

snapshot(快照)基础原理
snapshot是很多存储系统和数据库系统都支持的功能。一个snapshot是一个全部文件系统、或者某个目录在某一时刻的镜像。实现数据文件镜像最简单粗暴的方式是加锁拷贝(之所以需要加锁,是因为镜像得到的数据必须是某一时刻完全一致的数据),拷贝的这段时间不允许对原数据进行任何形式的更新删除,仅提供只读操作,拷贝完成之后再释放锁。这种方式涉及数据的实际拷贝,数据量大的情况下必然会花费大量时间,长时间的加锁拷贝必然导致客户端长时间不能更新删除,这是生产线上不能容忍的。
snapshot机制并不会拷贝数据,可以理解为它是原数据的一份指针。在HBase这种LSM类型系统结构下是比较容易理解的,我们知道HBase数据文件一旦落到磁盘之后就不再允许更新删除等原地修改操作,如果想更新删除的话可以追加写入新文件(HBase中根本没有更新接口,删除命令也是追加写入)。这种机制下实现某个表的snapshot只需要给当前表的所有文件分别新建一个引用(指针),其他新写入的数据重新创建一个新文件写入即可。如下图所示:
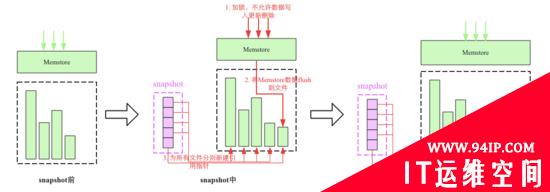
snapshot流程主要涉及3个步骤:
- 加一把全局锁,此时不允许任何的数据写入更新以及删除
- 将Memstore中的缓存数据flush到文件中(可选)
- 为所有HFile文件分别新建引用指针,这些指针元数据就是snapshot
扩展思考:LSM类系统确实比较容易理解,那其他非LSM系统原地更新的存储系统如何实现snapshot呢?
snapshot能实现什么功能?
snapshot是HBase非常核心的一个功能,使用snapshot的不同用法可以实现很多功能,比如:
全量/增量备份:任何数据库都需要有备份的功能来实现数据的高可靠性,snapshot可以非常方便的实现表的在线备份功能,并且对在线业务请求影响非常小。使用备份数据,用户可以在异常发生的情况下快速回滚到指定快照点。增量备份会在全量备份的基础上使用binlog进行周期性的增量备份。
使用场景一:通常情况下,对重要的业务数据,建议至少每天执行一次snapshot来保存数据的快照记录,并且定期清理过期快照,这样如果业务发生重要错误需要回滚的话是可以回滚到之前的一个快照点的。
使用场景二:如果要对集群做重大的升级的话,建议升级前对重要的表执行一次snapshot,一旦升级有任何异常可以快速回滚到升级前。
2. 数据迁移:可以使用ExportSnapshot功能将快照导出到另一个集群,实现数据的迁移
使用场景一:机房在线迁移,通常情况是数据在A机房,因为A机房机位不够或者机架不够需要将整个集群迁移到另一个容量更大的B集群,而且在迁移过程中不能停服。基本迁移思路是先使用snapshot在B集群恢复出一个全量数据,再使用replication技术增量复制A集群的更新数据,等待两个集群数据一致之后将客户端请求重定向到B机房。具体步骤可以
转载请注明:IT运维空间 » 运维技术 » HBase原理 – 分布式系统中Snapshot是怎么玩的?
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-

oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-

Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://94ip.com/zb_users/theme/ydconcise/include/random/1.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值









发表评论