

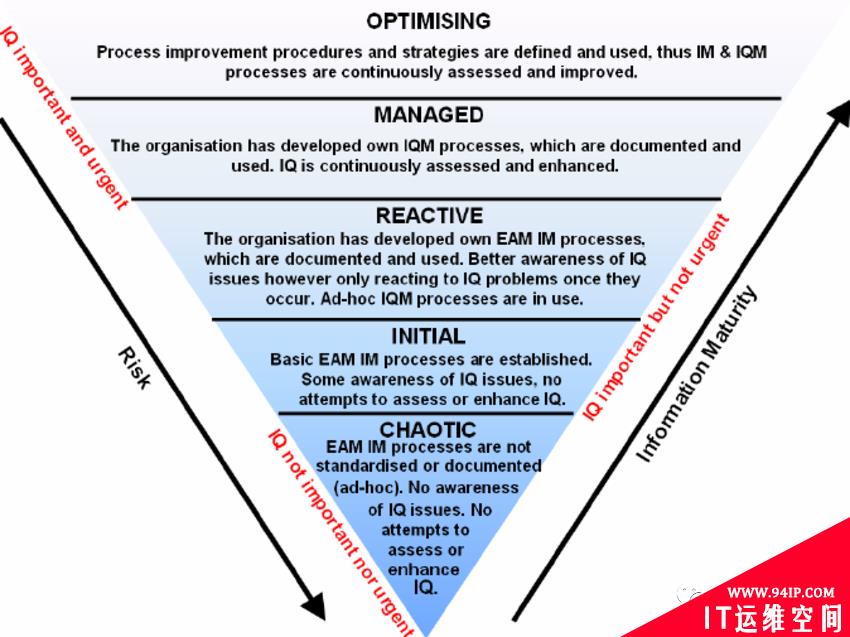
生成可供分析的数据的一个关键要求是数据必须是“好”的。各组织对良好数据质量的定义存在差异,这些定义符合其在分析和数据科学方面的成熟度。
由于两个原因,成熟度模型类比似乎适合这里。首先,模型中的关卡是相互依存的,在掌握较低的关卡之前不可能达到更高的关卡。其次,向更高层次移动不仅仅是工具或算法的问题,因为它还需要不同的流程和组织思维。
第1级:数据来源
了解数据来自哪里、如何收集、如何转换、为什么以及由谁转换,是任何可用数据集的最基本要求。例如,在临床环境中——如果我们不知道哪个实验室进行了测试,谁资助了这项研究,血压是站立还是坐下,或者在我们得到试验结果之前是否将某些患者从试验结果中剔除——数据实际上是无用的。 拥有关于每个数据集的明确出处、沿袭、所有者和其他元数据——甚至在查看数据本身之前——是任何数据分析之前的基本要求。在医疗保健领域,披露利益冲突、资金来源、隐私和其他道德考虑也是关键。 俗话说——“如果你足够折磨数据,它会告诉你任何事情”。
第2级:基本卫生
在这个级别,团队关注的是基本数据元素的统一表示:
-
数字(格式为“3,500”或“3500”)
空值(将“null”、“N/A”、“na”、“?”、“-1”和“未指定”格式化为单个值)
标准单位和标准单位的转换(格式为“30lbs”至“13.6”,单位为 kg)
地理空间点、圆、弧和多边形
日期和时间、货币、姓名、地址、电子邮件、布尔值和其他常见类型
大多数这些价值观都有国际标准,尽管通常有不止一个“标准”在起作用。对于数据消费者而言,正确的选择始终是“工具本身可以理解的格式”——因此,如果该工具是 Tableau、R、pandas 或 Excel,答案可能会有所不同。 大多数提供数据质量指标、数据完整性或丰富性指标、自动数据规范化或主数据管理的工具都在这个级别上运行。
第 3 级:异常值、混乱和不太可能的组合
下一个级别超越单个数据元素,进入描述性统计数据和可能的错误。例如,一名患者服用 12,345 种不同类型的药物很可能是数据输入错误,或者至少是在计算对异常值敏感的描述性统计数据(如均值和标准差)时应排除的异常值。
有时问题不是个别异常值,而是一连串几乎是例外的情况。例如,在一个网站每秒网络流量的数据集中,10 分钟内从历史标准增加 100 倍的可能性要大得多,这很可能是机器人的结果,而不是真实用户活动的结果。Flurries 经常出现在时间序列数据中,必须根据具体情况决定保留或删除。
领域专家还应该深入挖掘以发现由于不太可能的组合而导致的错误。特别是在医疗保健领域,通常可以识别出临床上不太可能的组合。例如,在一个案例中,一个 25 岁的女性体重 535 磅本身是合理的,但查看同一患者的其他测量和实验室结果,很明显这是一个打字错误53.5磅的女人。这种“临床上不太可能的组合”通常是数据输入错误,应该在下游数据分析之前消除。
第 3 级需要更深入的统计知识以及 DataOps 团队更深入的领域专业知识。如示例所示,在此级别“固定”数据质量不再能够完全自动化。
第 4 级:覆盖缺口
下一个层次超越了将数据集的质量描述为一种通用度量——讨论是否适合给定的分析项目。这尤其涉及识别所提供数据中的差距,并找到补充它们的方法。 例如,考虑一个跟踪英国儿童疫苗接种率的项目。收集的数据可能存在空间覆盖缺口(即没有在威尔士收集数据)、时间覆盖缺口(有 15 年的数据,由于当年的预算限制,2010 年除外)或人口覆盖缺口(即不在学校没有被调查)。 这种差距的重要性在很大程度上取决于项目。例如,如果目标是识别有风险的孩子,那么找到不在学校的孩子可能很关键;然而,如果目标是比较男孩和女孩,这种差距可能不会破坏整个分析。做出正确的决定和更正需要您的分析团队和 DataOps 团队之间的协作。
第 5 级:偏见
在更高的层次上,运行完全集成的项目团队,团队结合了数据科学、DataOps 和软件工程师。人们每天都在同一个项目上工作,这样可以发现和解决已经“通过”所有先前级别的质量门的数据中细微但关键的偏差。
这最常适用于机器学习和数据挖掘项目。例如,假设我们正在寻找一种算法,该算法可以根据患者的医院临床记录自动分配 ICD-10 诊断和程序代码。为了训练它,我们只能从镇上的两家医院之一获得数据。两家医院都设有内科病房,但其中一家专攻心脏病学和肿瘤学(并且处理了大多数病例),而另一家专攻免疫学、内分泌学和老年医学。
请注意,无论我们选择哪家医院——我们的训练数据中诊断和程序代码的分布都将与我们将在“现实世界”中观察到的情况有所偏差,这将扭曲机器学习算法,因为先验分布训练数据中的数据将不同于在线观察到的数据。
 数据集的选择也会导致其他不太明显的偏差。每家医院本质上都会经历不同的年龄、性别和合并症分布——因为在医疗保健领域,所有这些都是相关的。这意味着,由于这些关系和相关性,有监督和无监督学习算法都会以微妙但重要的方式出现偏差。
这在实践中具有重要意义,因为我们越来越依赖机器来做出影响人们健康和福祉的日常决策。您对训练数据的选择隐含地忽略了其中没有代表的人,并且可能会根据他们过去的行为过度惩罚或奖励那些被代表的人。这基本上是一个数据质量问题。
了解此类问题的存在并有效解决这些问题需要数据科学家和 DataOps 专家之间持续进行深入合作,这是生成机器学习模型或预测分析的必要条件,这些模型或预测分析不受未公开偏见的影响并经受住现实世界的考验采用。
数据集的选择也会导致其他不太明显的偏差。每家医院本质上都会经历不同的年龄、性别和合并症分布——因为在医疗保健领域,所有这些都是相关的。这意味着,由于这些关系和相关性,有监督和无监督学习算法都会以微妙但重要的方式出现偏差。
这在实践中具有重要意义,因为我们越来越依赖机器来做出影响人们健康和福祉的日常决策。您对训练数据的选择隐含地忽略了其中没有代表的人,并且可能会根据他们过去的行为过度惩罚或奖励那些被代表的人。这基本上是一个数据质量问题。
了解此类问题的存在并有效解决这些问题需要数据科学家和 DataOps 专家之间持续进行深入合作,这是生成机器学习模型或预测分析的必要条件,这些模型或预测分析不受未公开偏见的影响并经受住现实世界的考验采用。
转载请注明:IT运维空间 » 安全防护 » 数据质量成熟度模型:分析数据准备的五个级别
你可能喜欢:
-

解决MySql版本问题sql_mode=only_full_group_by
-

Python操作mysql数据库出现pymysql.err.ProgrammingError: (1064, “You have an error in your SQL syntax; check
-
Oracle PL/SQL如何动态调用存储过程 收藏
-
Mysql 不存在则插入,存在则更新 mysql 存在该记录则更新,不存在则插入记录的sql
-
MySQL与Oracle之间互相拷贝数据的Java程序
-

MySQL导入sql文件的三种方法小结
-

MS sql server和mysql中update多条数据的例子
-

mysql防SQL注入搜集
-

Oracle:SQL语句–给用户赋权限
-

如何在MySql中记录SQL日志(例如Sql Server Profiler)










发表评论