


深度分页引发的机器性能问题
最近碰到一个ElasticSearch深度分页搜索,导致cpu占用过高问题,通过查阅ElasticSearch: 权威指南,了解到了深度分页为何会引起机器资源占用:
在集群系统中深度分页为了理解为什么深度分页是有问题的,让我们假设在一个有5个主分片的索引中搜索。当我们请求结果的第一页(结果1到10)时,每个分片产生自己最顶端10个结果然后返回它们给请求节点(requesting node),它再排序这所有的50个结果以选出顶端的10个结果。现在假设我们请求第1000页——结果10001到10010。工作方式都相同,不同的是每个分片都必须产生顶端的10010个结果。然后请求节点排序这50050个结果并丢弃50040个!你可以看到在分布式系统中,排序结果的资源和时间花费随着分页的深入而成倍增长。这也是为什么网络搜索引擎中任何语句不能返回多于1000个结果的原因。
理解以上那段文字,有必要了解ElasticSearch集群以及在集群中是查询的底层原理,本文试图通过总结ElasticSearch基本概念和底层原理,加深自身理解,同时希望对使用者有所帮助,避免不必要的踩坑。
基本概念
索引(index)
“索引” 这个词在 ElasticSearch 语境中包含多重意思: 索引(名词): 类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库。索引由其名称(必须为全小写字符)进行标识,并通过引用此名称完成文档的创建、搜索、更新及删除操作。
索引(动词): 索引一个文档就是存储一个文档到一个索引(名词)中以便它可以被检索和查询到。这非常类似于SQL语句中的 INSERT关键词,除了文档已存在时新文档会替换旧文档情况之外。
倒排索引: 关系型数据库通过增加一个“索引”比如一个B树(B-tree)索引到指定的列上,以便提升数据检索速度。ElasticSearch 和 Lucene 使用了一个叫做 “倒排索引” 的结构来达到相同的目的。
举个例子,文档和词条之间的关系如下图:
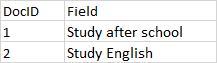
图1:文档和词条的关系
字段值被分析之后,存储在倒排索引中,倒排索引存储的是分词(Term)和文档(Doc)之间的关系,简化版的倒排索引如下图:
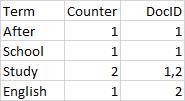
图2:倒排索引
类型(Type)
类型是索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。因此,一个索引内部可定义一个或多个类型(type)。一般来说,类型就是为那些拥有相同的域的文档做的预定义。类比传统的关系型数据库领域来说,类型相当于“表”。
文档(Document)
文档类似于一行完整的数据,在ElasticSearch里面文档是基于JSON格式进行表示的,文档是索引和搜索的原子单位,它是包含了一个或多个域(Field)的容器。每个文档可以存储不同的域集,但同一类型(Type)下的文档至少应该有某种程度上的相似之处。
节点(Node)
一个运行中的 ElasticSearch实例称为一个节点,而集群是由一个或者多个拥有相同cluster.name配置的节点组成, 它们共同承担数据和负载的压力。
ES集群中的节点有三种不同的类型:
- 主节点:负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 主节点并不需要涉及到文档级别的变更和搜索等操作。可以通过属性node.master进行设置。
- 数据节点:存储数据和其对应的倒排索引。默认每一个节点都是数据节点(包括主节点),可以通过node.data属性进行设置。
- 协调节点:如果node.master和node.data属性均为false,则此节点称为协调节点,用来响应客户请求,均衡每个节点的负载。
分片(Shard)
一个索引中的数据保存在多个分片中,相当于水平分表。一个分片便是一个Lucene 的实例,它本身就是一个完整的搜索引擎。我们的文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互。
一个分片可以是主分片或者副本分片。 索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量。一个副本分片只是一个主分片的拷贝。 副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
集群分布式底层实现
以上我们对ElasticSearch的基本概念有了一个初步认识,接下来我们深入这些内部细节来帮助你更好的理解数据是如何在分布式系统中存储和查询的。
ES实际上就是利用分片来实现分布式。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。 当你的集群规模扩大或者缩小时, ES会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里。
在索引建立的时候就已经确定了主分片数,但是副本分片数可以随时修改。默认情况下,一个索引会有5个主分片,而其副本可以有任意数量。
主分片和副本分片的状态决定了集群的健康状态。每一个节点上都只会保存主分片或者其对应的一个副本分片,相同的副本分片不会存在于同一个节点中。如果集群中只有一个节点,则副本分片将不会被分配,此时集群健康状态为yellow,存在丢失数据的风险。
分布式文档CRUD
索引新文档(Create)
当用户向一个节点提交了一个索引新文档的请求,节点会计算新文档应该加入到哪个分片(shard)中。每个节点都存储有每个分片存储在哪个节点的信息,因此协调节点会将请求发送给对应的节点。注意这个请求会发送给主分片,等主分片完成索引,会并行将请求发送到其所有副本分片,保证每个分片都持有最新数据。
每次写入新文档时,都会先写入内存中,并将这一操作写入一个translog文件(transaction log)中,此时如果执行搜索操作,这个新文档还不能被索引到。
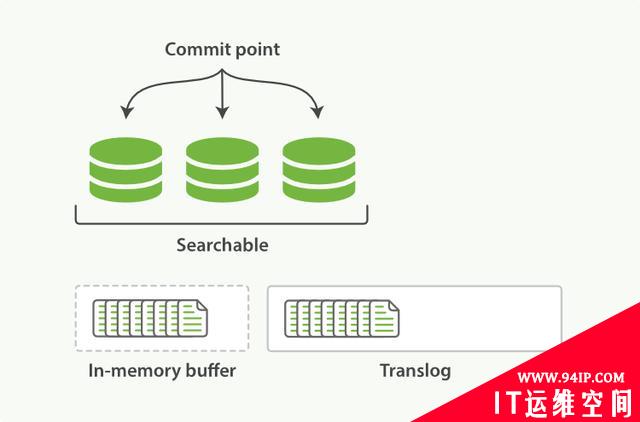
图3:新文档被写入内存,操作被写入translog
ES会每隔1秒时间(这个时间可以修改)进行一次刷新操作(refresh),此时在这1秒时间内写入内存的新文档都会被写入一个文件系统缓存(filesystem cache)中,并构成一个分段(segment)。此时这个segment里的文档可以被搜索到,但是尚未写入硬盘,即如果此时发生断电,则这些文档可能会丢失。
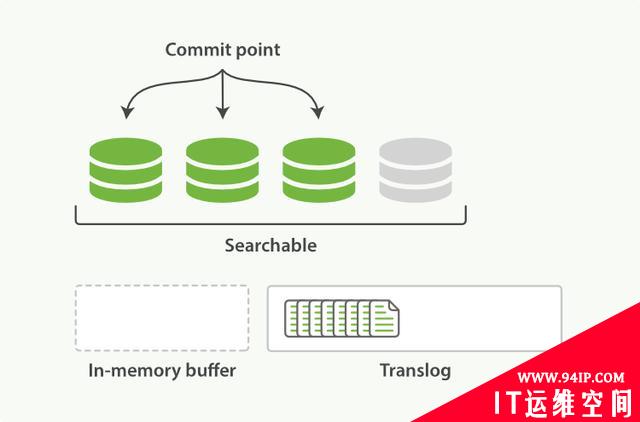
图4:在执行刷新后清空内存,新文档写入文件系统缓存
不断有新的文档写入,则这一过程将不断重复执行。每隔一秒将生成一个新的segment,而translog文件将越来越大。
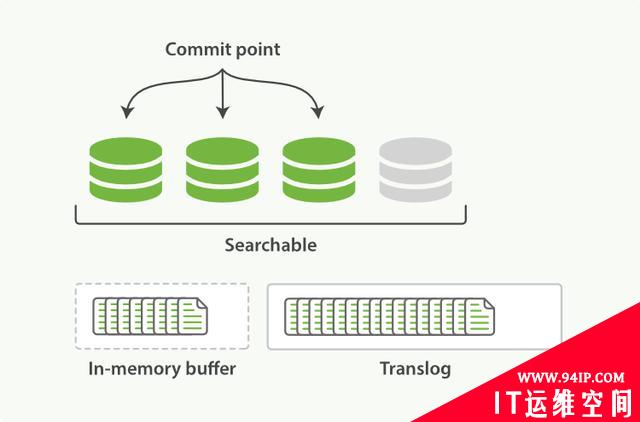
图5:translog不断加入新文档记录
每隔30分钟或者translog文件变得很大,则执行一次fsync操作。此时所有在文件系统缓存中的segment将被写入磁盘,而translog将被删除(此后会生成新的translog)。
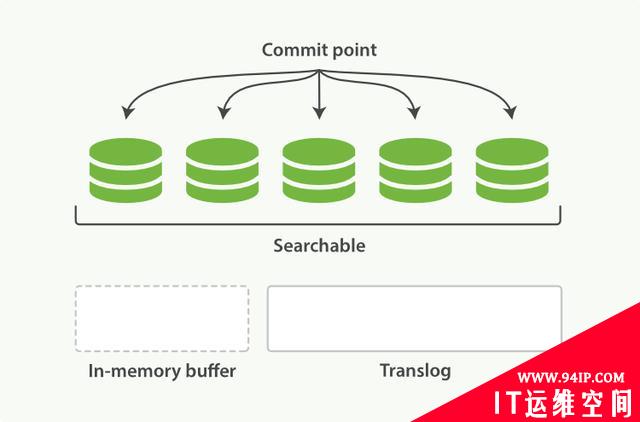
图6:执行fsync后segment写入磁盘,清空内存和translog
由上面的流程可以看出,在两次fsync操作之间,存储在内存和文件系统缓存中的文档是不安全的,一旦出现断电这些文档就会丢失。所以ES引入了translog来记录两次fsync之间所有的操作,这样机器从故障中恢复或者重新启动,ES便可以根据translog进行还原。
当然,translog本身也是文件,存在于内存当中,如果发生断电一样会丢失。因此,ES会在每隔5秒时间或是一次写入请求完成后将translog写入磁盘。可以认为一个对文档的操作一旦写入磁盘便是安全的可以复原的,因此只有在当前操作记录被写入磁盘,ES才会将操作成功的结果返回发送此操作请求的客户端。
此外,由于每一秒就会生成一个新的segment,很快将会有大量的segment。对于一个分片进行查询请求,将会轮流查询分片中的所有segment,这将降低搜索的效率。因此ES会自动启动合并segment的工作,将一部分相似大小的segment合并成一个新的大segment。合并的过程实际上是创建了一个新的segment,当新segment被写入磁盘,所有被合并的旧segment被清除。
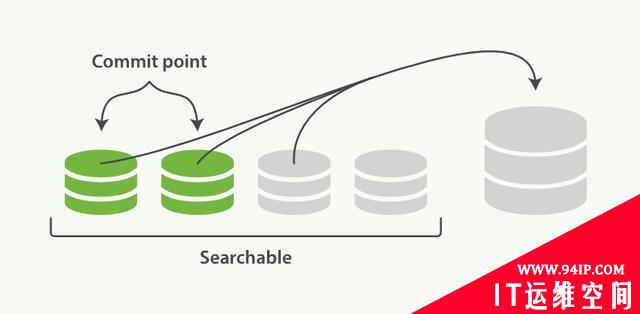
图7:合并segment
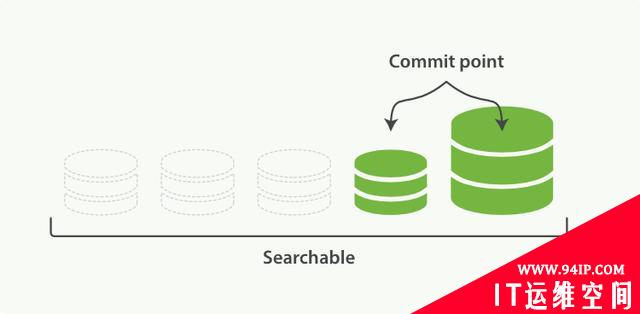
图8:合并完成后删除旧segment,新segment可供搜索
更新(Update)和删除(Delete)文档
ES的索引是不能修改的,因此更新和删除操作并不是直接在原索引上直接执行。
每一个磁盘上的segment都会维护一个del文件,用来记录被删除的文件。每当用户提出一个删除请求,文档并没有被真正删除,索引也没有发生改变,而是在del文件中标记该文档已被删除。因此,被删除的文档依然可以被检索到,只是在返回检索结果时被过滤掉了。每次在启动segment合并工作时,那些被标记为删除的文档才会被真正删除。
更新文档会首先查找原文档,得到该文档的版本号。然后将修改后的文档写入内存,此过程与写入一个新文档相同。同时,旧版本文档被标记为删除,同理,该文档可以被搜索到,只是最终被过滤掉。
读操作(Read):查询过程
查询的过程大体上分为查询(query)和取回(fetch)两个阶段。这个节点的任务是广播查询请求到所有相关分片,并将它们的响应整合成全局排序后的结果集合,这个结果集合会返回给客户端。
查询阶段
当一个节点接收到一个搜索请求,则这个节点就变成了协调节点。
查询过程分布式搜索
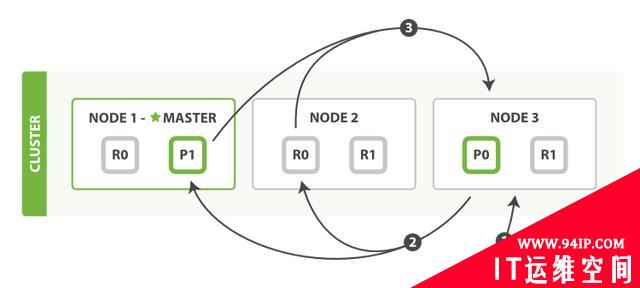
图9:查询过程分布式搜索
第一步是广播请求到索引中每一个节点的分片拷贝。 查询请求可以被某个主分片或某个副本分片处理,协调节点将在之后的请求中轮询所有的分片拷贝来分摊负载。
每个分片将会在本地构建一个优先级队列。如果客户端要求返回结果排序中从第from名开始的数量为size的结果集,则每个节点都需要生成一个from+size大小的结果集,因此优先级队列的大小也是from+size。分片仅会返回一个轻量级的结果给协调节点,包含结果集中的每一个文档的ID和进行排序所需要的信息。
协调节点会将所有分片的结果汇总,并进行全局排序,得到最终的查询排序结果。此时查询阶段结束。
取回阶段
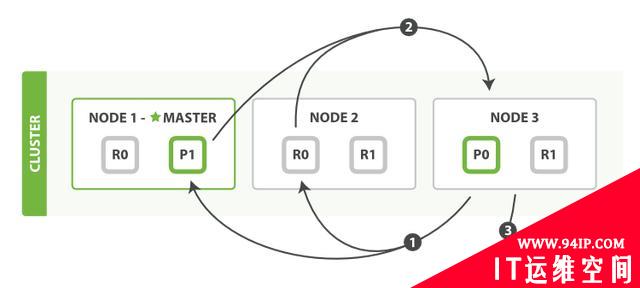
查询过程得到的是一个排序结果,标记出哪些文档是符合搜索要求的,此时仍然需要获取这些文档返回客户端。
协调节点会确定实际需要返回的文档,并向含有该文档的分片发送get请求;分片获取文档返回给协调节点;协调节点将结果返回给客户端
作者:张勇
http://tech.dianwoda.com/
转载请注明:IT运维空间 » 运维技术 » ElasticSearch的基本概念和集群分布式底层实现
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/8.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值












发表评论