

前 言
近年来,随着5G时代的到来以及物联网和云计算的迅猛发展,人类社会逐渐步入了大数据时代。所谓大数据,是指所涉及的数据量规模巨大,无法通过人工在合理时间内达到截取、管理、处理并整理成为人类所能解读的信息。大数据在带来发展机遇的同时,也带来了新的挑战,催生了新技术的发展和旧技术的革新。例如,不断增长的数据规模和数据的动态快速产生要求必须采用分布式计算框架才能实现与之匹配的吞吐和实时性。
1.大数据计算基本概念
1.1 离线计算
大数据离线计算技术应用于静态数据的离线计算和处理,框架设计的初衷是为了解决大规模、非实时数据计算,更加关注整个计算框架的吞吐量。离线计算的数据量大且计算周期长,是在大量数据基础上进行复杂的批量运算。离线计算的数据是不再会发生变化,通常离线计算的任务都是定时的,使用场景一般式对时效性要求比较低的。
1.2 实时流式计算
实时流式计算,或者是实时计算,流式计算,在大数据领域都是差不多的概念。那么,到底什么是实时流式计算呢?谷歌大神Tyler Akidau在《the-world-beyond-batch-streaming-101》一文中提到过实时流式计算的三个特征:无限数据、无界数据处理、低延迟:
- 无限数据:指的是一种不断增长的,基本上无限的数据集,这些通常被称为“流数据”,而与之相对的是有限的数据集。
- 无界数据处理:是一种持续的数据处理模式,能够通过处理引擎重复的去处理上面的无限数据,是能够突破有限数据处理引擎的瓶颈。
- 低延迟:延迟是指数据从进入系统到流出系统所用的时间,实时流式计算业务对延迟有较高要求,延迟越低,越能保证数据的实时性和有效性。
2.离线计算框架:大数据的主场
2.1 MapReduce计算框架
Hadoop是一个分布式系统架构,由Apache基金会所开发,其核心主要包括两个组件:HDFS和MapReduce,前者为海量存储提供了存储,而后者为海量的数据提供了计算。这里我们主要关注MapReduce。以下资料来源于Hadoop的官方说明文档和论文。
MapReduce是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。将计算过程分为两个阶段,Map和Reduce,Map阶段并行处理输入的数据,Reduce阶段对Map结果进行汇总。
一个MapReduce作业通常会把输入的数据集切分为若干独立的数据块,由Map任务以完全并行的方式处理它们。框架会对Map的输出先进行排序,然后把结果输入给Reduce任务。通常作业的输入和输出都会被存储在文件系统中。整个框架负责任务的调度和监控,以及重新执行已经失败的任务。
通常,MapReduce框架和分布式文件系统是运行在一组相同的节点上的,也就是说,计算节点和存储节点通常在一起。这种配置允许框架在那些已经存好数据的节点上高效地调度任务,这可以使整个集群的网络带宽被非常高效地利用。
MapReduce框架由一个单独的master JobTracker 和每个集群节点一个slave TaskTracker共同组成。master负责调度构成一个作业的所有任务,这些任务分布在不同的slave上,master监控它们的执行,重新执行已经失败的任务。而slave仅负责执行由master指派的任务。
应用程序至少应该指明输入/输出的路径,并通过实现合适的接口或抽象类提供map和reduce函数。再加上其他作业的参数,就构成了作业配置。然后,Hadoop的Job Client提交作业和配置信息给JobTracker,后者负责分发这些软件和配置信息给slave、调度任务并监控它们的执行,同时提供状态和诊断信息给Job Client。
MapReduce框架运转在
应用程序通常会通过提供map和reduce来实现 Mapper和Reducer接口,它们组成作业的核心。map函数接受一个键值对,产生一组中间键值对。MapReduce框架会将map函数产生的中间键值对中键相同的值传递给一个reduce函数。reduce函数接受一个键,以及相关的一组值,将这组值进行合并产生一组规模更小的值。如图1所示,MapReduce的工作流程中,一切都是从最上方的user program开始的,user program链接了MapReduce库,实现了最基本的Map函数和Reduce函数。图中执行的顺序都用数字标记了。
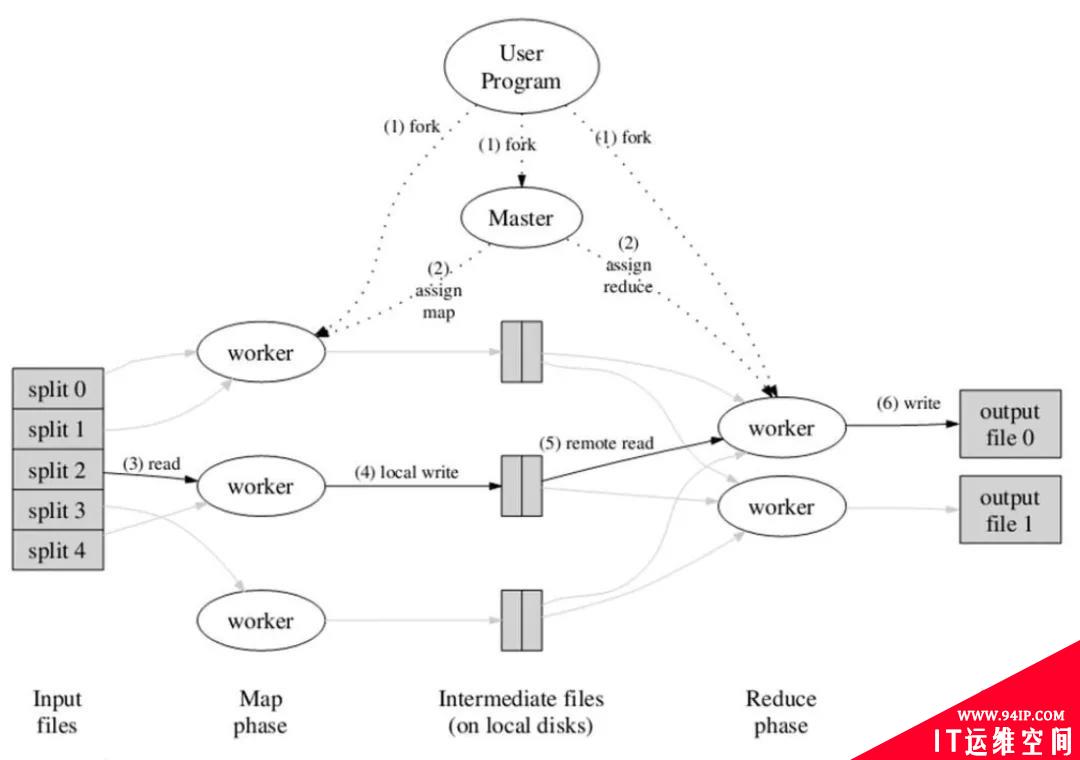
图1 MapReduce的执行流程
2.2 Spark计算框架
Spark基于MapReduce算法实现的离线计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的Map Reduce的算法。
Spark中一个主要的结构是RDD(Resilient Distributed Datasets),这是一种只读的数据划分,并且可以在丢失之后重建。它利用了Lineage的概念实现容错,如果一个RDD丢失了,那么有足够的信息支持RDD重建。RDD可以被认为是提供了一种高度限制的共享内存,但是这些限制可以使得自动容错的开支变得很低。RDD使用Lineage的容错机制,即每一个RDD都包含关于它是如何从其他RDD变换过来的以及如何重建某一块数据的信息。RDD仅支持粗颗粒度变换,即仅记录在单个块上执行的单个操作,然后创建某个RDD的变换序列存储下来,当数据丢失时,我们可以用变换序列来重新计算,恢复丢失的数据,以达到容错的目的。
Spark中的应用程序称为驱动程序,这些驱动程序可实现在单一节点上执行的操作或在一组节点上并行执行的操作。驱动程序可以在数据集上执行两种类型的操作:动作和转换。动作会在数据集上执行一个计算,并向驱动程序返回一个值;而转换会从现有数据集中创建一个新的数据集。动作的示例包括执行一个Reduce操作以及在数据集上进行迭代。转换示例包括Map操作和Cache操作。
与Hadoop类似,Spark支持单节点集群或多节点集群。对于多节点操作,Spark依赖于Mesos集群管理器。Mesos为分布式应用程序的资源共享和隔离提供了一个有效平台,参考图2。

图2 Spark 依赖于Mesos集群管理器
2.3 Dryad计算框架
Dryad是构建微软云计算基础设施的核心技术。编程模型相比MapReduce更具一般性——用有向无环图(DAG)描述任务的执行,其中用户指定的程序是DAG图的节点,数据传输的通道是边,可通过文件、共享内存或者传输控制协议(TCP)通道来传递数据,任务相当于图的生成器,可以合成任何图,甚至在执行的过程中这些图也可以发生变化,以响应计算过程中发生的事件。图3给出了整个任务的处理流程。Dryad在容错方面支持良好,底层的数据存储支持数据备份;在任务调度方面,Dryad的适用性更广,不仅适用于云计算,在多核和多处理器以及异构集群上同样有良好的性能;在扩展性方面,可伸缩于各种规模的集群计算平台,从单机多核计算机到由多台计算机组成的集群,甚至拥有数千台计算机的数据中心。Microsoft借助Dryad,在大数据处理方面也形成了完整的软件栈,部署了分布式存系统Cosmos,提供DryadLINQ编程语言,使普通程序员可以轻易进行大规模的分布式计算。
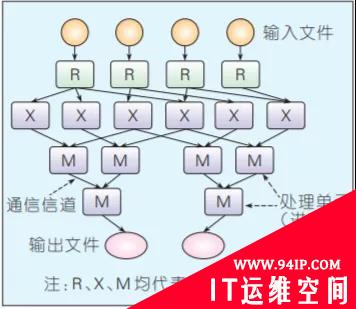
图3 Dyrad计算框架的任务处理流程
3.实时流计算框架:大数据的未来
如果遇到时效性更敏感的业务需求,我们需要用到哪些实时计算引擎?目前有很多专业的实时流计算框架,较为知名的包括Apache Storm、Spark Streaming、LinkIn Samza、Apache Flink和Google MillWheel等,但是其中最主流的无疑是Storm、Spark Streaming、Flink和Samza。
3.1 Storm计算框架
Hadoop提供了Map和Reduce原语,使得对数据进行批处理变得非常简单和优美。同样,Storm也对数据的实时计算提供了简单的Spout和Bolt原语。Storm集群表面上看和Hadoop集群非常像,但Hadoop上面运行的是MapReduce的Job,而Storm上面运行的是Topology,它们非常不一样,比如一个MapReduce Job最终会结束,而一个Storm Topology永远运行。Storm的集群架构如图4所示。
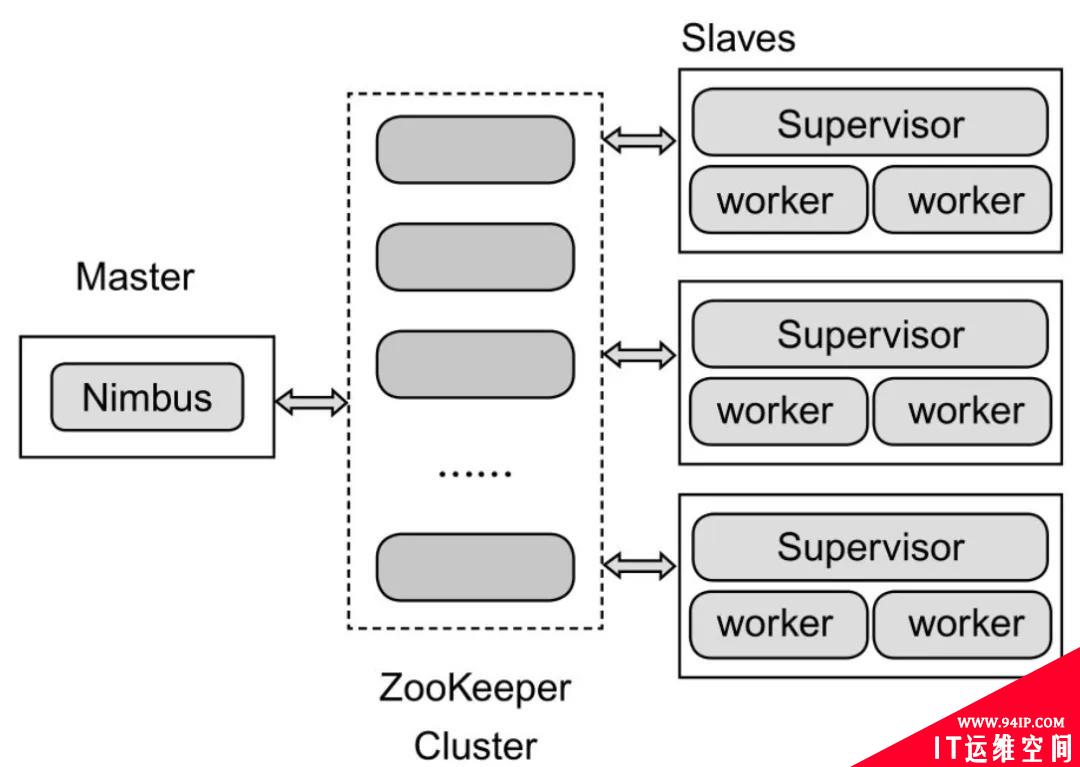
图4 Storm的集群架构
在应用Storm过程中会碰见Topology、Tuple、Spout、Bolt、流和流分组这些概念。其中Topology是一个实时应用程序,Tuple是处理的基本消息单元,Spout是Topology的流的来源,是一个Topology中产生源数据流的组件,Topology中的所有处理逻辑都在Bolt中完成。一个流由无数个元组序列构成,这些元组并行、分布式的被创建和执行,流分组是用来定义一个Stream应该如何分配数据给Bolts上的多个任务。
早期的Storm无法提供exactly once的语义支持,后期Storm引入了Trident高级原语,提供了exactly once的语义支持。然后提出了流计算中的反压概念,指的是Storm中的一个拓扑处理数据的速度小于数据流入的速度时的处理机制,通常来说,反压出现的时候,数据会迅速累积,如果处理不当,会导致资源耗尽甚至任务崩溃。这在流处理过程中非常常见,通常是由于源头数据量突然急剧增加所导致的,比如电商的大促、节日活动等。新的Storm自动反压机制通过监控Bolt中的接收队列的情况来实现,当超过高水位值时,专门的线程会将反压信息写到ZooKeeper, ZooKeeper上的Watch会通知该拓扑的所有Worker都进入反压状态,最后Spout降低Tuple发送的速度。
3.2 Spark Streaming计算框架
Spark Streaming是Spark核心API的扩展,用于处理实时数据流。Spark Streaming处理的数据源可以是Kafka,Flume,Twitter,HDFS或者Kinesis,这些数据可以使用map,reduce,join,window方法进行处转换,还可以直接使用Spark内置的机器学习算法,图算法包来处理数据。最终处理后的数据可以存入HDFS,Database或者Dashboard中,数据库。相比于Storm原生的实时处理框架,Spark Streaming是基于微批处理,微批处理是一种组织独立数据操作的方法,术语中的微,更具体的说来,就是指在内存中进行处理。术语中的批处理指的是Spark Streaming中数据处理的单位是一批而不是一条,Spark会等采集的源头数据累积到设置的间隔条件后,对数据进行统一的批处理。这个间隔是Spark Streaming中的核心概念和关键参数,直接决定了Spark Streaming作业的数据处理延迟,当然也决定着数据处理的吞吐量和性能。
Spark Streaming提供了一个叫做DStream的抽象概念,表示一段连续的数据流。在Spark Streaming内部中,DStream实际上是由一系列连续的RDD组成的。每个RDD包含确定时间间隔内的数据,这些离散的RDD连在一起,共同组成了对应的DStream。Spark Streaming的架构如下图5所示。

图5 Spark Streaming的架构
3.3 Flink计算框架
Storm延迟低但是吞吐量小,Spark Streaming吞吐量大但是延迟高,那么是否有一种兼具低延迟和高吞吐量特点的流计算技术呢?答案是有的,就是Flink。实际上,Flink于2008年作为柏林理工大学的一个研究性项目诞生,但是直到2015年以后才开始逐步得到认可和接受,这和其自身的技术特点契合了大数据对低实时延迟、高吞吐、容错、可靠性、灵活的窗口操作以及状态管理等显著特性分不开,当然也和实时数据越来越得到重视分不开。阿里巴巴启动了Blink项目,目标是扩展、优化、完善Flink,使其能够应用在阿里巴巴大规模实时计算场景。
Flink的整体结构如下图6所示。部署:Flink 支持本地运行(IDE 中直接运行程序)、能在独立集群(Standalone模式)或者在被 YARN、Mesos、K8s 管理的集群上运行,也能部署在云上。内核:Flink 的核心是分布式流式数据引擎,意味着数据以一次一个事件的形式被处理。API:包含了DataStream、DataSet、Table和SQL等API。库:Flink还包括用于CEP(复杂事件处理)、机器学习、图形处理等场景。
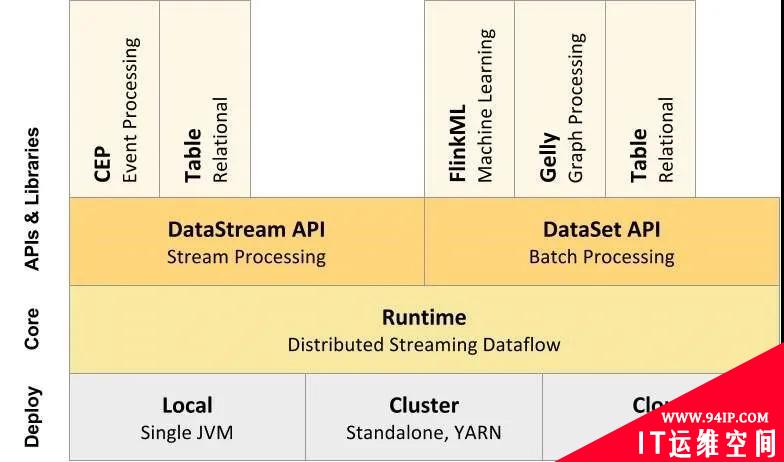
图6 Flink的整体结构
Flink的容错机制核心是分布式数据流和状态的快照,为了保证失败时从错误中恢复,因此需要对数据对齐。Flink采用了单机性能十分优异的RocksDB作为状态的后端存储,但单机是不可靠的,所以Flink还对将单机的状态同步到HDFS上以保证状态的可靠性。另外,对于从RocksDB到HDFS上checkpoint的同步,Flink也支持增量的方式,能够非常好地提高checkpoint的效率。Flink相比其他流计算技术的一个重要特性是支持基于Event Time的窗口操作。但是Event Time来自于源头系统,网络延迟、分布式处理以及源头系统等各种原因导致源头数据的事件时间可能是乱序的,即发生晚的事件反而比发生早的事件来得早,或者说某些事件会迟到。Flink参考Google的Cloud Dataflow,引入水印的概念来解决和衡量这种乱序的问题。并且在实时计算的某些场景,需要撤回之前的计算结果进行,Flink提供了撤回机制。
Storm是通过监控process bolt中的接收队列负载情况来处理反压,如果超过高水位值,就将反压信息写到ZooKeeper,由ZooKeeper上的watch通知该拓扑的所有worker都进入反压状态,最后spout停止发送tuple来处理的。而Spark Streaming通过设置属性“spark.streaming.backpressure.enabled”可以自动进行反压处理,它会动态控制数据接收速率来适配集群数据处理能力。对于Flink来说,不需要进行任何的特殊设置,其本身的纯数据流引擎可以非常优雅地处理反压问题。
3.4 Samza计算框架
Samza是Linkedin开源的分布式流处理框架,其架构如图8所示,由Kafka提供底层数据流,由YARN提供资源管理、任务分配等功能。图7也给出了Samza的作业处理流程,即Samza客户端负责将任务提交给YARN的资源管理器,后者分配相应的资源完成任务的执行。在每个容器中运行的流任务相对于Kafka是消息订阅者,负责拉取消息并执行相应的逻辑。在可扩展性方 面,底层的Kafka通过Zookeeper实现了动态的集群水平扩展,可提供高吞吐、可水平扩展的消息队列,YARN为Samza提供了分布式的环境和执行容器,因此也很容易扩展;在容错性方面,如果服务器出现故障,Samza和YARN将一起进行任务的迁移、重启和重新执行,YARN还能提供任务调度、执行状态监控等功能;在数据可靠性方面,Samza 按照Kafka中的消息分区进行处理,分区内保证消息有序,分区间并发执行,Kafka将消息持久化到硬盘保证数据安全。另外,Samza还提供了对流数据状态管理的支持。在需要记录历史数据的场景里,数据实时流动导致状态管理难以实现,为此,Samza提供了一个内建的键值数据库用来存储历史数据。
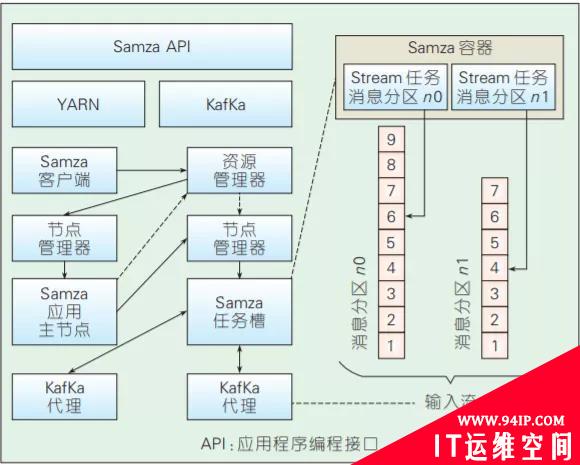
图7 Samza的整体架构
4.总 结
大数据计算框架的应用推进了技术的发展和革新,目前业界在不断提高大数据计算框架的吞吐量、实时性、可扩展性等特性以应对日益增长的数据量和数据处理需求,大数据计算框架依然是现在以及未来一段时间内的研究热点。未来的发展趋势是:随着商业智能和计算广告等领域的发展,更强调实时性的流计算框架将得到更加广泛的关注。总之,应用的推动和技术的进步将会产生新的问题。作为大数据应用的核心,对于挖掘数据价值起着重要作用的计算框架将会面临更多的挑战,亟待解决。本文参考了一些文献和网络资源,他们的观点和技术对本文做出的贡献表示感谢。
参考文献
[1] 李川,鄂海红,宋美娜.基于Storm的实时计算框架的研究与应用[J].软件,2014,35(10):16-20.
[2] https://izualzhy.cn/dataflow-reading
[3] https://juejin.im/post/5d49830cf265da03f3333b4c#heading-11
[4] Wenhong Tian, Yong Zhao, in Optimized Cloud Resource Management and Scheduling[M], 2015
[5] https://greeensy.github.io/2014/06/15/Batch-Computing/

转载请注明:IT运维空间 » 安全防护 » 聊一聊大数据计算框架
你可能喜欢:
-

解决MySql版本问题sql_mode=only_full_group_by
-

Python操作mysql数据库出现pymysql.err.ProgrammingError: (1064, “You have an error in your SQL syntax; check
-

Oracle PL/SQL如何动态调用存储过程 收藏
-

Mysql 不存在则插入,存在则更新 mysql 存在该记录则更新,不存在则插入记录的sql
-

MySQL与Oracle之间互相拷贝数据的Java程序
-

MySQL导入sql文件的三种方法小结
-

MS sql server和mysql中update多条数据的例子
-

mysql防SQL注入搜集
-
Oracle:SQL语句–给用户赋权限
-
如何在MySql中记录SQL日志(例如Sql Server Profiler)








发表评论