

相信只要是个稍微像样点的互联网公司,或多或少都有自己的一套缓存体系。

图片来自 Pexels
只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,遂笔者想在这和大家聊一聊:如何解决一致性问题?
如何保证缓存与数据库双写一致性,也是现在 Java 面试中面试官非常喜欢问的一个问题!
一般来说,如果允许缓存可以稍微跟数据库偶尔有不一致,也就是说如果你的系统不是严格要求缓存+数据库必须保持一致性的话,最好不要做这个方案。
即:读请求和写请求串行化,串到一个内存队列里去,从而达到防止并发请求导致数据错乱的问题,场景如图所示:
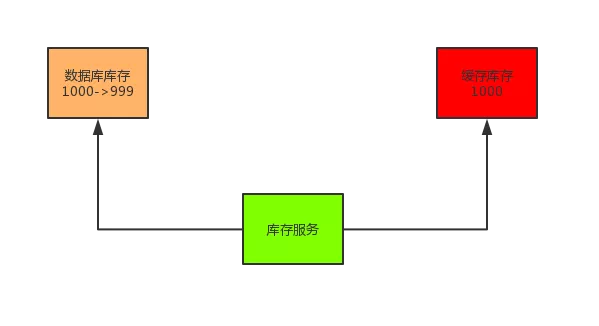
值得注意的是,串行化可以保证一定不会出现不一致的情况,但是它也会导致系统的吞吐量大幅度降低,用比正常情况下多几倍的机器去支撑线上的一个请求(土豪请自觉无视此提醒)。
解决思路如下图:
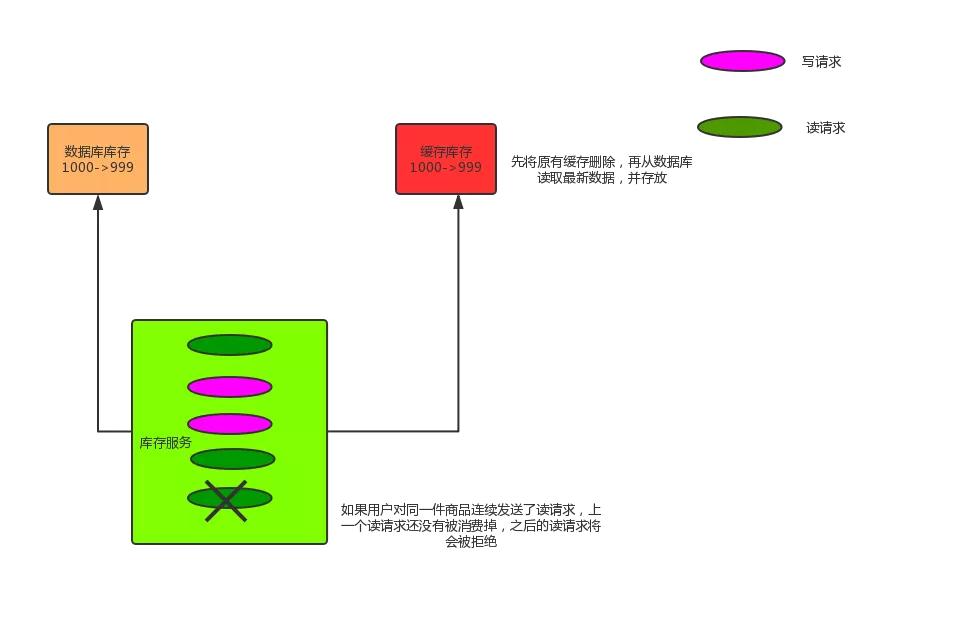
代码实现大致如下:
/**
*请求异步处理的service实现
*@authorAdministrator
*
*/
@Service("requestAsyncProcessService")
publicclassRequestAsyncProcessServiceImplimplementsRequestAsyncProcessService{
@Override
publicvoidprocess(Requestrequest){
try{
//先做读请求的去重
RequestQueuerequestQueue=RequestQueue.getInstance();
Map<Integer,Boolean>flagMap=requestQueue.getFlagMap();
if(requestinstanceofProductInventoryDBUpdateRequest){
//如果是一个更新数据库的请求,那么就将那个productId对应的标识设置为true
flagMap.put(request.getProductId(),true);
}elseif(requestinstanceofProductInventoryCacheRefreshRequest){
Booleanflag=flagMap.get(request.getProductId());
//如果flag是null
if(flag==null){
flagMap.put(request.getProductId(),false);
}
//如果是缓存刷新的请求,那么就判断,如果标识不为空,而且是true,就说明之前有一个这个商品的数据库更新请求
if(flag!=null&&flag){
flagMap.put(request.getProductId(),false);
}
//如果是缓存刷新的请求,而且发现标识不为空,但是标识是false
//说明前面已经有一个数据库更新请求+一个缓存刷新请求了,大家想一想
if(flag!=null&&!flag){
//对于这种读请求,直接就过滤掉,不要放到后面的内存队列里面去了
return;
}
}
//做请求的路由,根据每个请求的商品id,路由到对应的内存队列中去
ArrayBlockingQueue<Request>queue=getRoutingQueue(request.getProductId());
//将请求放入对应的队列中,完成路由操作
queue.put(request);
}catch(Exceptione){
e.printStackTrace();
}
}
/**
*获取路由到的内存队列
*@paramproductId商品id
*@return内存队列
*/
privateArrayBlockingQueue<Request>getRoutingQueue(IntegerproductId){
RequestQueuerequestQueue=RequestQueue.getInstance();
//先获取productId的hash值
Stringkey=String.valueOf(productId);
inth;
inthash=(key==null)?0:(h=key.hashCode())^(h>>>16);
//对hash值取模,将hash值路由到指定的内存队列中,比如内存队列大小8
//用内存队列的数量对hash值取模之后,结果一定是在0~7之间
//所以任何一个商品id都会被固定路由到同样的一个内存队列中去的
intindex=(requestQueue.queueSize()-1)&hash;
System.out.println("===========日志===========:路由内存队列,商品id="+productId+",队列索引="+index);
returnrequestQueue.getQueue(index);
}
}
Cache Aside Pattern
下面我们来聊聊经典的缓存+数据库读写的模式,就是 Cache Aside Pattern。
读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。更新的时候,先更新数据库,然后再删除缓存。
为什么是删除缓存,而不是更新缓存?原因很简单,很多时候,在复杂点的缓存场景,缓存不单单是数据库中直接取出来的值。
比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据并进行运算,才能计算出缓存最新的值的。
另外更新缓存的代价有时候是很高的,是不是每次修改数据库的时候,都一定要将其对应的缓存更新一份?
也许有的场景是这样,但是对于比较复杂的缓存数据计算的场景,就不是这样了。
如果你频繁修改一个缓存涉及的多个表,缓存也频繁更新。但是问题在于,这个缓存到底会不会被频繁访问到?
举个栗子,一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次、100 次。
但是这个缓存在 1 分钟内只被读取了 1 次,有大量的冷数据。实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低,用到缓存才去算缓存。
其实删除缓存,而不是更新缓存,就是一个 Lazy 计算的思想,不要每次都重新做复杂的计算,不管它会不会用到,而是让它到需要被使用的时候再重新计算。
像 Mybatis,Hibernate,都有懒加载思想,查询一个部门,部门带了一个员工的 List,没有必要说每次查询部门,都把里面的 1000 个员工的数据也同时查出来。
80% 的情况,查这个部门,就只是要访问这个部门的信息就可以了,先查部门,同时要访问里面的员工,那么这时只有在你要访问里面的员工的时候,才会去数据库里面查询 1000 个员工。
最初级的缓存不一致问题及解决方案
问题:先修改数据库,再删除缓存。如果删除缓存失败了,那么会导致数据库中是新数据,缓存中是旧数据,数据就出现了不一致。
解决思路:先删除缓存,再修改数据库。如果数据库修改失败了,那么数据库中是旧数据,缓存中是空的,那么数据不会不一致。
因为读的时候缓存没有,则读数据库中旧数据,然后更新到缓存中。
比较复杂的数据不一致问题分析
数据发生了变更,先删除了缓存,然后要去修改数据库。
但是还没来得及修改,一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中。
随后数据变更的程序完成了数据库的修改。完了,数据库和缓存中的数据不一样了。
为什么上亿流量高并发场景下,缓存会出现这个问题?只有在对一个数据在并发的进行读写的时候,才可能会出现这种问题。
如果说你的并发量很低的话,特别是读并发很低,每天访问量就 1 万次,那么很少的情况下,会出现刚才描述的那种不一致的场景。
但是问题是,如果每天的是上亿的流量,每秒并发读是几万,每秒只要有数据更新的请求,就可能会出现上述的数据库+缓存不一致的情况。
解决方案如下:更新数据的时候,根据数据的唯一标识,将操作路由之后,发送到一个 JVM 内部队列中。
读取数据的时候,如果发现数据不在缓存中,那么将重新读取数据+更新缓存的操作,根据唯一标识路由之后,也发送同一个 JVM 内部队列中。
一个队列对应一个工作线程,每个工作线程串行拿到对应的操作,然后一条一条的执行。
这样的话,一个数据变更的操作,先删除缓存,然后再去更新数据库,但是还没完成更新。
此时如果一个读请求过来,读到了空的缓存,那么可以先将缓存更新的请求发送到队列中,此时会在队列中积压,然后同步等待缓存更新完成。
这里有一个优化点,一个队列中,其实多个更新缓存请求串在一起是没意义的,因此可以做过滤。
如果发现队列中已经有一个更新缓存的请求了,那么就不用再放个更新请求操作进去了,直接等待前面的更新操作请求完成即可。
待那个队列对应的工作线程完成了上一个操作的数据库的修改之后,才会去执行下一个操作,也就是缓存更新的操作,此时会从数据库中读取最新的值,然后写入缓存中。
如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回;如果请求等待的时间超过一定时长,那么这一次直接从数据库中读取当前的旧值。
高并发的场景下,该解决方案要注意的问题:
读请求长时阻塞
由于读请求进行了非常轻度的异步化,所以一定要注意读超时的问题,每个读请求必须在超时时间范围内返回。
该解决方案,最大的风险点在于,可能数据更新很频繁,导致队列中积压了大量更新操作在里面,然后读请求会发生大量的超时,最后导致大量的请求直接走数据库。
所以务必通过一些模拟真实的测试,看看更新数据的频率是怎样的。
另外一点,因为一个队列中,可能会积压针对多个数据项的更新操作,因此需要根据自己的业务情况进行测试,可能需要部署多个服务,每个服务分摊一些数据的更新操作。
如果一个内存队列里积压 100 个商品的库存修改操作,每个库存修改操作要耗费 10ms 去完成。
那么最后一个商品的读请求,可能等待 10*100=1000ms=1s 后,才能得到数据,这个时候就导致读请求的长时阻塞。
因此,一定要根据实际业务系统的运行情况,去进行一些压力测试和模拟线上环境,去看看最繁忙的时候,内存队列可能会积压多少更新操作,可能会导致最后一个更新操作对应的读请求,会 Hang 多少时间。
如果读请求在 200ms 返回,如果你计算过后,哪怕是最繁忙的时候,积压 10 个更新操作,最多等待 200ms,那还可以的。
如果一个内存队列中可能积压的更新操作特别多,那么你就要加机器,让每个机器上部署的服务实例处理更少的数据,那么每个内存队列中积压的更新操作就会越少。
根据之前的项目经验,一般来说,数据的写频率是很低的,因此实际上正常来说,在队列中积压的更新操作应该是很少的。
像这种针对读高并发、读缓存架构的项目,一般来说写请求是非常少的,每秒的 QPS 能到几百就不错了。
实际粗略测算一下,如果一秒有 500 的写操作,分成 5 个时间片,每 200ms 就 100 个写操作,放到 20 个内存队列中,每个内存队列,可能就积压 5 个写操作。
每个写操作性能测试后,一般是在 20ms 左右就完成,那么针对每个内存队列的数据的读请求,也就最多 Hang 一会儿,200ms 以内肯定能返回了。
经过刚才简单的测算,我们知道,单机支撑的写 QPS 在几百是没问题的,如果写 QPS 扩大了 10 倍,那么就扩容机器,扩容 10 倍的机器,每个机器 20 个队列。
读请求并发量过高
这里还必须做好压力测试,确保恰巧碰上上述情况时,还有一个风险,就是突然间大量读请求会在几十毫秒的延时 Hang 在服务上,看服务能不能扛的住,需要多少机器才能扛住最大的极限情况的峰值。
但是因为并不是所有的数据都在同一时间更新,缓存也不会同一时间失效,所以每次可能也就是少数数据的缓存失效了,然后那些数据对应的读请求过来,并发量应该也不会特别大。
多服务实例部署的请求路由
可能这个服务部署了多个实例,那么必须保证说,执行数据更新操作,以及执行缓存更新操作的请求,都通过 Nginx 服务器路由到相同的服务实例上。
比如对同一个商品的读写请求,全部路由到同一台机器上。可以自己去做服务间的按照某个请求参数的 Hash 路由,也可以用 Nginx 的 Hash 路由功能等等。
热点商品路由问题导致请求倾斜
万一某个商品的读写请求特别高,全部打到相同的机器的相同的队列里面去了,可能会造成某台机器的压力过大。
因为只有在商品数据更新的时候才会清空缓存,然后才会导致读写并发,所以要根据业务系统去看,如果更新频率不是太高的话,这个问题的影响并不是特别大,但是可能某些机器的负载会高一些。

转载请注明:IT运维空间 » 运维技术 » 亿级流量高并发下,缓存与数据库不一致,咋办?
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-
oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值













发表评论