


造成系统异常宕机(无响应、异常重启)的原因有很多种,最常见的是操作系统内部缺陷和设备驱动缺陷。本文作者将和大家分享内存转储分析的底层逻辑和方法论,并通过一个线上真实案例来展示从分析到得出结论的整个过程,希望对同学们处理此类问题和对系统的理解上有所帮助。
相信凡是与计算机高频亲密接触的人,都遇到过系统无响应,或突然重启的情况。这样的情况如果发生在客户端设备,如手机,或者笔记本电脑上,且不是频繁出现,基本上我们的解法就是鸵鸟算法,即默默重启设备,然后继续使用,当作什么都没发生过。
但是,如果这样的问题发生在服务端,比如运行微信、微博后台程序的虚拟机或者物理机上,那往往会产生相当严重的影响。轻则导致业务中断,重则导致业务长时间无法工作。
大家都知道,驱动这些计算机的是运行在其上的操作系统,如 Windows 或者 Linux 等。系统异常宕机(无响应、异常重启)的原因有很多种,但总体来看,操作系统内部缺陷,或者设备驱动缺陷是最常见的两类原因。
从根本上解决这类问题“唯一正确”的方法,是操作系统内存转储分析(Memory Dump Analysis)。内存转储分析属于高阶的软件调试能力,需要工程师有丰富且全面的系统级别理论知识和大量的疑案破解似的上手实践经验。
内存转储分析的方法论
内存转储分析是对专业能力要求极高的一个工作,也是非常不容易的一件事情。在以往案例分享后,得到比较有趣的反馈,如“耳边想起了柯南的配音”,或者“真黑猫警长!做的是 IT 工程师,却整天搞刑侦工作”。
内存转储分析需要用到的基础能力,包括但不限于反汇编、汇编分析、各种语言的代码分析,系统层面各种结构的理解,如堆,栈,虚表等,甚至深入到 bit 级别。
试想,一个系统运行了很长一段时间。在这段时间里,系统积累了大量正常、甚至不正常的状态。这时如果系统突然出现了一个问题,那这个问题十有八九跟长时间积累下来的状态有关系。
分析内存转储,就是分析发生问题时,系统产生的“快照”。实际上需要工程师以这个快照为出发点,追溯历史,找出问题发生源头。这有点像是从案发现场,推理案发经过一样。
死锁分析方法
内存转储分析方法,可以从所要解决问题的角度,简单分成两类,分别是死锁分析方法,和异常分析方法。这两种方法的区别在于,死锁分析方法以系统全局为出发点,而异常分析则从具体异常点开始。
死锁问题表现出来,就是系统不响应问题。死锁分析方法着眼于全局。这里的全局,就是整个操作系统,包括所有进程在内的系统全貌。我们从教科书里学到的知识,一个运行中的程序,包括了代码段,数据段和堆栈段。用这个方法去看一个系统也同样适合。系统的全貌,其实就包括正在被执行的代码(线程),和保存状态的数据(数据、堆栈)。
死锁的本质,是系统中部分或者全部线程,进入了互相等待且互相依赖的状态,使得进程所承载的任务无法被继续执行了。所以我们分析这类问题的中心思想,就是分析系统中所有的线程的状态和它们之间的依赖关系,正如如图 1 所示。
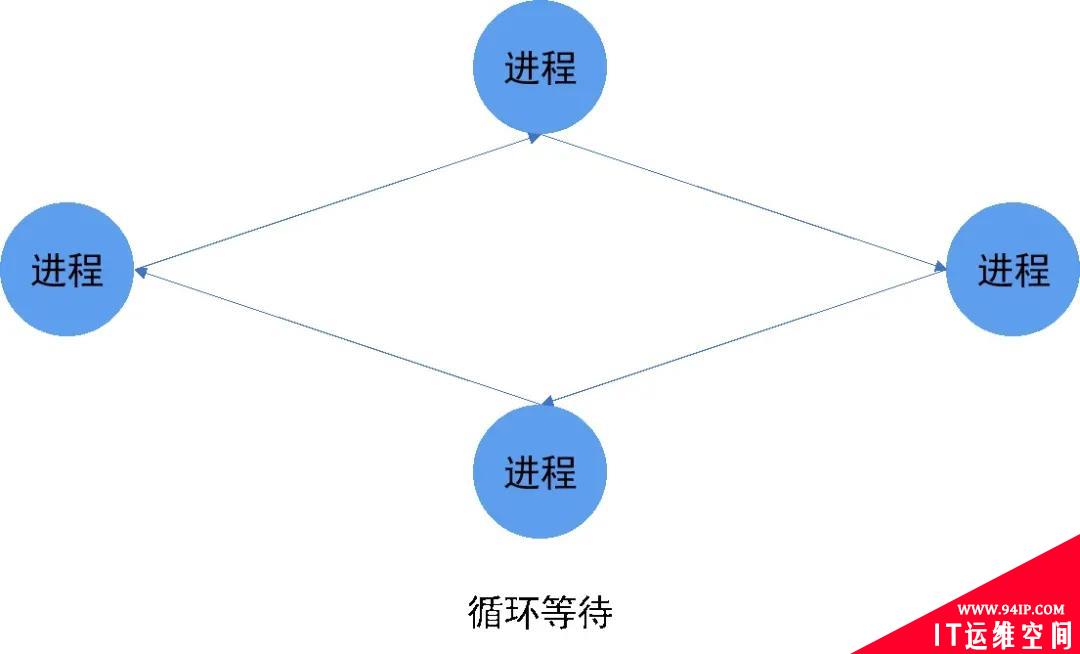
图 1
线程的状态相对来说是比较确定的信息。我们可以通过读取内存转储中线程的状态标志位,来获取这类的信息。而依赖关系分析则需要很多的技巧和实践经验。最常用分析方法有对象的持有等待关系分析,时序分析等。
异常分析方法
相对死锁分析,异常分析方法的核心是异常。我们经常遇到的异常有除零操作,非法指令执行,错误地址访问,甚至包括软件层面自定义的非法操作等。这些异常反应到操作系统层面,就是异常重启类宕机问题。
异常问题归根结底是处理器执行了具体的指令而触发的。换句话说,我们看到的现象,肯定是处理器踩到了异常点。所以分析异常类问题,我们需要从异常点出发,逐步地推导出代码执行到这一点的完整逻辑。
以经验来看,懂得做内存转储异常分析的工程师不多,而理解以上一点的人更是少之又少。很多工程师分析异常重启问题,基本上只停留在异常本身,根本没有推导出问题背后的整个逻辑。
相比死锁分析方法,异常分析的方法没有那么多固定的章法,甚至很多时候,因为问题逻辑复杂,我们没有办法找出根本原因。
总体看来,异常分析的底层逻辑,是不断地对比预期和非预期的状况,然后找出背后的原因。比如处理其执行了错误指令而触发的异常,那我们需要从回答正常被执行的指令应该是什么,为什么处理器拿到了这个错误指令这两个问题开始,不断深入,追根究底。
用死锁分析方法处理异常问题,用异常分析方法处理死锁问题
以上两种内存转储分析方法,是基于问题分析的起点和一般性分析手段来分类的。在实际问题处理过程中,我们经常需要从系统全局状态中,找到进一步处理异常问题的思路,也会用具体细节分析手段,来给全局类问题最后一击。
黑客与宕机
问题背景
宕机问题有一种比较少见的问题模式,就是看起来完全不相关的机器同时出现宕机。处理这个模式的问题,我们需要找到在这些机器上能同时触发问题的条件。
通常,这些机器要么几乎在同一时间点出现问题,要么从某一个时间点开始,相继出现问题。对于前一种情况,比较常见的情形是,物理设备故障导致运行在其上的所有虚拟机宕机,或者一个远程管理软件同时杀死了多个系统的关键进程;对于后一种情况,可能的一个原因是,用户在所有实例上部署了同一个有问题的模块(软件、驱动)。
而实例被大范围地攻击,则是另一个常见的原因。比如在 WannaCry 勒索病毒肆虐的时候,经常出现一些公司,或者一些部门的机器全部蓝屏的情形。
在这个案例中,用户安装了阿里云的云监控产品之后,出现了大范围云服务器连续宕机的情况。为了自证清白,我们耗费了不少体力脑力来深入分析这个问题。通过此案例分享,希望能给读者以启发。
坏掉的内核栈
我们处理操作系统宕机类问题的唯一正确方法是内存转储。不管是 Linux 或 Windows,在系统宕机之后,都能够通过自动,或者人工的方式,产生内存转储。
分析 Linux 内存转储的第一步,我们使用 crash 工具打开内存转储,并用 sys 命令观察系统的基本信息和宕机的直接原因。对于这个问题来说,宕机的直接原因是"Kernel panic – not syncing: stack-protector: Kernel stack is corrupted in: ffffxxxxxxxx87eb",如图 2 所示。
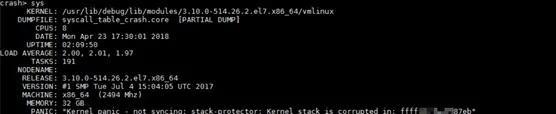
图2
关于这条信息,我们必须逐字解读。"Kernel panic – not syncing:" 这部分内容在内核函数panic 里输出,凡是调用到 panic 函数,必然会有这一部分输出,所以这一部分内容和问题没有直接关系。而"stack-protector: Kernel stack is corrupted in:" 这部分内容,在内核函数__stack_chk_fail,这个函数是一个堆栈检查函数,它会检查堆栈,同时在发现问题的时候调用panic 函数产生内存转储报告问题。
而它报告的问题是堆栈损坏。关于这个函数,后续我们会进一步分析。
而 ffffxxxxxxxx87eb 这个地址,是函数 __builtin_return_address(0) 的返回值。当这个函数的参数是 0 的时候,这个函数的输出值是调用它的函数的返回地址。这句话现在有点绕,但是后续分析完调用栈,问题就会变得很清楚。
函数调用栈
分析宕机问题的核心,就是分析 panic 的调用栈。图 3 中的调用栈,乍看起来是system_call_fastpath 调用了 __stack_chk_fail,然后 __stack_chk_fail 调用了 panic,报告了堆栈损坏的问题。但是稍微和类似的堆栈作一点比较的话,就会发现,事实并非这么简单。
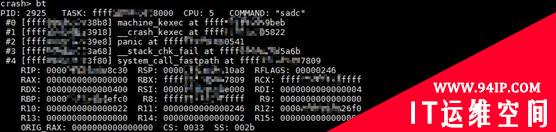
图3
图 4 是一个类似的,以 system_call_fastpath 函数开始的调用栈。不知道大家有没有看出来这个调用栈和上边调用栈的不同。实际上,以 system_call_fastpath 函数开始的调用栈,表示这是一次系统调用(system call)的内核调用栈。
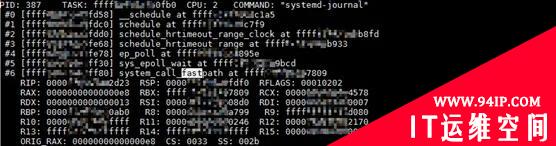
图4
图 4 的调用栈,表示用户模式的进程,有一次 epoll 的系统调用,然后这个调用进入了内核模式。而图 3 中的调用栈显然是有问题的,因为我们就算查遍所有的文档,也不会找到一个系统调用,会对应于内核 __stack_chk_fail 函数。
这里需要提醒的是,这边引出另外一个,在分析内存转储的时候需要注意的问题,就是用 bt 打印出来的调用栈有的时候是错误的。
所谓的调用栈,其实不是一种数据结构。用 bt 打印出来的调用栈,其实是从真正的数据结构,线程内核堆栈中,根据一定的算法重构出来的。而这个重构过程,其实是函数调用过程的一个逆向工程。
相信大家都知道堆栈的特性,即先进后出。关于函数调用,以及堆栈的使用,可以参考图 5。可以看到,每个函数调用,都会在堆栈上分配到一定的空间。而 CPU 执行每个函数调用指令 call,都会顺便把这条 call 指令的下一条指令压栈。这些“下一条指令”,就是所谓的函数返回地址。
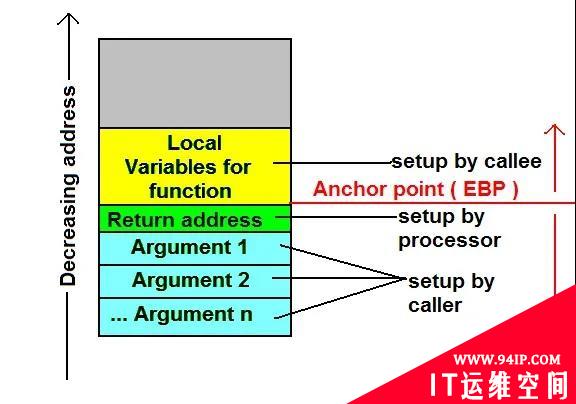
图5
这个时候,我们再回头看 Panic 的直接原因那一部分,即函数 __builtin_return_address(0) 的返回值。
这个返回值,其实就是调用 __stack_chk_fail 的 call 指令的下一条指令,这条指令属于调用者函数。这条指令地址被记录为 ffffxxxxxxxx87eb。
如图 6 所示,我们用 sym 命令查看这个地址临近的函数名,显然这个地址不属于函数system_call_fastpath,也不属于内核任何函数。这也再次验证了,panic 调用栈是错误的这个结论。

图6
关于 raw stack,如图7所示,我们可以用 bt -r 命令来查看。因为 raw stack 往往有几个页面,这里只截图和 __stack_chk_fail 相关的这一部分内容。
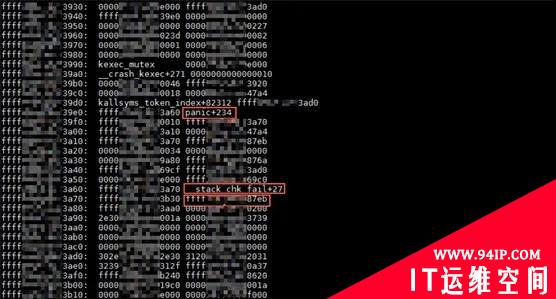
图7
这部分内容,有三个重点数据需要注意,panic 调用 __crash_kexec 函数的返回值,这个值是panic 函数的一条指令的地址;__stack_chk_fail 调用 panic 函数的返回值,同样的,它是__stack_chk_fail 函数的一条指令的地址;ffffxxxxxxxx87eb 这个指令地址,属于另外一个未知函数,这个函数调用了 __stack_chk_fail。
Syscall number 和 Syscall table
因为带有 system_call_fastpath 函数的调用栈,对应着一次系统调用,而 panic 的调用栈是坏的,所以这个时候我们自然而然会疑问,到底这个调用栈对应的是什么系统调用。
在 linux 操作系统实现中,系统调用被实现为异常。而操作系统通过这次异常,把系统调用相关的参数,通过寄存器传递到内核。在我们使用 bt 命令打印出调用栈的时候,我们同时会输出,发生在这个调用栈上的异常上下文,也就是保存下来的,异常发生的时候,寄存器的值。
对于系统调用(异常),关键的寄存器是 RAX,如图 8 所示。它保存的是系统调用号。我们先找一个正常的调用栈验证一下这个结论。0xe8 是十进制的 232。
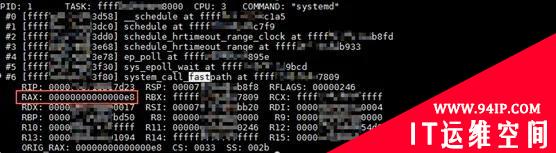
图8
使用 crash 工具,sys -c 命令可以查看内核系统调用表。我们可以看到,232 对应的系统调用号,就是 epoll,如图 9 所示。
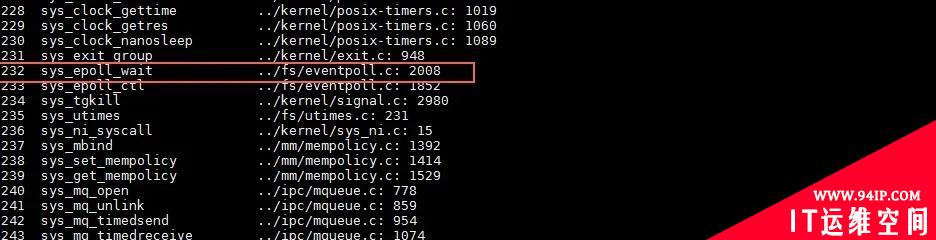
图9
这个时候我们再回头看“函数调用栈”这节的图 3,我们会发现异常上下文中 RAX 是 0。正常情况下这个系统调用号对应 read 函数,如图 10 所示。
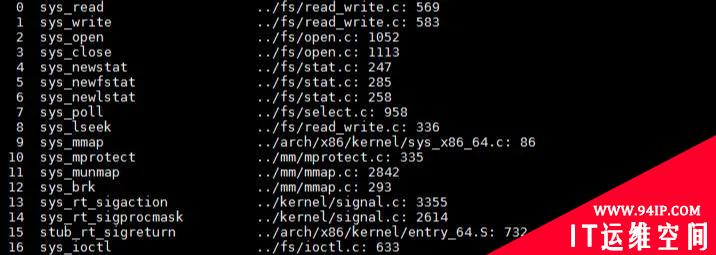
图10
从图 11 中,我们可以看出,有问题的系统调用表显然是被修改过的。修改系统调用表(system call table)这种事情,常见的有两种代码会做,这个相当辩证。一种是杀毒软件,而另外一种是病毒或木马程序。当然还有另外一种情况,就是某个蹩脚的内核驱动,无意识地改写了系统调用表。
另外我们可以看到,被改写过的函数的地址,显然和最初被 __stack_chk_fail 函数报出来的地址,是非常邻近的。这也可以证明,系统调用确实是走进了错误的 read 函数,最终踩到了__stack_chk_fail 函数。
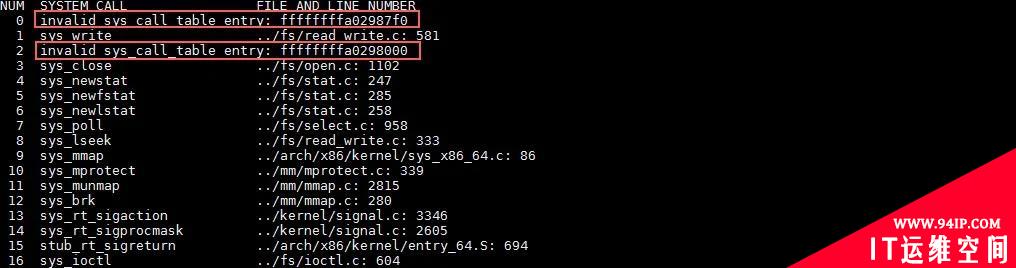
图11
Raw data
基于上边的数据,来完全说服客户,总归还是有点经验主义。更何况,我们甚至不能区分,问题是由杀毒软件导致的,还是木马导致的。这个时候我们花费了比较多的时间,尝试从内存转储里挖掘出 ffffxxxxxxxx87eb 这个地址更多的信息。
有一些最基本的尝试,比如尝试找出这个地址对应的内核模块等等,但是都无功而返。这个地址既不属于任何内核模块,也不被已知的内核函数所引用。这个时候,我们做了一件事情,就是把这个地址前后连续的,所有已经落实(到物理页面)的页面,用 rd 命令打印出来,然后看看有没有什么奇怪的字符串可以用来作为 signature 定位问题。
就这样,我们在邻近地址发现了下边这些字符串,如图 12 所示。很明显这些字符串应该是函数名。我们可以看到 hack_open 和 hack_read 这两个函数,对应被 hacked 的 0 和 2 号系统调用。还有函数像 disable_write_protection 等等。这些函数名,显然说明这是一段“不平凡”的代码。
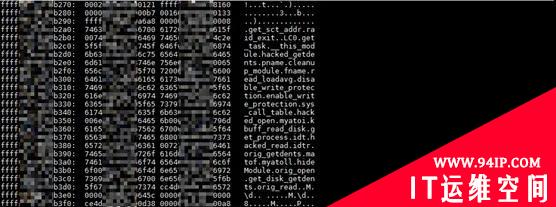
图12
后记
宕机问题的内存转储分析,需要我们足够的耐心。我个人的一条经验是:every bit matters,就是不要放过任何一个 bit 的信息。内存转储因为机制本身的原因,和生成过程中一些随机的因素,必然会有数据不一致的情况,所以很多时候,一个小的结论,需要从不同的角度去验证。
你可能喜欢:
-

解决MySql版本问题sql_mode=only_full_group_by
-

Python操作mysql数据库出现pymysql.err.ProgrammingError: (1064, “You have an error in your SQL syntax; check
-

Oracle PL/SQL如何动态调用存储过程 收藏
-

Mysql 不存在则插入,存在则更新 mysql 存在该记录则更新,不存在则插入记录的sql
-

MySQL与Oracle之间互相拷贝数据的Java程序
-

MySQL导入sql文件的三种方法小结
-

MS sql server和mysql中update多条数据的例子
-
mysql防SQL注入搜集
-
Oracle:SQL语句–给用户赋权限
-
如何在MySql中记录SQL日志(例如Sql Server Profiler)











发表评论