


分布式架构可能是近几年最火的话题。从集中式、SOA到分布式架构,本文回顾了这些年金融行业经历的架构演变;结合当下一些较典型的分布式数据库的实现原理,分析了分布式数据库的三个发展阶段。分布式数据库的应用解决了传统数据库性能扩展问题的同时,也给运维人员带来了挑战。那么,分布式数据库的管理究竟多了些什么?如何管理好?未来数据库和数据库运维又将去往何方?读过本文,你可以找到答案。
一、金融行业这些年经历了怎样的架构演变?
1. 集中式架构
分布式架构可能是近几年最火的话题,与之相对的则是集中式架构,后者是传统金融行业如银行最常见的部署架构。在“去IOE”之前,各大银行的目标还停留在将集中式单点做强做大,不少银行采用IBM的主机系统就是鲜明的例子。数据库服务器更是如此,通常都是采用最好的机器。
近几年,随着银行业务增长,互联网行业爆发,用户行为模式发生变化,集中式架构的系统面临很大的挑战。问题主要体现在扩展性和可用性这两方面:
1. 扩展性
集中式架构的横向水平扩展能力非常低。面对性能不足,用户能做的就是加CPU、加内存、换存储、换机器等方式。
2. 可用性
集中式架构的服务能力依赖高性能的主机。然而一旦主机出现故障,上面的服务就会受到影响。应对这个问题的方案就是搭建高可用架构。每一个环节都需要考虑冗余和HA。集中式架构下这几乎是最好的方式了。然而无论哪个环节出故障,影响的都是全局服务。
这种架构下的数据库也是通过做主备机冗余,HA服务自动管理切换满足高可用性。性能方面通常也是采用纵向扩容的方式。然而纵向扩容是有限制的。如果最强的主机都搞不定了怎么办?
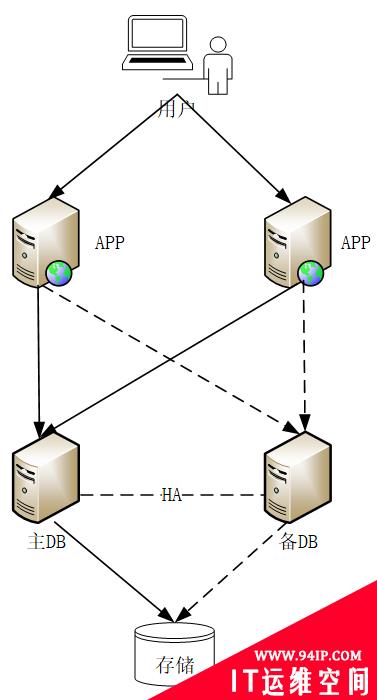
图 1. 集中式架构
在集中式架构的数据库里面有一个例外,那就是MPP数据库。为了解决单节点数据库性能上限问题,某些数据库厂商开发出来MPP数据库。这种数据库算是一套集群,数据分布在这些集群的节点上,数据查询服务也能下推到这些节点完成。通过数据分发和功能分发,充分利用多节点的处理能力,这简直就是现在的分布式先驱。
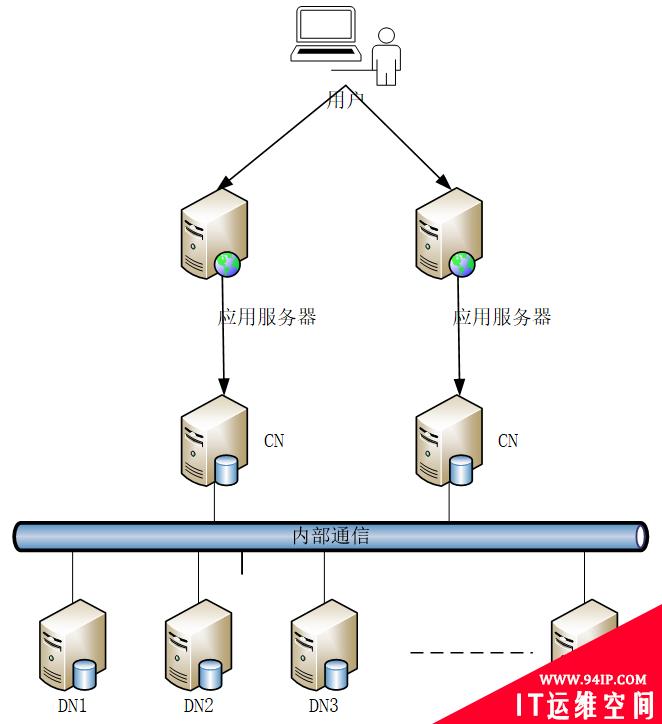
图 2. 集中式MPP架构
图中协调节点CN并非是一个特殊组件,这可以是任何一个DN。不过这类产品是面向OLAP的,是为了解决大查询问题,和现在分布式的方向并不一样。
2. 面向服务的架构(SOA)
在互联网浪潮还没到来,分布式架构还未兴起的时候,为了解决单机性能瓶颈和全局服务可用性问题,最初的方案是业务拆分,也就是面向服务的架构(SOA)开始应用起来。纯粹的SOA其实是一个组件模型,它将应用程序的不同功能单元(称为服务)进行拆分,并通过这些服务之间定义良好的接口和协议联系起来。SOA架构曾经流行了一段时间,当然现在更火的是微服务模式。
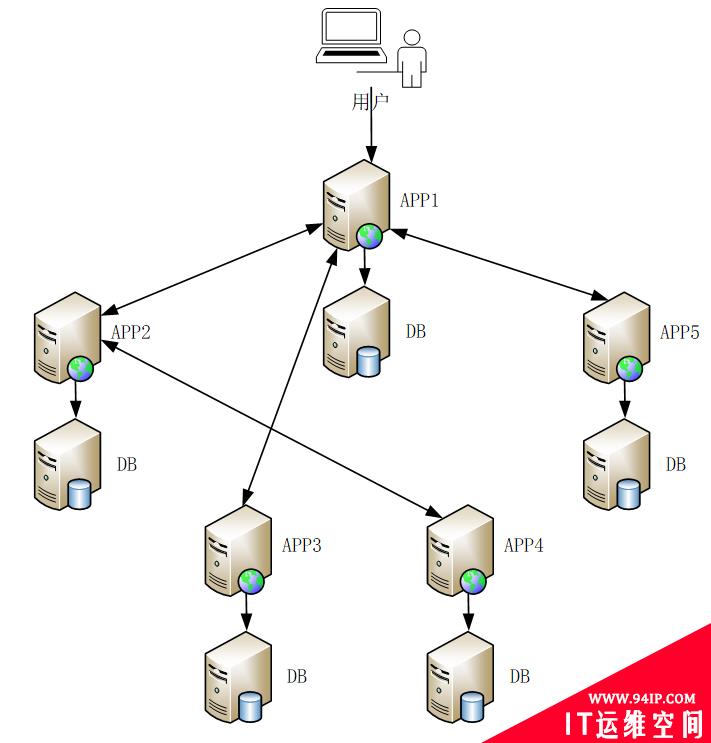
图 3. SOA架构
当时有很多银行将自己的核心系统依照这个思路拆分,一个大系统拆成多个小系统或者是组件。优点是服务拆分之后实现了部分性能扩展。之所以说是部分,是因为总有些核心服务是热点,没有办法做到拆分的。随之带来的缺点是系统调用链复杂程度增加了,数据在不同服务间的同步要求变多变复杂,然后系统和服务器的数量增多了。即便是采用了SOA的思路,还是没有彻底解决热点功能的性能问题和可用性问题:
1. 没有实现核心功能的水平扩展,单个功能还是属于集中式架构部署。
2. 没有实现数据水平拆分,解决不了大数据量的问题,反而带来了不同系统数据同步的复杂需求。
3. 分布式架构
就在金融行业还在忙着为系统功能拆分改造,给新的小机打预算的同时,中国的互联网科技行业正在发生大的变革。
大数据技术发展:第一大变革是各种分布式开源软件走向成熟并被充分利用。分布式存储、分布式计算、分布式消息中间件引领大数据行业变革。这些分布式技术简单粗暴的解决了大数据量、高吞吐量和高可用性的难题。这些难题对业务系统和后台的数据库同样存在。看起来数据库走向分布式才是终极解决方案。然数据库行业的领先者们并没有像拥抱云技术那样去拥抱分布式数据库,反而给了众多初创数据库企业机会。
互联网消费行为:另外一大变革是互联网行业改变了用户的消费行为。这几年网络运营商在提速降费,互联网移动设备出货量飙升,用户的消费习惯也大量从线下转移到线上。中国的人口红利在互联网产业发挥的淋漓尽致。对于金融行业来说,用户消费行为的变化带来的是对金融科技的挑战。交易量和数据量都在不停攀升高峰。尤其是网银,手机银行等渠道类业务都将面临集中式架构性能瓶颈问题。
其中最典型的就是阿里。阿里从2011年开始基于成本因素的考虑逐步去IOE,同时年年祭出了双十一成绩单。高帅富的小机替换成了PC机,Oracle数据库换成了开源MySQL数据库,同时自研分布式中间件TDDL实现横向扩展。阿里通过堆砌廉价的PC机来支撑庞大的双十一促销业务,最终交出了交易量、峰值、金额等漂亮的成绩单。现在阿里的分布式中间件发展成了关系型数据库 DRDS。同时阿里还有面向金融领域全自研内核的OceanBase,主打云数据库存储计算分离架构的PolarDB。
技术自主可控:这几年国际关系大环境也在发生变化,国内寻求自主可控的声音越来越响。相应的国内也涌现出了很多主打数据库产品和服务的企业。尤其是分布式数据库技术,在国际数据库领头羊们还没有全力投入拿出作品的时候,国内很多企业借鉴开源分布式技术方案,研发出了自己的分布式数据库。因为没有作业可抄,所以大家做的作业也很不一样。
综上所述,内有金融行业对于大数据量、高吞吐量和高可用性的迫切需求以及自主可控的需求,外有大数据分布式技术方案得到肯定,再加上互联网行业解决方案引领,金融行业对国内优秀的分布式数据库的需求持续走强。
二、分布式数据库经历了哪几个发展阶段?
分布式数据库是为了解决大数据量、高吞吐量和高可用性的问题,通过数据和计算分片的方式提供横向扩展能力。然而思路很明确,实现很复杂。为了更清楚当前一些分布式数据库的实现原理,我们首先将要数据库分为三层来看待:解析层,计算层,存储层。而分布式的实现就是在解决这几层的实现问题。我把分布式数据库的发展分为三个阶段。
1. 读写分离
为了解决集中式架构下的单节点计算性能问题,首先出现的方案是读写分离模式。当时MySQL开源数据库比较流行。然而MySQL单节点的处理性能很容易遇到瓶颈。MySQL主从复制的架构下,主库可读写,然而备库建议只读。因此如果SQL解析层能够做到读写分离,那么主库的压力将会大大降低。
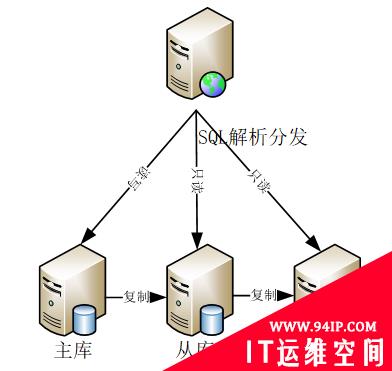
图 4. 读写分离架构
这种架构曾经流行一段时间,这个阶段MySQL发展势头也很迅猛,开始挑战商业数据库的地位。商业数据库的用户也向IBM和Oracle等提出了相关的需求。这种架构下每个数据节点的数据是全量的。客户端或者是数据库中间件需要解决SQL的读写分发问题:如何保证数据一致性,如何设计SQL的隔离级别,如何解决锁问题等等。
- 解析层
解析层需要实现读写分发。
- 计算层
实现了从库接受读交易,一定程度分散了压力。
- 存储层
单节点是全量数据。数据同步通过数据库的主从复制技术实现。
如果存储计算分离,然后实现分布式存储。那么这种架构又可以进一步解决存储层的压力问题。现在最典型的是阿里云的polardb。
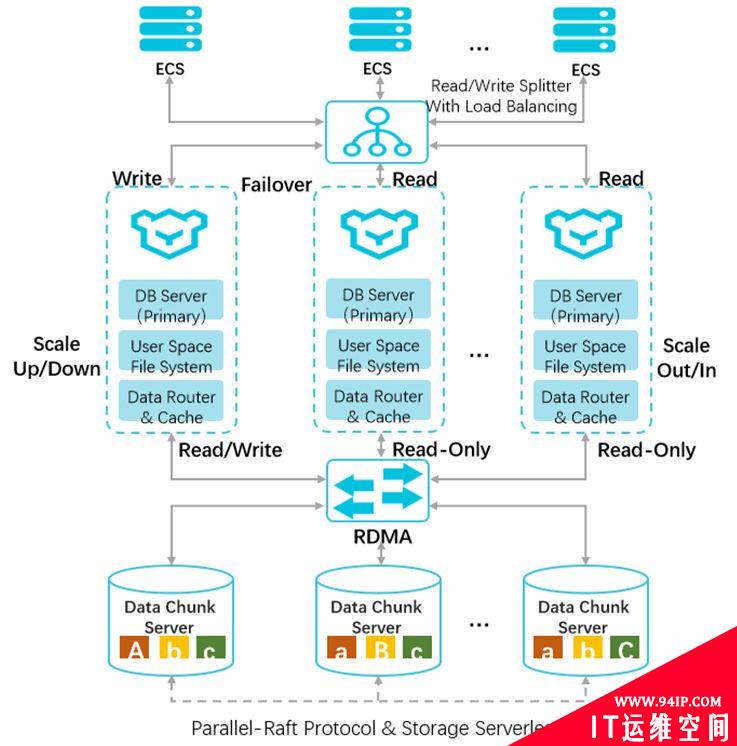
图 5. 阿里云polardb分布式存储
阿里云的polardb实现远远比简单的读写分离要丰富的多。首先这是个面向云的原生数据库,是属于软硬一体的解决方案。
- 解析层
实现读写分离和负载均衡。
- 计算层
纵向扩展单节点性能,横向扩展读性能。
- 存储层
分布式存储,分片方式对应用透明。通过FPGA,RDMA等硬件技术加速性能。
个人认为云数据库是未来的趋势,阿里polardb和腾讯tdsql会大放异彩。
2. 分布式中间件模式
读写分离还是不能满足中国互联网庞大的用户体量。银行有几千万上亿的用户,互联网更多。但凡来个促销活动,运维人员就心惊肉跳。仅仅靠读写分离其实不能满足这种集中并发式的性能瓶颈。那么能不能将这些用户的交易数据分开放在不同的节点上,让这些用户只在对应的节点处理数据呢?这就是现在分布式的主流思路:数据分片。
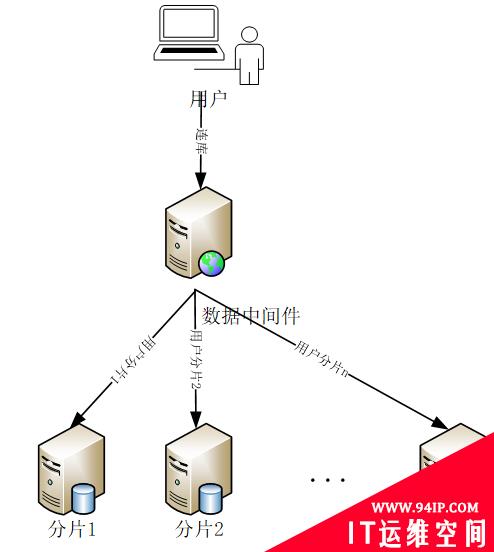
图 6. 数据库中间件
图中的每个分片都可以是一套主从架构的数据库,不仅仅是一个物理节点。
- 解析层
实现sql分发查询以及结果汇聚。数据分片的定义需要在这一层保存。对于跨节点的分布式事务支持能力很单薄。这个主要看分布式中间件的产品能力。
- 计算层
通过底层数据的分片,计算层已经完全实现了负载分离。
- 存储层
数据分片后,存储层的性能问题也完美解决。
这种架构的典型代表是阿里最初的TDDL数据库中间件产品和开源数据库中间件Mycat。阿里的TDDL数据库中间件已经演变成现在的DRDS集群。
首先我们来看看Mycat的解决方案。
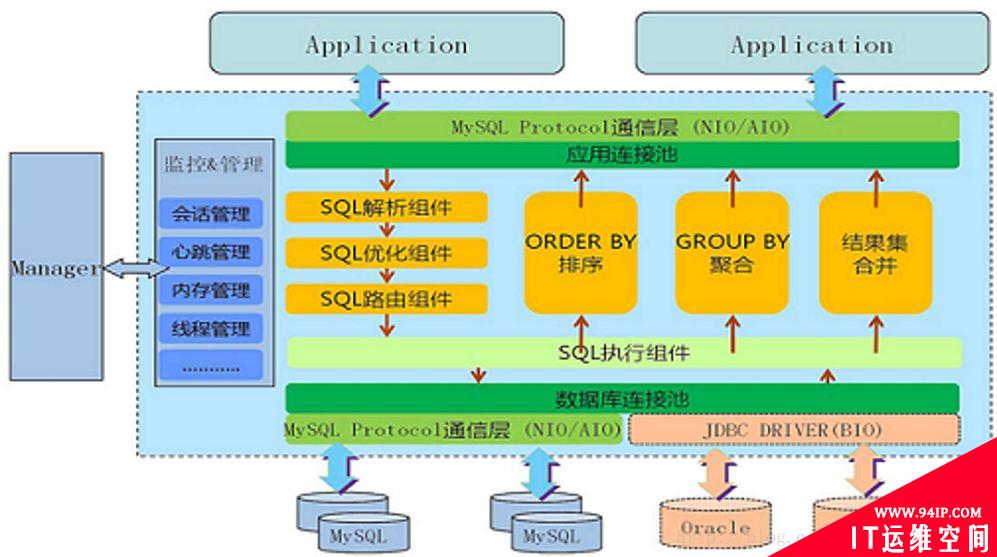
图 7. Mycat数据库中间件
Mycat数据库中间件架设在应用和底层数据库之间。应用SQL会解析转化并路由到底层多个数据库主备集群里。这种方案不需要底层数据库做任何改动。然而支持复杂SQL的能力有限。使用这种架构要避免分布式事务。
下面看看阿里云的DRDS解决方案。DRDS虽然是中间件模式,不过现在推出的解决方案更像是个完整的分布式集群数据库。DRDS是分布式中间件,底层是RDS数据库集群(mysql)。RDS数据库服务是阿里云提供的关系型数据库服务统称,主要是MySQL。DRDS通过两阶段提交来实现分布式事务。
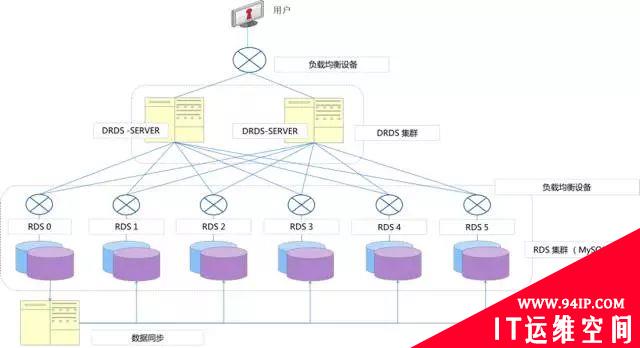
图 8. 阿里云DRDS
如果存在分布式的事务,那么在这种架构下最好由应用层面去解决。这方面我觉得做的最好的是招商银行。招行一开始就将分布式事务和分片的角色都放在业务应用开发层面,因此不需要依赖底层数据库来实现分库分表。
3. 分布式集群模式
中间件模式其实还是和数据库引擎脱离的。分布式中间件如果将中间件和底层数据库揉在一起,当做一个产品去开发使用,这就是现在的分布式集群数据库。我观察了国内各家厂商分布式数据库的实现,基本浓缩成下面这张示意图。
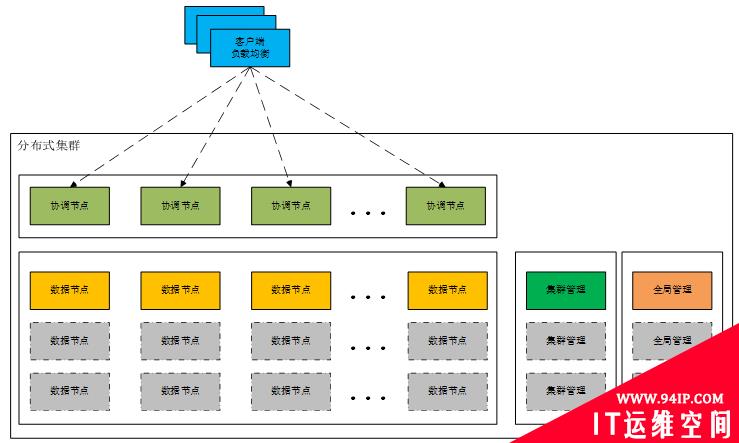
图 9. 分布式数据库集群
协调节点:这是分布式数据库接受用户请求和返回数据的处理节点,通常以多活的模式部署在多个物理节点上。协调节点之间的事务控制通过向全局管理节点请求,获取全局事务信息或者锁信息。协调节点的SQL会编译执行,调取对应的数据节点。
数据节点:真正存放数据的地方。从协调节点导入的数据通过分片或者复制的方式存放在数据节点里面。数据节点通常只需要响应协调节点的调取。数据节点通过一主多备的模式提高数据可用性。备节点一般不提供读取服务。
全局管理节点:分布式数据库的核心,也是区别于分布式中间件方案的关键组件。全局管理节点用于全局事务控制、元数据管理等。这些需要全局控制的功能可能会被拆分成多个组件来部署,这也是不同分布式数据库集群的根本差异。
集群管理节点:这是数据库集群高可用性的保证。用于全局监控数据库各项组件的状态,并且依据状态变化自动响应。集群管理节点控制着整个集群里组件的切换和维护。
上述逻辑节点可以在物理节点上混部署,加上数据中心的概念。集群可以跨多中心部署实现数据中心级的容灾。国内现在比较突出分布式数据库gaussT、TIDB、glodendb、sequoiadb、antdb等都是这类架构。下面看两个典型的国产化数据案例,与大部分分布式数据库的解决方案不一样的是,他们的数据库引擎不是基于MySQL。
第一个是华为的高斯数据库gaussT。
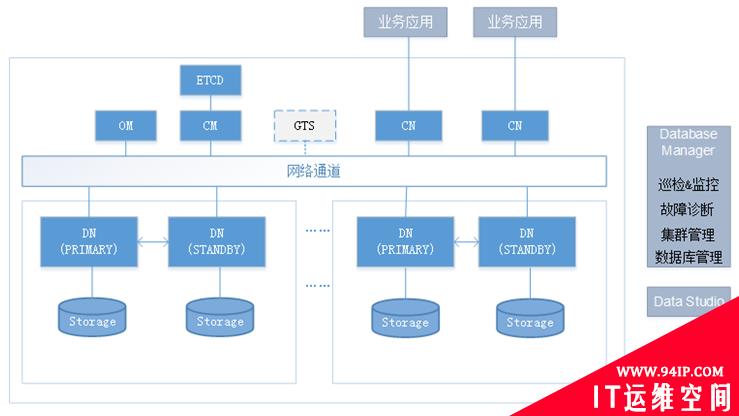
图 10. 华为gaussT数据库
这是华为官方的高斯数据库。其中ETCD和CM是集群管理器,用来选择和操作整个集群。其中ETCD存放集群整体状态信息,基于paxos协议保证可用性。CN是接受用户请求的协调节点,负责数据和SQL的分发和汇总。CN多活,客户端通过负载均衡模式连接CN。GTS是全局事务管理节点,仅处理事务号的请求并且有缓存机制,因此相对处理性能比较高。DN是数据节点,一主多备模式保证高可用。集群内部的表有两种方式建立,一种是选好分布键的分片数据表,一种是全局同步复制的复制表。从高斯数据库的架构来说,它是典型的传统关系型数据库的升华版:全面支持分布式事务,集群当做一个数据库来用的方式对用户友好。
说到分布式数据库也要提到TIDB。TIDB是PingCAP公司推出的开源分布式数据库。在一帮做分布式数据库的厂家中,TIDB是个另类,另辟蹊径主打先进的数据库架构和良好的开源生态。
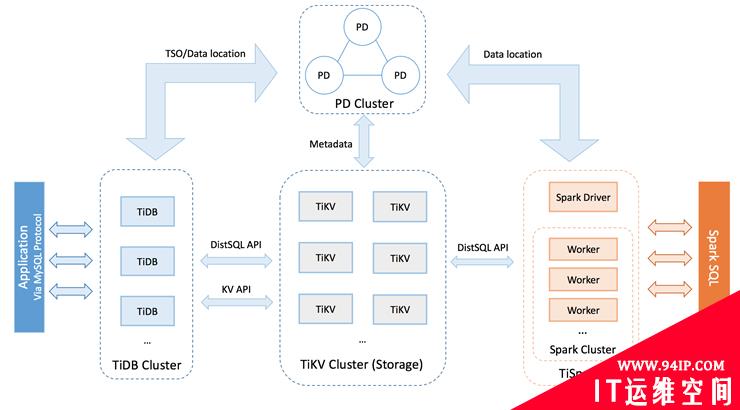
图 11. TIDB数据库
在TIDB的架构图里,TiDB Cluster是接受请求的协调节点,用作SQL解析和转发。TiKV是存放数据的数据节点。与其他分布式数据库不同的是TIDB用的是分布式的KV存储引擎。TIDB的数据分发也和其他分布式数据库必须指定分区键分片规则不同,实现的是基于Region级别的raft复制,还可以根据负载情况进行合并和分裂。这个特点是其他分布式数据库做不到的。PD Cluster相当于是全局事务管理器。集群管理器在图中没有标出来,其实里面的每个cluster都有相应的集群服务。
三种分布式方案已经介绍差不多了,最后来看看中兴Goldendb吧。
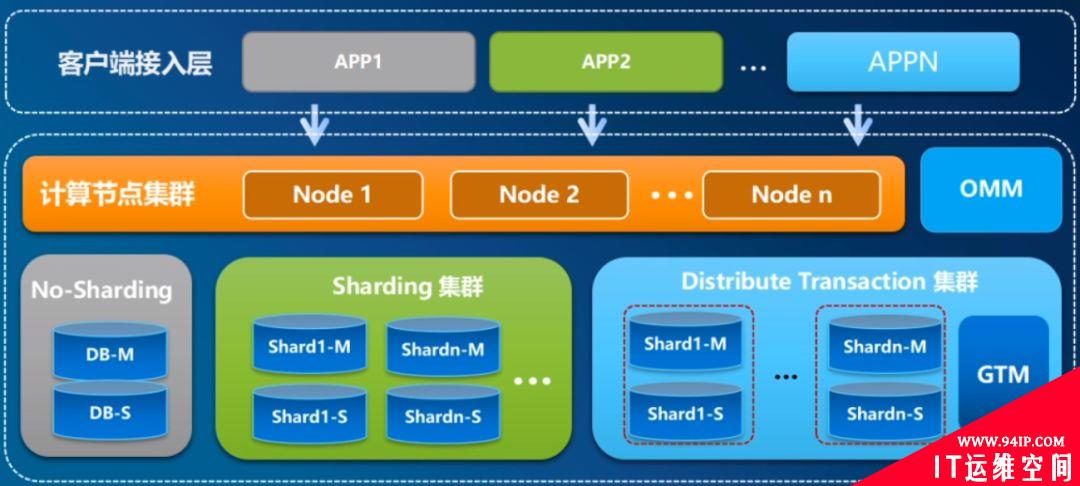
图 12. GoldenDB三种部署形态
中兴Goldendb将这三种部署形态全部集成。No-Sharding就是单机部署一主多备模式,提供读写分离的负载方案。Sharding集群就是中间件部署模式,计算节点做转发,不支持分布式事务。Distribute Transaction集群就是加了GTM全局事务管理器,支持分布式事务。
4. 分布式数据库测试体会
介绍了这么多分布式数据库架构,我们也测试了很多家的数据库产品。这里谈谈银行在测试分布式过程中的一些经验:
1. 对于单点数据的增删改查,大家的性能都很好,极限瓶颈一般出现在全局事务管理这个环节。因此这部分的性能差异就在于这个全局事务的处理问题上。这也决定了一个分布式数据库的性能上限。
2. 对于分布式事务,需要跨节点数据访问的,大家的性能都不怎么好。其实分布式事务对于分布式数据库来说还是有很大挑战的。对于使用分布式数据库的业务,建议减少分布式事务,也不要把分布式数据库当做混合负载来用。尤其是像不同分布键的大表关联,搞垮协调节点是分分钟的。这部分技术还是面向数仓的MPP数据库比较合适。如果MPP数据库的这部分能力被集成到分布式数据库中,那这个分布式数据库才真是厉害了,从容面对HTAP。
3. 使用分布式数据库一定要关注分布键。无论是分片还是复制,业务开发人员需要从自己的业务逻辑开发,合理设置。一旦选不好,分布式数据库还不如单节点性能。
4. 分布式数据库数据重分布,也就是横向扩展,都是痛点。无论是操作方式还是性能影响,基本上所有的分布式数据库都成问题。可能使用自动分布可扩展的存储引擎才是最终解决方案。
5. 分布式数据库集群组件众多,相对来说管理比较复杂。每个组件都有自己的日志,都可能有性能瓶颈。在分布式数据库环境下运维管理成本比较高。
三、传统数据库运维岗面临哪些挑战?
分布式数据库的应用解决了传统数据库性能扩展问题的同时,也给运维人员带来了挑战。以前一套标准就可以运维好传统数据库,定好参数规则,做好应急防护即可。现在多了分布式数据库,并不只是多了个数据库产品那么简单,而是多了种数据库的使用方式。
1. 分布式数据库管理多了什么?
统一数据视图:分布式数据库数据做了分片之后,运维人员需要解决数据透视的问题。哪些表是分片表,哪些表是复制表?如果需要导出或者同步数据到其他系统,这个方案该怎么做?一张表被分成了多少份,整体的数据量是多少?如果选择了分布式数据库成熟产品还好,这些部分有产品级的解决方案。中间件型的分布式就更难了。对于用户来说,如果还能将集群里的数据当做一个数据库来操作是最理想的。
大量节点管理:选择分布式,就是选择横向扩展。相应的运维节点数量会出现爆发式增长。这个运维力量一下子就上去了。还好需要上分布式的系统不会太多。现在这些节点不仅都需要单独监控管理,还需要管理好节点的角色。
容量管理:这里的容量管理包含性能和数据两个方面。在分布式环境下一定要关注负载分布问题。因为从根本上来说分布式就是为了解决性能负载而诞生的。运维人员需要检测到负载是否均衡,是否符合预期,如果有问题,需要从数据分布和业务行为的角度一起去分析。这相对是比较复杂和困难的。另一方面,分布式数据库里面最怕出现数据倾斜问题。严重的数据倾斜会导致性能瓶颈和容量瓶颈。出现倾斜后如何数据重分布也是很难的问题。
数据一致性:分布式数据库的数据一致性可能会被用户忽略。因为在集中式数据库中很少会出现这种问题。然而分布式数据库的分布式事务基本都是通过两阶段提交的方式来实现。出现问题的情况下可能会出现提交残留。因此用户需要定时检查数据库是否存在两阶段提交残留,定时比对数据。
变更管理:分布式环境下的变更问题也需要重视。节点变多了,数据库拆散了,变更也就存在全局和单点的维度。如何统一变更保证集群所有机器都完成而没有遗漏?是不是所有的节点都变更了?能不能通过定时参数比对等方式提示参数不一样的节点?
容灾方案:分布式数据库的灾备方案该怎么做?两地三中心采用什么方式实现?异构数据库的数据同步方案有哪些?数据迁移方案呢?这些在单节点数据库的情况下有很多成熟并久经考验的方案可以使用。然而在分布式环境下,现在只能说是陪着厂商一起成长。
多租户管理:多租户管理是分布式数据库环境需要解决的重要功能。运维人员需要把相应的产品方案用起来,并且在运维的过程中关注租户的容量和性能需求,并相应调整数据库。
2. 如何管理好分布式数据库
分布式数据库作为新的技术,并不是脱胎于成熟的商业数据库,因此还有很多粗糙的地方。尤其是金融行业的用户,被传统商业数据库“娇生惯养”,首次接触到新生数据库的时候,会有四处碰壁的感觉。但是即便是硬骨头,还是得啃。
控制应用场景:
分布式不是万能的,它是面向特殊场景的数据库产品。只有符合的交易才能往上迁移。如果不想自己麻烦,那就别麻烦分布式数据库了。这个要求运维人员不仅仅在看产品,还需要与业务人员和开发人员紧密合作。要从业务分片的角度去管理数据库。因此使用分布式数据库必须定义一个使用场景规范。
统一管理平台:
分布式数据库的数据分片后,运维人员需要了解数据的整体规划是什么样子的,数据分片规则,复制方案,同步方案等。使用分布式数据库集群的用户可能要轻松一些,因为这些产品可能有相应的产品级解决方案。而采用了分布式中间件的用户,如何还能随时查询和透视数据表的关系,这是需要另寻方案的。不管是何种方式,这些都是分布式数据库运维需要做好的事情。
所以运维人员需要建立一套数据管理平台。在平台里查看和操作分布式数据库集群状态,管理数据库用户、权限、分布规则、配置下发、配置比对、查看日志、分析等各类管理功能。最好也包含多租户管理。
智能监控平台:
引进分布式数据库之后,运维人员需要监控分布式数据库节点状态和各个节点的性能。首先要解决的问题是将新数据库接入到监控告警平台。原先适用于单机数据库的各项监控需要针对集群数据库适配一遍。然后更进一步,运维人员还需要借助智能运维来实现分布式数据库的精细化监控。智能监控平台需要分析发现分布式数据库负载不均衡,节点行为离群等问题,然后智能化展示故障影响链条。智能监控平台还能够做性能容量趋势分析和预测,提前警示性能容量告警。
容量管理:
这个主题单独列出来,确实是因为这个主题太重要了。一定要有办法能够监控数据倾斜问题和负载倾斜问题,并且在管理平台里需要做好负载重分布和数据重分布功能。分布式数据库支持的数据分片方式一般有三种:hash、range和list。如果发生了数据倾斜问题,运维人员需要查看倾斜原因,并采用这现有的几种方式尝试继续打散数据。因此在容量管理这方面,运维人员需要与业务及开发人员紧密沟通,了解数据的业务信息,获取业务增长预期,这样才能做好性能和容量规划。
变更发布:
数据库的参数变更可以通过统一管理平台来实现。但是如果管理平台没有集成的功能,变更内容也一定需要借助自动化发布平台来做。尤其是存在多数据中心容灾的情况下,人为变更是很容易遗漏的。最好是上线DevOps平台,将分布式数据库的变更也集成在平台里。
通过建立这些管理平台和工具,将数据库运维人员从忙于解决各种问题的窘境中释放出来,成长为数据架构师。DBA向前与业务场景对接,向后挑选合适的数据库技术,基于标准化自动化的部署维护方式,为业务稳定运行保驾护航。
四、未来,数据库和数据库运维将去往何方?
我们正处在一个数据库技术大爆炸的时代。这几年NoSQL数据库、NewSQL数据库、时序数据库、图数据库、分布式数据库、超融合数据库相关的技术百花齐放,国产数据库也强势发展起来。那么下一代主流数据库是什么样子呢?未来的运维模式又将发生什么变化?
云数据库:系统上云已经成为这几年的热点。大厂也纷纷推出自己的云数据库。未来云数据库将会成为趋势。数据库服务将进一步标准化输出。无论是私有云还是公有云,用户的数据库使用方式正在发生变化。而分布式数据库和超融合数据库的强劲性能,也适合在云环境提供多租户使用。
细分领域:数据库应用领域也会越来越细分。可能现在我们还是希望有能够面向HTAP场景的全能数据库,但是未来数据库功能将更加分化。尤其是通过数据库云可以轻易申请到主打不同功能的数据库来解决各类业务场景。
智能运维:随着数据库提供云部署云服务,数据库运维一定需要走向智能运维。通过机器学习智能算法来监控系统运行状态,依据数据表现提供决策、自动修复、自动扩容。
最后想象一个场景,用户申请了云数据库,运行一段时间后,智能运维机器人告诉用户数据库最近发生了什么事情,一共发生了几次自动调优,几次自动修复异常等,共节省了多少时间损失。还会基于用户的使用场景,建议用户扩容或者是购买更适合的数据库服务,将有助于提高性能多少百分比等。
以上是笔者认为在不久的将来即将发生的变化,你有什么看法?
【作者】孔再华,IBM认证高级DBA,SAP认证BASIS,具有丰富的数据库环境问题诊断和性能调优的经验。在数据库同城双活,集群,多分区,分布式等项目实施上具有丰富的经验。现任职于中国民生银行科技部,工作致力于数据库同城双活架构建设,数据库分布式架构建设和数据库智能运维(AIOps)方向。对于如何将AI技术运用在运维领域具有浓厚的兴趣和创新热情。
转载请注明:IT运维空间 » 运维技术 » 分布式架构下,传统数据库运维究竟要面对哪些变化?
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值










发表评论