驶感知安全》(Invisible for both Camera and LiDAR: Security of Multi-Sensor Fusion based Perception in Autonomous Driving Under Physical-World Attacks),已正式发表在计算机安全四大顶会之一IEEES&P2021。该研究团队来自加州大学尔湾分校(UCIrvine),专攻自动驾驶和智能交通的研究。
在自动驾驶系统里,实时感知周围环境是所有重要驾驶决策的最基本前提。当前,L4自动驾驶系统逐渐商业化,百度已经在北京、长沙和沧州开始大规模测试无人驾驶出租车,Waymo已经开始在美国凤凰城测试不需要安全驾驶员的完全自动驾驶出租车。
国际自动机工程师学会将自动驾驶从L1到L5分成了五个等级,L5是最高级的全自动化,L4级则是高度自动化,由机器接管全部操作,人不需要对所有的系统请求做出回答。有个关于L4级自动驾驶的戏说:看起来很像L5,但用户手册写了一长串免责声明,核心思想是这也不行,那也不行。
L4自动驾驶系统普遍采用多传感器融合设计,即融合如激光雷达(LiDAR)和摄像头(camera)等不同的感知源,从而实现准确并且鲁棒的感知。
多传感器融合算法有一项前提,所有感知源不会同时都被攻击,或可以同时被攻击。这个基本的安全设计假设一般都是成立的,因此多传感器融合通常被认为是针对现有无人车感知攻击(单感知源攻击)的有效防御策略。
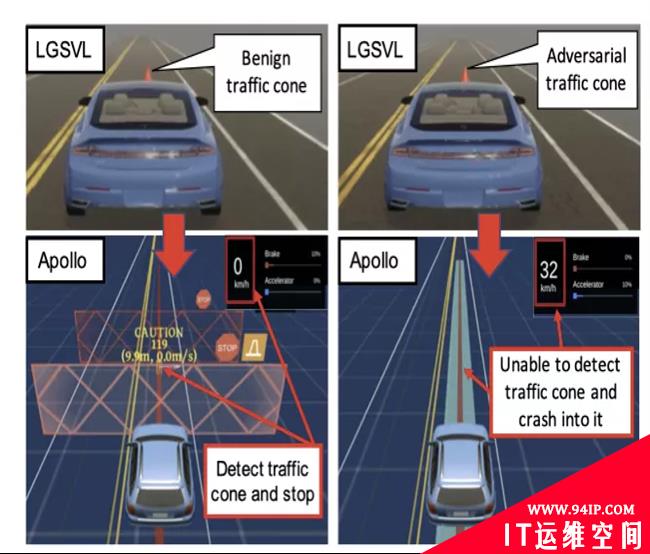
来自加州大学尔湾分校(UCIrvine)的研究者证明了同时攻击自动驾驶多传感器融合感知中所有感知源的可能性。他们发现,在现实世界识别过程中,这种多传感器融合的障碍物感知存在漏洞,会无法成功检测研究者设置的障碍物并直接撞上去的情况。
具体而言,3D障碍物的不同形状可以同时导致LiDAR点云中的点位置变化和camera图像中的像素值变化,因此攻击者可以利用形状操作,同时向camera和LiDAR引入输入扰动。

生活中路面可能出现的形状奇怪或破损的物体,可以研究者的物理世界攻击向量模拟:可操纵形状的对抗3D物体
为了评估这一漏洞的严重性,研究者设计了MSF-ADV攻击,它可以在给定的基于多传感器融合的无人车感知算法中自动生成上述的恶意的3D障碍,研究者的这个设计可提升攻击的有效性、鲁棒性、隐蔽性和现实生活中的可实现性。
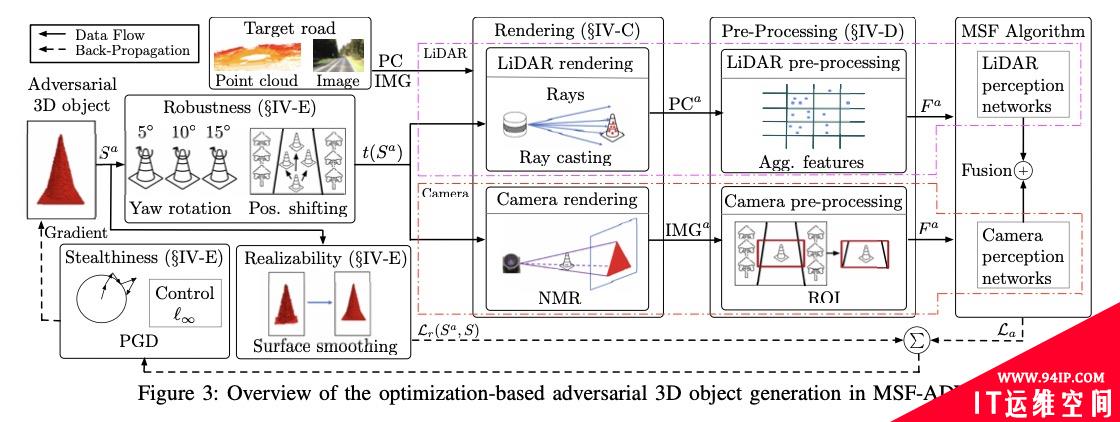
研究者选择了3种障碍物类型(交通锥、玩具车和长椅)进行测试,并在真实世界的驾驶数据上进行评估。他们的结果显示,在不同的障碍物类型和多传感器融合算法中,攻击实现了>=91%的成功率。
为了了解攻击在真实世界中的可实现性和严重性,研究者3D打印了生成的恶意障碍物,并在使用了多传感器融合感知得真车上进行评估。

3D打印出的恶意障碍物
研究者发现恶意的障碍物可以在总共108个传感器帧中的107帧中(99.1%)成功躲过多传感器融合的检测。在一个微缩模型的实验环境中,研究者发现恶意的障碍物在不同的随机抽样位置有85-90%的成功率躲避多传感器融合感知的检测,而且这种有效性可以转移。
研究者认为比较切实可行的防御手段是去融合更多的感知源,比如说更多的不同位置的camera和LiDAR,或者考虑加入RADAR。但是这不能从根本上防御,只能让恶意攻击更加困难
截至2021年5月18日,研究人员对31家开发或者测试无人车的公司进行了漏洞报告,其中19家(约61%)已经回复并表示目前正在调查其影响以及受到影响的程度。
转载请注明:IT运维空间 » 安全防护 » L4自动驾驶漏洞:感知算法可能无法避开人造3D恶意障碍物
你可能喜欢:
-

解决MySql版本问题sql_mode=only_full_group_by
-

Python操作mysql数据库出现pymysql.err.ProgrammingError: (1064, “You have an error in your SQL syntax; check
-

Oracle PL/SQL如何动态调用存储过程 收藏
-

Mysql 不存在则插入,存在则更新 mysql 存在该记录则更新,不存在则插入记录的sql
-

MySQL与Oracle之间互相拷贝数据的Java程序
-

MySQL导入sql文件的三种方法小结
-
MS sql server和mysql中update多条数据的例子
-
mysql防SQL注入搜集
-
Oracle:SQL语句–给用户赋权限
-

如何在MySql中记录SQL日志(例如Sql Server Profiler)












发表评论