

互联网时代给用户带来了极大地便利,但也让个人隐私信息无处躲藏。打开电商购物平台,APP的精准推荐总是让人感到不安;打开搜索平台,跳出的智能搜索记录着浏览行为;打开娱乐软件,推荐算法让用户逐渐沉迷其中……
 虽然“隐私”在数字化的世界已经无处安放,但我们却很少去认真思考,隐私究竟是怎样被泄露的?
近日,诺顿LifeLock实验室研究后发现,超过8成带有搜索栏的网站会将访问者的搜索字词泄露给谷歌等在线广告商。
很明显这是在赤裸裸地侵犯用户隐私,并公然将敏感信息泄露给庞大的第三方服务商,借助这些信息,谷歌等在线广告商可以提供有针对性的广告或跟踪用户的网络行为。这些数据甚至有可能在这些服务商之间共享,又或者是多次转手出售给更多的企业,由此带来的恶果是,用户的隐私信息将会一直存在互联网上,一直被曝光。
虽然一些网站可能会在其用户政策中声明这种做法,但访问者通常不会阅读这些内容,并认为他们在嵌入式搜索字段中输入的信息是与大数据代理隔离的。
虽然“隐私”在数字化的世界已经无处安放,但我们却很少去认真思考,隐私究竟是怎样被泄露的?
近日,诺顿LifeLock实验室研究后发现,超过8成带有搜索栏的网站会将访问者的搜索字词泄露给谷歌等在线广告商。
很明显这是在赤裸裸地侵犯用户隐私,并公然将敏感信息泄露给庞大的第三方服务商,借助这些信息,谷歌等在线广告商可以提供有针对性的广告或跟踪用户的网络行为。这些数据甚至有可能在这些服务商之间共享,又或者是多次转手出售给更多的企业,由此带来的恶果是,用户的隐私信息将会一直存在互联网上,一直被曝光。
虽然一些网站可能会在其用户政策中声明这种做法,但访问者通常不会阅读这些内容,并认为他们在嵌入式搜索字段中输入的信息是与大数据代理隔离的。
用爬虫发现信息泄露
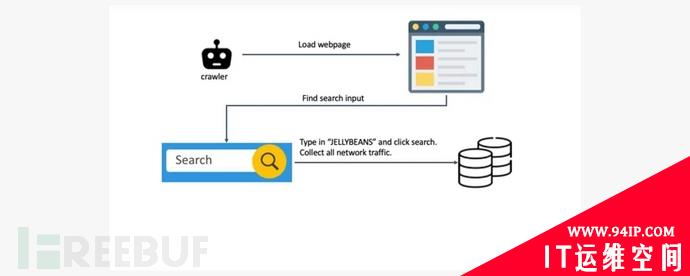
为了研究用户隐私信息泄露的普遍程度,诺顿LifeLock实验室开发了一个基于Chrome 浏览器的网络爬虫。该爬虫可以使用前100万个网站内部的搜索功能并执行搜索,最后搜索后捕获所有网络流量,以此查看用户的搜索词会流转到哪里。
为了区别于其他的普通搜索,实验室使用了一个特定的搜索词“jellybeans”,以确保可以在网络流量中轻松找到测试的搜索词。
 众所周知,一个典型的 HTTP 网络请求由三部分组成:URL、Request Header 和 payload。HTTP 请求标头是浏览器自动发送的元数据(见下文),有效负载是脚本或表单请求的附加数据,可能包括更详细的跟踪信息,例如浏览器指纹或点击流数据。
众所周知,一个典型的 HTTP 网络请求由三部分组成:URL、Request Header 和 payload。HTTP 请求标头是浏览器自动发送的元数据(见下文),有效负载是脚本或表单请求的附加数据,可能包括更详细的跟踪信息,例如浏览器指纹或点击流数据。
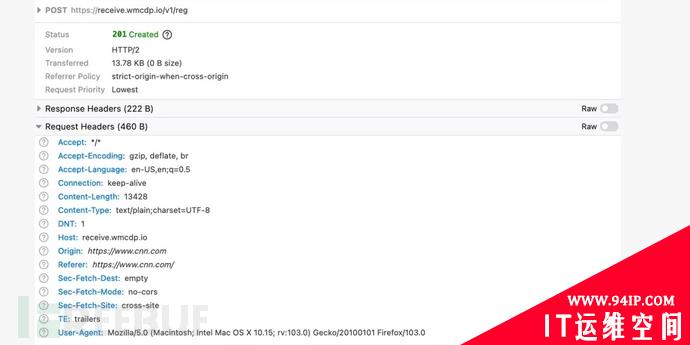 CNN 加载的广告的 HTTP 网络请求
在实际研究中,安全研究人员在网络请求的Referer 请求标头、URL 和有效负载中寻找关键词“jellybeans”。
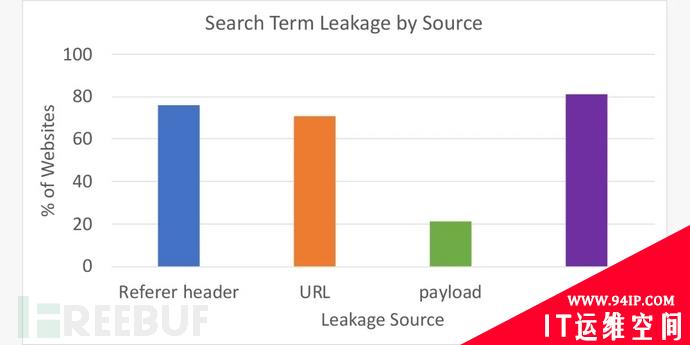
结果令人感到非常惊讶。在具有内部站点搜索功能的顶级网站中,安全研究人员发现,81.3%的网站都在以某种形式向第三方泄露搜索字词:75.8% 的网站通过Referer标头,71% 的网站通过URL,21.2%的网站通过有效载荷。这也就意味着网站通常会以多个向量泄露关键词。
CNN 加载的广告的 HTTP 网络请求
在实际研究中,安全研究人员在网络请求的Referer 请求标头、URL 和有效负载中寻找关键词“jellybeans”。
结果令人感到非常惊讶。在具有内部站点搜索功能的顶级网站中,安全研究人员发现,81.3%的网站都在以某种形式向第三方泄露搜索字词:75.8% 的网站通过Referer标头,71% 的网站通过URL,21.2%的网站通过有效载荷。这也就意味着网站通常会以多个向量泄露关键词。
 研究人员强调,八成只是最低的数字,因为他们仅在三个特定位置查找“jellybeans”搜索字符串,还有不少有效载荷被混淆以避免被工具检查,因此有效载荷的实际数量将会更高。
鉴于如此严峻的结果,安全研究人员很好奇这些网站是否都告知用户,其搜索关键词将会被发给第三方服务商。事实上,自欧洲通用数据保护条例 (GDPR) 和加利福尼亚州消费者隐私法 (CCPA) 通过以来,许多网站都更新了各自的隐私政策,那么又有多少网站明确告知了这些内容?
为此安全研究人员再次使用爬虫爬取了隐私政策,并建立了一个人工智能逻辑来阅读隐私政策,结果发现只有13% 的隐私政策明确提到了用户搜索词的处理,如此之低的比例再次让安全研究人员感到震惊。这不仅侵犯了用户隐私,而且还侵犯了用户的知情同意权。
参考
研究人员强调,八成只是最低的数字,因为他们仅在三个特定位置查找“jellybeans”搜索字符串,还有不少有效载荷被混淆以避免被工具检查,因此有效载荷的实际数量将会更高。
鉴于如此严峻的结果,安全研究人员很好奇这些网站是否都告知用户,其搜索关键词将会被发给第三方服务商。事实上,自欧洲通用数据保护条例 (GDPR) 和加利福尼亚州消费者隐私法 (CCPA) 通过以来,许多网站都更新了各自的隐私政策,那么又有多少网站明确告知了这些内容?
为此安全研究人员再次使用爬虫爬取了隐私政策,并建立了一个人工智能逻辑来阅读隐私政策,结果发现只有13% 的隐私政策明确提到了用户搜索词的处理,如此之低的比例再次让安全研究人员感到震惊。这不仅侵犯了用户隐私,而且还侵犯了用户的知情同意权。
参考
转载请注明:IT运维空间 » 安全防护 » 原来用户隐私是这样被泄露:超八成搜索网站将信息出售
你可能喜欢:
-

解决MySql版本问题sql_mode=only_full_group_by
-

Python操作mysql数据库出现pymysql.err.ProgrammingError: (1064, “You have an error in your SQL syntax; check
-

Oracle PL/SQL如何动态调用存储过程 收藏
-

Mysql 不存在则插入,存在则更新 mysql 存在该记录则更新,不存在则插入记录的sql
-

MySQL与Oracle之间互相拷贝数据的Java程序
-

MySQL导入sql文件的三种方法小结
-
MS sql server和mysql中update多条数据的例子
-
mysql防SQL注入搜集
-

Oracle:SQL语句–给用户赋权限
-
如何在MySql中记录SQL日志(例如Sql Server Profiler)











发表评论